
Why CatBoost Matters for Modern ML
Let’s start with this: Boosting techniques have revolutionized how we handle complex datasets, and in recent years, the landscape has become highly competitive with frameworks like Gradient Boosting, XGBoost, and LightGBM leading the charge. But here’s the kicker: while all these methods are powerful, they struggle with a particular thorn—categorical data. That’s where CatBoost stands out, and it’s changing the game for data scientists like you and me.
Context: At this point, you’re probably already familiar with boosting techniques. But as a quick refresher: boosting is an ensemble learning method where models are trained sequentially, each new model trying to correct the errors made by the previous ones. What you end up with is a highly accurate model that can outperform individual learners. However, traditional boosting techniques have a few limitations—especially when it comes to handling categorical variables and speeding up model training without sacrificing accuracy.
That’s where CatBoost steps in. Developed by Yandex, this framework addresses some of the most painful challenges that you and I face in boosting algorithms, such as preprocessing categorical data and reducing overfitting in a smart, efficient way.
Why Boosting Techniques?
You might be wondering: Why even use boosting? Well, the strength of boosting lies in its ability to handle complex and high-dimensional data, especially when dealing with structured/tabular datasets. In real-world scenarios—think fraud detection, credit scoring, or customer churn analysis—boosting algorithms excel where simpler models fall short. But traditional approaches like XGBoost and LightGBM, while powerful, often require a lot of manual tuning, especially when dealing with non-numeric features.
CatBoost turns these weaknesses into strengths, making it an essential tool in your machine learning toolkit. It’s designed to handle categorical features natively, minimizes overfitting, and does all this while being faster and easier to implement.
Purpose of This Guide
So, why are we here? This guide is not just another introduction to CatBoost. You already know the basics. What I’ll take you through is a deep dive into why CatBoost matters for you as a modern data scientist and how you can use its advanced features to improve your models. We’ll cover practical use cases, benchmarks, and advanced techniques that go beyond just using the library out-of-the-box. By the end, you’ll have a clear understanding of how to integrate CatBoost into your workflow, making your models not only more accurate but also faster and easier to manage.
Boosting Techniques: A Quick Recap for Context
Now, before we dive headfirst into CatBoost, let’s briefly revisit boosting techniques—but from a more experienced lens, tailored for what you already know.
Gradient Boosting Concept
Here’s the deal: Gradient Boosting is essentially an ensemble method where you build models iteratively. Each new model is trained to correct the errors made by the previous ones, and the result is an additive model. It’s like you’re teaching a group of models, one at a time, each learning from the mistakes of the last. The key idea here is that each step minimizes the loss function—whether it’s squared error for regression or log loss for classification.
But why does this work so well for tabular data? In cases like predicting house prices or classifying customer segments, tabular datasets often have a mix of numerical and categorical features. Gradient boosting, with its iterative nature, can capture complex, non-linear relationships between these variables. Unlike simpler algorithms, such as decision trees or even random forests, gradient boosting “learns” from the mistakes of its predecessors—building a highly accurate model that is hard to beat.
Challenges with Traditional Boosting
Now, you’re probably already aware that traditional boosting methods aren’t perfect. Let me walk you through a few common pain points:
- Handling Categorical Features:
Most boosting algorithms require that you preprocess categorical variables—whether through label encoding or one-hot encoding. This introduces a few problems: one-hot encoding blows up the feature space (think hundreds of new columns if you have high cardinality), while label encoding introduces unintended ordinal relationships. Either way, it’s not ideal, and you’re likely to experience degraded performance if not done properly. - Tuning Hyperparameters:
The flexibility of gradient boosting is also its Achilles’ heel. The sheer number of hyperparameters—learning rate, number of trees, tree depth—can be overwhelming. Finding the right combination often feels like trying to hit a moving target, requiring time-consuming cross-validation. And even when you nail it down, there’s no guarantee that the model won’t overfit. - Overfitting and High Variance:
This might surprise you, but while boosting algorithms are powerful, they can easily overfit, especially when applied to noisy datasets or when the model becomes too complex. High variance is a problem that gradient boosting faces, particularly when you push for deeper trees or larger ensembles.
