
Let’s start by addressing the elephant in the room: CNNs have served us well, but they’re not without their shortcomings. You’ve probably noticed how CNNs are exceptional at recognizing patterns and objects in images, but there’s a catch. When it comes to understanding the spatial relationships between these objects or their parts, CNNs fall short. For instance, consider how a CNN can recognize a face, but if you rearrange the nose, eyes, and mouth, the network might still think it’s seeing a face. That’s a problem!
Here’s the deal: CNNs lack equivariance—the ability to understand that objects and their parts maintain certain spatial relationships even when rotated, scaled, or transformed. This limitation comes from how CNNs use pooling layers, which essentially summarize local features, but in doing so, they lose vital spatial information. Max pooling is like compressing a picture into a thumbnail; you get the essence, but the details are gone.
CNNs also struggle with rotational and spatial transformations. If an object in an image is tilted or rotated slightly, a CNN might misclassify it. This inefficiency means CNNs require massive amounts of data with various orientations and positions just to perform well, which, let’s face it, is hardly an elegant solution.
The Need for a New Architecture
Enter Capsule Networks, Hinton’s revolutionary idea designed to address these exact issues. Capsule Networks aim to mimic the way the human brain understands visual data—through hierarchical structures that grasp part-whole relationships intuitively. Think about how you can recognize a car, even when it’s flipped, partially hidden, or viewed from an odd angle. Capsule Networks seek to bring this level of understanding to machine learning.
Capsules are designed to preserve the spatial hierarchy within images, meaning they know not only what an object is, but how it’s positioned in space. This concept is critical if we want models that don’t just memorize patterns but genuinely understand the composition of images, much like humans do.
Capsule Networks – A Conceptual Overview
What Are Capsules?
At the heart of Capsule Networks lies the idea of capsules. Think of a capsule as a small collection of neurons, but instead of outputting a single value (like in CNNs), they output a vector. Why does this matter? Well, each capsule isn’t just telling you that a feature is present; it’s also telling you how that feature is positioned—like its orientation, size, and position. You can think of it like this: a neuron in a CNN tells you, “I see an edge,” while a capsule tells you, “I see an edge, and it’s at a 45-degree angle in the top-left corner.” That’s a game-changer.
Capsules encode both the presence of an object and its properties, which makes them more powerful at recognizing objects in a variety of orientations or perspectives. Imagine the capsules as your expert visual detectives—they aren’t just identifying evidence but also describing the scene in detail.
Active vs. Inactive Capsules
Here’s an interesting twist: not all capsules are active at the same time. When a capsule is active, it’s essentially saying, “I’ve found something!”—meaning it has detected a specific feature of an object. Conversely, inactive capsules remain silent, signaling that they haven’t found anything relevant. This active/inactive dynamic is critical because it allows the network to focus on the most important details in the data, filtering out irrelevant noise. It’s like your brain ignoring distractions and focusing on what matters most.
Dynamic Routing Between Capsules
Now, let’s dive into one of the most fascinating aspects of Capsule Networks: dynamic routing. You might be wondering, “How does this differ from the typical max pooling in CNNs?” Well, max pooling throws away a lot of valuable information to simplify things, whereas dynamic routing keeps this information by figuring out which capsules should be “talking” to each other.
Here’s how it works: capsules at one layer don’t just pass their output to every capsule in the next layer. Instead, they use an algorithm to determine which higher-level capsule should receive the information, based on how much they “agree” on the detected object’s properties. It’s like a democratic vote—capsules decide which ones are the best fit to pass their knowledge to the next level, reinforcing the most consistent and meaningful relationships between features.
Dynamic routing ensures that spatial hierarchies and part-whole relationships are preserved throughout the network, allowing Capsule Networks to form a much richer understanding of the data. This is a critical improvement over CNNs, which lose spatial details during pooling.
The Architecture of Capsule Networks
Layer-by-Layer Breakdown
Let’s break down the architecture of Capsule Networks from the ground up. If you’ve worked with CNNs, you’re already familiar with the concept of extracting features like edges and textures in the initial layers. In Capsule Networks, this is where Primary Capsules come into play. These capsules are akin to the early layers in CNNs, but instead of scalar outputs, they’re focused on capturing simple features—edges, textures, and basic shapes—using vectors that encode the presence of features as well as their properties, like orientation and location.
You might be thinking, “Okay, simple features are great, but how do we get to the full object understanding?” That’s where Higher-Level Capsules step in. These capsules work similarly to deeper CNN layers but with an important twist—they capture more complex features and combinations of parts. Imagine a car: the Primary Capsules detect wheels, windows, and edges, while the Higher-Level Capsules understand how those components come together to form a car, even if the wheels are slightly rotated or the car is viewed from a different angle. This hierarchy allows Capsule Networks to maintain a more comprehensive understanding of objects in the data.
Now, here’s where things get really interesting: Understanding the Capsules’ Vectors. In CNNs, each neuron outputs a scalar, which simply tells you whether a feature is present. But capsules output vectors, not scalars. Why? Because a vector can encode not just whether a feature exists, but also how that feature is oriented in space. For instance, a capsule might say, “I see a face, and it’s tilted 30 degrees to the left.” This shift from scalars to vectors is crucial because it allows the network to preserve pose information, enabling more accurate object recognition across varying perspectives.
So, in essence, Capsule Networks create a robust, hierarchical representation of objects, where Primary Capsules capture low-level features, and Higher-Level Capsules combine those features to understand complex objects in detail. This layered approach is what gives Capsule Networks their edge over traditional CNNs.
Dynamic Routing Algorithm in Depth
Now let’s dive deeper into the magic of Capsule Networks: the Dynamic Routing Algorithm. If you’re familiar with CNNs, you know how max pooling can strip away important information to reduce dimensionality. But Capsule Networks? They do something radically different. Instead of throwing information away, they use dynamic routing to ensure that only