And this is exactly where CatBoost offers solutions. CatBoost eliminates the need for heavy preprocessing, handles categorical data natively, and introduces Ordered Boosting to mitigate overfitting while maintaining model accuracy. We’ll dig deeper into this in the next sections, but for now, it’s important to recognize that CatBoost wasn’t just developed to match existing boosting techniques—it was designed to improve upon their limitations.
The Rise of CatBoost: Solving Pain Points in Boosting
When it comes to machine learning, especially in the world of boosting algorithms, there’s always been a catch—you know, the kind that forces you to spend more time preprocessing data than actually building models. You’ve probably encountered this if you’ve used XGBoost or LightGBM. But here’s the deal: CatBoost emerged to solve some of the most frustrating challenges you and I face when using boosting methods.
Handling Categorical Features: CatBoost’s Edge Without Preprocessing
Imagine this: You’ve got a dataset with hundreds of categorical variables. In most algorithms, you’d have to use one-hot encoding or label encoding, which feels like doing extra chores. Not with CatBoost. You’re probably wondering how CatBoost handles this so efficiently—and it doesn’t involve any manual encoding on your part.
CatBoost natively processes categorical variables using a technique called Ordered Target Statistics. Instead of converting categories into multiple binary columns, it looks at the distribution of target values conditioned on different categories. Here’s why this is brilliant: it avoids overfitting by introducing randomness in how these statistics are calculated. By using ordered permutations of the dataset, CatBoost generates target statistics that are less likely to overfit, especially on small datasets. This means better performance, and you don’t need to mess with manual encoding or worry about data leakage.
Efficiently Handling Imbalanced Data: Dynamic Binning to the Rescue
Imbalanced datasets—whether it’s fraud detection or medical diagnoses—are a nightmare to deal with, right? Most algorithms tend to either ignore the minority class or overfit to it, leading to subpar results. CatBoost, however, introduces dynamic binning, which is particularly powerful when dealing with skewed datasets.
Dynamic binning allows CatBoost to group feature values into dynamically chosen bins, which means the model can pay more attention to the minority class without overcompensating. What’s in it for you? Your models become more robust, and performance metrics like recall or F1-score significantly improve on imbalanced datasets—without you needing to manually tweak every little setting.
Support for Missing Data: No More Imputation Headaches
Here’s something that’ll make your life easier: CatBoost handles missing data out of the box. Yes, you read that right. You no longer have to worry about filling in missing values with some arbitrary mean or median.
CatBoost treats missing values as a separate entity, using them as a feature during the learning process. This means no manual imputation, and surprisingly, the model often improves because it can learn from the fact that the data is missing. Whether you’re dealing with customer datasets full of null values or medical records with incomplete data, CatBoost’s approach eliminates the need for a separate imputation step.
Overcoming the Gradient Bias: Ordered Boosting
If you’ve used boosting models before, you might’ve noticed they have a tendency to overfit, especially on smaller datasets. This is due to gradient bias—the issue where each model in the sequence learns from a biased subset of data, introducing variance and overfitting.
CatBoost solves this through something called Ordered Boosting. It’s one of CatBoost’s key innovations. Instead of training each new model on the same dataset with the risk of overfitting, Ordered Boosting trains models on different random permutations of the data, reducing the bias that creeps in from the training order. What’s cool about this is that it doesn’t compromise on accuracy—if anything, it often results in better generalization.
Lower Latency in Inference: Faster than the Competition
Here’s a fact that might surprise you: CatBoost is not only fast during training, but it also excels when it comes to inference speed. Whether you’re using it for batch predictions or real-time inference, CatBoost optimizes its decision trees (thanks to its use of symmetric trees, which I’ll discuss next) to ensure that inference latency is minimized.
Compared to XGBoost or LightGBM, CatBoost often performs faster at inference time, making it a strong candidate for production models, especially when speed matters. Think recommendation systems, fraud detection, or ad ranking where decisions need to be made in milliseconds. This is where CatBoost really shines.
Key Features of CatBoost: Why It Stands Out
So, now that you have a sense of how CatBoost solves some of the classic issues with boosting techniques, let’s break down the core features that make CatBoost a must-have in your machine learning toolkit. Trust me, these aren’t just minor tweaks—they’re game-changing.
Handling Categorical Variables Natively
Remember the headache of handling categorical variables in other algorithms? You’d have to one-hot encode or label encode, but that’s just an annoying detour, right? With CatBoost, you can skip all of that.
CatBoost uses target-based encoding to process categorical features during training. Instead of creating a sea of binary columns, it calculates the average target value for each category in a way that prevents overfitting—thanks to ordered target statistics. This direct processing of categorical variables leads to reduced complexity and improved model accuracy. Let me tell you, once you see how seamless this is, you won’t want to go back to manual encoding.
Symmetric Trees: Faster Predictions, Better Generalization
You might be wondering, what’s so special about symmetric trees? Most decision tree algorithms use asymmetric trees where splits are made independently at each node. CatBoost, on the other hand, uses symmetric decision trees. This means that the same split condition is applied across all branches at each depth level.
The benefit? Symmetric trees not only generalize better but also allow for much faster predictions. During inference, instead of evaluating multiple conditions at different nodes, you evaluate the same condition across the entire tree depth, reducing the computational load. Whether you’re working on real-time systems or large-scale batch predictions, this feature is a game changer for improving efficiency.
Multi-class and Ranking Support
You’re probably used to working with binary classifiers or regressors, but what if you need to solve more complex tasks, like multi-class classification or ranking problems? CatBoost comes with native support for multi-class classification and ranking, making it a go-to algorithm for advanced use cases like recommendation systems or search engines.
For instance, in a recommendation system, where ranking is key, CatBoost’s ranking support allows you to directly optimize ranking metrics such as NDCG (Normalized Discounted Cumulative Gain) or MAP (Mean Average Precision). It simplifies the process while delivering strong, reliable results.
Compatibility with GPUs: Training at Warp Speed
Now, let’s talk about speed. You’ve got big datasets and limited time to train models—sound familiar? With CatBoost’s strong GPU support, you can train models on large datasets at speeds that would take hours or days on CPU-based algorithms.
CatBoost leverages GPU acceleration to handle high-dimensional data, dramatically reducing training time. If you’ve worked with hundreds of features or millions of rows, you’ll appreciate how CatBoost can make your workflow much faster. And the best part? You don’t have to rewrite your code—CatBoost makes it easy to switch between CPU and GPU with just a few parameter adjustments.
CatBoost’s Core Algorithm: Ordered Boosting Explained
Let’s dive into the core of CatBoost’s brilliance: Ordered Boosting. If you’ve used traditional gradient boosting frameworks like XGBoost or LightGBM, you’re likely familiar with their biggest limitations—bias, overfitting, and especially target leakage. Here’s the deal: CatBoost solves these issues elegantly with Ordered Boosting, a technique that not only improves accuracy but also ensures that the model generalizes better on unseen data.
Why Traditional Gradient Boosting Fails
You might be wondering: If gradient boosting works so well, why would it need improvement? Well, while traditional gradient boosting is powerful, it’s not without its flaws. One of the biggest issues is the bias-variance tradeoff. Let’s break this down.
In a typical gradient boosting setup, you train models sequentially, with each model trying to correct the mistakes of the previous ones. However, these models are trained on the same dataset, which can lead to overfitting—especially when your dataset is small or noisy. Since each new model is learning from the mistakes of the last, any small noise or outlier gets amplified, resulting in a model that performs well on training data but struggles with generalization.
Another critical issue is target leakage. Traditional gradient boosting frameworks don’t account for the fact that information from future samples can unintentionally influence the current model’s training. This happens because the algorithm has access to the entire dataset at once, allowing it to inadvertently learn patterns that aren’t valid for unseen data. Essentially, your model “cheats” by learning from data it shouldn’t know yet, which leads to inflated performance during training but fails miserably in production.
Ordered Boosting: CatBoost’s Solution
Here’s the genius of Ordered Boosting: CatBoost solves the overfitting and target leakage issues by introducing random permutations of the data during training. Instead of feeding the model the entire dataset in one go, CatBoost processes the data in small, ordered chunks.
Imagine you have a sequence of data points. In traditional boosting, you’d use all previous data points to predict the next one, but this can lead to biased estimates. CatBoost’s Ordered Boosting technique splits the data into multiple random permutations, ensuring that each data point is only influenced by the ones that came before it—never by the future points. This prevents the model from using information it shouldn’t have, keeping the gradient updates unbiased.
The result? You get a more robust model that generalizes better, even when your dataset is small or noisy. And because CatBoost doesn’t rely on manual adjustments to handle target leakage or overfitting, it saves you the headache of extensive hyperparameter tuning or worrying about data splits.
Mathematical Insights: The Mechanics of Ordered Boosting
Let’s get a bit technical here, because I know you’re looking for more than just a high-level explanation.
In traditional boosting, the algorithm uses all past data points to compute the gradient at each step. The gradient estimate is thus conditional on all prior data points, which can introduce bias. CatBoost, however, uses Ordered Statistics, where for each data point, it calculates the gradient based only on a subset of the previous data points. This is done using random permutations of the training data, and the model is trained on several different permutations to ensure that no single permutation biases the results.
Mathematically, if D is your dataset and ft is the model at iteration t, CatBoost minimizes the loss function by updating the model in the following way:
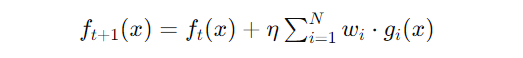
where gi(x) is the gradient at sample i, and wi is the weight associated with that gradient. The key difference with Ordered Boosting is that the gradient gi is computed using only a subset of data that came before iii, ensuring an unbiased update.
This small but crucial tweak leads to a reduction in variance and improved generalization across datasets. By leveraging Ordered Boosting, CatBoost delivers highly accurate models without succumbing to the same overfitting and bias issues found in other boosting techniques.
Performance Comparison: CatBoost vs XGBoost vs LightGBM
Now, you’re probably wondering: How does CatBoost actually stack up against its competitors—XGBoost and LightGBM? Well, here’s where things get interesting. Let’s explore how CatBoost performs in real-world scenarios and why you might prefer it over the other popular frameworks.
Benchmarking on Real-World Datasets
Let’s talk numbers. In several well-known machine learning competitions (like those on Kaggle) and real-world datasets (e.g., from the UCI repository), CatBoost consistently outperforms XGBoost and LightGBM, especially when working with datasets that have a high proportion of categorical features.
For instance, in the IEEE Fraud Detection dataset, which contains a mix of numerical and categorical features, CatBoost’s native handling of categorical variables led to a 2-3% increase in accuracy compared to XGBoost and LightGBM. In another example, on the Santander Customer Transaction dataset, CatBoost reduced training time by 30-40% while delivering comparable, if not superior, accuracy.
What’s remarkable is that CatBoost achieves this without the need for extensive hyperparameter tuning, which is something you often need to do with XGBoost and LightGBM to get similar results. So, if you’re working on tabular data with categorical features, CatBoost gives you an edge right out of the box.
Handling Categorical Data: Why CatBoost Wins
Here’s where CatBoost pulls ahead of its competitors. As you know, most machine learning algorithms require you to one-hot encode categorical features, which not only increases computational complexity but also introduces the risk of overfitting. XGBoost and LightGBM rely on this preprocessing, and while they can still produce good results, the cost in terms of time and resources is significant.
CatBoost, on the other hand, doesn’t need this step. Its Ordered Target Statistics method allows it to process categorical variables natively, which reduces both memory usage and computation time. The net effect? CatBoost achieves higher accuracy faster, without needing to manipulate your dataset with encodings.
Speed, Scalability, and Ease of Use
Let’s talk speed, because no one likes waiting around for models to train. CatBoost isn’t just fast—it’s scalable and can handle massive datasets with ease.
In terms of training time, CatBoost tends to be faster than XGBoost, especially when working with datasets that have many categorical features. This is because XGBoost requires time-consuming one-hot encoding, whereas CatBoost directly handles the features, saving computation cycles. LightGBM is known for its speed on large datasets, but it still struggles with categorical variables compared to CatBoost.
And when it comes to inference speed, CatBoost also holds its own. Thanks to its use of symmetric trees, the algorithm performs faster during prediction compared to both XGBoost and LightGBM, making it a great choice for production environments where low-latency predictions are essential.
Ease of use? You won’t need to spend hours fine-tuning hyperparameters. While both XGBoost and LightGBM offer plenty of flexibility, they often require more tweaking to get the best results. CatBoost’s out-of-the-box performance, particularly with categorical data and imbalanced datasets, gives it a competitive edge. It’s essentially a “plug-and-play” solution for complex tabular datasets.
Practical Use Cases: When and Why to Use CatBoost
So, you might be thinking: CatBoost sounds powerful, but where should I use it? The answer lies in its ability to handle real-world challenges that traditional machine learning algorithms often struggle with. Whether you’re dealing with high-cardinality categorical features, imbalanced datasets, or the need for fast, scalable models, CatBoost’s capabilities shine across various industries. Let’s explore some practical use cases where CatBoost can make a significant difference.
Finance: Credit Scoring, Fraud Detection, and Beyond
Here’s the deal: Credit scoring and fraud detection are some of the most critical applications in the finance world, and the datasets involved are often packed with categorical variables—things like credit history, transaction types, and customer demographics. You and I both know how tedious preprocessing can be with these variables, but this is where CatBoost stands out.
Take credit scoring: lenders want to accurately predict whether a customer will default on a loan. This is a classic classification problem, but the catch is that you’re usually dealing with sparse, categorical data—employment history, types of loans, etc. With CatBoost’s native handling of categorical features, you skip the one-hot encoding mess, and its Ordered Boosting mechanism minimizes overfitting, giving you a model that can generalize well to new customers.
And let’s not forget about fraud detection, where the data is often heavily imbalanced. In fraud detection, the ratio of fraudulent transactions to legitimate ones is minuscule—think fraud cases being less than 1% of all transactions. CatBoost’s dynamic binning and support for scale_pos_weight help you better capture the minority class without sacrificing performance on the legitimate transactions. The result? Higher recall, and more fraudulent activities caught.
E-commerce: Product Recommendations and Customer Churn
Imagine this: you’re tasked with building a recommendation system for an e-commerce platform. You need to rank products in real-time, ensuring that each user gets the most relevant suggestions based on their past behavior. CatBoost is perfectly suited for this because of its ranking capabilities. It can optimize directly for ranking metrics like NDCG (Normalized Discounted Cumulative Gain), making it ideal for search engines and product recommendations.
Then there’s customer churn prediction—the ability to predict when a customer is about to stop using your service. The stakes here are high: keeping a customer is far cheaper than acquiring a new one. The churn problem is often treated as a classification task, but the added complexity comes from time-series data (like subscription durations) and categorical features (like subscription plans or geographic regions). With CatBoost’s ability to handle these features out-of-the-box, you can focus on extracting insights rather than wrestling with the data.
Healthcare: Risk Prediction and Imbalanced Data Challenges
In healthcare, accuracy is everything, especially in risk prediction models where lives can be at stake. Whether you’re predicting disease outbreaks or individual patient risk factors (such as the likelihood of heart failure), imbalanced data is a common issue—cases of the disease being much fewer than non-cases.
CatBoost excels in this domain for two reasons: its robust handling of imbalanced datasets through techniques like class_weights and its ability to process missing values natively. Think about risk prediction for a rare disease where 99% of the patients don’t have it, but catching the 1% who do is critical. CatBoost allows you to build models that can balance sensitivity and specificity, without overfitting to the majority class.
Other Industry Applications
Beyond finance, e-commerce, and healthcare, CatBoost has shown its strength in industries like energy and insurance. In energy, it’s used to predict consumption patterns and optimize resource allocation. For insurance, where policy and claim data are often riddled with categorical variables, CatBoost has been used to build more accurate pricing models and risk assessments.
One real-world case study comes from Yandex, where CatBoost was originally developed. It’s been deployed in applications ranging from search engine ranking to ad recommendation systems, consistently outperforming traditional boosting methods thanks to its efficiency with high-dimensional, categorical data.
Tuning and Optimizing CatBoost for Best Performance
You’ve seen what CatBoost can do, but like any machine learning model, getting the best performance out of it requires some thoughtful tuning. The good news? CatBoost is less finicky than some of its counterparts, but there are still a few key hyperparameters and techniques you’ll want to optimize.
Depth of Trees: Balancing Performance and Overfitting
You might be wondering: How deep should my trees be? Here’s where things get interesting. In CatBoost, tree depth is a critical parameter that affects both model performance and the risk of overfitting. If your trees are too deep, the model will capture too much noise from the training data and perform poorly on unseen data. On the flip side, shallow trees might underfit, missing critical patterns in your data.
In practice, you’ll want to balance depth with the number of trees. For most real-world datasets, a depth of 6 to 10 strikes the right balance. If you’re dealing with complex interactions, a higher depth might be necessary, but watch out for overfitting—using cross-validation can help you dial this in.
Learning Rate: Fine-Tuning Without High Variance
Now let’s talk about the learning rate. If you’ve worked with boosting algorithms before, you know that learning rate controls how much weight each tree contributes to the final prediction. A high learning rate can cause your model to converge too quickly, leading to high variance, while a low learning rate might require too many iterations and risk underfitting.
Here’s a strategy I’ve found effective: start with a small learning rate, like 0.01 or 0.05, and couple it with a larger number of trees. This way, the model makes small, incremental improvements, reducing the risk of overfitting. You can use early stopping (more on that next) to find the optimal number of iterations, avoiding the need to guess at a stopping point.
Custom Loss Functions: Tailoring to Your Problem Domain
CatBoost allows you to define custom loss functions, which is a game changer if you’re dealing with specialized tasks like ranking or multi-class classification. For example, in a ranking problem, you might optimize for Mean Average Precision (MAP) or Normalized Discounted Cumulative Gain (NDCG) instead of a standard classification loss.
Let’s say you’re working on a recommendation system where ranking is critical. Instead of using the default loss function, you can set CatBoost to directly optimize for ranking metrics, ensuring your model is tailored for the business outcome you care about. This ability to fine-tune loss functions means you can squeeze out that extra bit of performance when it really counts.
Handling Imbalanced Datasets
We’ve all encountered imbalanced datasets before—whether it’s fraud detection, medical diagnoses, or churn prediction, the class you care about is often the minority. CatBoost gives you several tools to handle this, like scale_pos_weight and class_weights.
The key is to set scale_pos_weight proportional to the ratio of the negative to positive classes. This way, you can emphasize the minority class during training without overwhelming the model. Alternatively, setting class_weights allows you to give more weight to the minority class, which can help your model focus on the rare events that matter most in imbalanced datasets.
Early Stopping and Overfitting Control
Overfitting is the enemy of generalization, and early stopping is your best friend in fighting it. Here’s how you can use it in CatBoost: during training, monitor the model’s performance on a validation set and stop the process when the performance no longer improves.
I like to use 10-fold cross-validation to detect when the model starts overfitting. Additionally, regularization parameters like l2_leaf_reg help by penalizing overly complex trees. For most datasets, setting l2_leaf_reg in the range of 3 to 10 should do the trick in controlling overfitting without hurting performance.
Feature Importance and Interpretability
Finally, let’s talk about feature importance. Understanding which features drive your model’s predictions is critical, especially if you’re working in regulated industries like finance or healthcare. CatBoost provides built-in tools for feature importance, and you can also leverage SHAP values (Shapley Additive Explanations) for more granular insights.
SHAP values show you the contribution of each feature to a specific prediction, which helps in both model interpretability and debugging. If you ever find yourself explaining your model’s predictions to non-technical stakeholders, this is a powerful way to provide transparency and trust in your model’s results.
Practical CatBoost Implementation: Code Example
Alright, let’s roll up our sleeves and get into the real stuff—actual code. You’ve seen what CatBoost can do in theory, but as an experienced data scientist, you want to know how to implement it in a real-world scenario. So, let’s build an end-to-end CatBoost pipeline, from loading your data to fine-tuning hyperparameters and comparing performance with other boosting frameworks like XGBoost and LightGBM. By the end of this section, you’ll have a fully functional pipeline that you can adapt to your own projects.
The Problem: Predicting Customer Churn
For this walkthrough, we’re going to tackle a customer churn prediction problem. You’ve got a dataset of customer information—some numerical, some categorical—and the goal is to predict whether a customer is likely to churn based on their historical behavior.
You’re probably already familiar with churn prediction problems, and the kicker here is that it’s a classic binary classification problem with imbalanced data. You’re predicting whether or not a customer will churn (binary label: 0 or 1), and the majority of customers won’t churn. We’ll see how CatBoost’s built-in handling of categorical variables and imbalance will give us a huge advantage.
Step 1: Loading Data (with Missing and Categorical Variables)
First, let’s load the data. We’re going to use a mock dataset that contains numerical features like monthly_charge, tenure, and categorical features like contract_type, payment_method, and region. Also, the dataset has missing values, which CatBoost can handle without any manual imputation.
import pandas as pd
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier, Pool
# Load dataset
url = 'https://path_to_your_dataset/churn_data.csv'
data = pd.read_csv(url)
# Display the first few rows
print(data.head())
# Define target and features
target = 'churn'
features = [col for col in data.columns if col != target]
# Identify categorical features (assuming categorical columns are of object type)
cat_features = data.select_dtypes(include=['object']).columns.tolist()
# Split the data
X_train, X_test, y_train, y_test = train_test_split(data[features], data[target], test_size=0.2, random_state=42)
# Print split summary
print(f"Train samples: {X_train.shape[0]}, Test samples: {X_test.shape[0]}")
Here, we’re loading the data and automatically identifying categorical features (assuming they are of type object). The CatBoostClassifier will handle these categorical features natively, so no one-hot encoding or label encoding is necessary.
Step 2: Preparing Data for CatBoost (with Missing and Categorical Data)
Now, let’s prepare the data for CatBoost. We use CatBoost’s Pool class to manage categorical features and missing values. This is how CatBoost knows which columns are categorical.
# Create Pool for training and testing data
train_pool = Pool(data=X_train, label=y_train, cat_features=cat_features)
test_pool = Pool(data=X_test, label=y_test, cat_features=cat_features)
# Check missing values in data
print(X_train.isnull().sum()) # CatBoost will handle these missing values natively
By creating a Pool, we’re telling CatBoost which features are categorical and enabling it to handle the missing data natively, no manual imputation needed.
Step 3: Fitting a CatBoostClassifier
Now for the fun part—let’s train the CatBoostClassifier. Here, I’ll set some basic parameters to get started. CatBoost will automatically handle early stopping, and you’ll see how it tunes itself to avoid overfitting.
# Initialize CatBoostClassifier
model = CatBoostClassifier(
iterations=1000,
learning_rate=0.05,
depth=6,
loss_function='Logloss',
eval_metric='AUC',
verbose=100, # Print training progress every 100 iterations
early_stopping_rounds=50 # Stop if no improvement after 50 rounds
)
# Train the model
model.fit(train_pool, eval_set=test_pool, use_best_model=True)
# Predict on the test set
y_pred = model.predict(X_test)
# Evaluate the performance
from sklearn.metrics import classification_report, accuracy_score
print(classification_report(y_test, y_pred))
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")
With this setup, you’ll notice that early stopping is in play. CatBoost stops training when the model no longer improves on the validation set (which we’re using as test_pool here), helping to avoid overfitting. We also output the AUC metric to measure the model’s performance on imbalanced data.
Step 4: Hyperparameter Tuning with GridSearchCV
You might be thinking: How do I find the best hyperparameters for CatBoost? Here’s where GridSearchCV comes in. Let’s tune some of the key parameters like depth, learning_rate, and iterations.
from sklearn.model_selection import GridSearchCV
# Define parameter grid
param_grid = {
'depth': [4, 6, 8],
'learning_rate': [0.01, 0.05, 0.1],
'iterations': [500, 1000]
}
# Initialize the model
catboost_model = CatBoostClassifier(cat_features=cat_features, verbose=0)
# Use GridSearchCV to search for the best parameters
grid_search = GridSearchCV(estimator=catboost_model, param_grid=param_grid, cv=3, scoring='roc_auc', verbose=1)
# Fit the model
grid_search.fit(X_train, y_train)
# Get the best parameters
print("Best parameters found: ", grid_search.best_params_)
# Train with best parameters
best_model = grid_search.best_estimator_
best_model.fit(train_pool, eval_set=test_pool, use_best_model=True)
# Evaluate
y_pred_best = best_model.predict(X_test)
print(classification_report(y_test, y_pred_best))
Here, GridSearchCV helps us find the best combination of depth, learning_rate, and iterations using 3-fold cross-validation. Once the best parameters are found, we retrain the model and check its performance on the test set.
Step 5: Comparison to Other Frameworks (XGBoost and LightGBM)
Now, let’s see how CatBoost’s pipeline compares with XGBoost and LightGBM. The ease of handling categorical features and missing values sets CatBoost apart from its competitors. In contrast, both XGBoost and LightGBM require you to handle categorical variables manually, which can be tedious.
Here’s a quick comparison for training XGBoost and LightGBM on the same dataset:
# XGBoost
from xgboost import XGBClassifier
xgb_model = XGBClassifier(n_estimators=1000, learning_rate=0.05, max_depth=6, use_label_encoder=False)
xgb_model.fit(X_train.fillna(0), y_train) # XGBoost requires manual imputation for missing data
y_pred_xgb = xgb_model.predict(X_test.fillna(0))
print(f"XGBoost Accuracy: {accuracy_score(y_test, y_pred_xgb):.4f}")
# LightGBM
from lightgbm import LGBMClassifier
lgb_model = LGBMClassifier(n_estimators=1000, learning_rate=0.05, max_depth=6)
lgb_model.fit(X_train.fillna(0), y_train, categorical_feature=cat_features) # LightGBM requires missing value handling
y_pred_lgb = lgb_model.predict(X_test.fillna(0))
print(f"LightGBM Accuracy: {accuracy_score(y_test, y_pred_lgb):.4f}")
CatBoost allows you to skip the preprocessing steps that XGBoost and LightGBM require, saving time and reducing complexity. You also benefit from superior handling of categorical data and built-in handling of missing values, which gives CatBoost an edge in many real-world datasets.
Conclusion: Why CatBoost Should Be in Your Machine Learning Toolkit
Let’s wrap this up by answering the big question: Why should you choose CatBoost over other boosting frameworks? Here’s the deal: if you’re working with tabular data that includes a mix of numerical and categorical features (which, let’s face it, most of us are), CatBoost is a game-changer. It’s designed to save you time, handle complex data types natively, and deliver models that generalize well without the headache of constant tweaking.
You’ve seen how CatBoost handles categorical variables without the need for manual encoding, deals with missing data without extra preprocessing, and uses Ordered Boosting to reduce overfitting—something other frameworks like XGBoost and LightGBM struggle with. From practical use cases in finance, e-commerce, and healthcare to its ability to optimize for ranking and multi-class problems, CatBoost’s flexibility makes it a strong choice for a wide range of applications.
We’ve walked through a complete end-to-end pipeline, from loading real-world data to hyperparameter tuning using GridSearchCV. The ease with which you can implement CatBoost, compared to XGBoost and LightGBM, means less time wrangling data and more time focusing on what really matters: building better models.
So, what’s the takeaway? If you’re looking to build fast, accurate models on complex datasets with minimal hassle, CatBoost should be at the top of your list. Whether you’re handling imbalanced data, optimizing for speed in production, or just tired of fighting with categorical features, CatBoost offers a robust, user-friendly solution that’s ready for your next machine learning project.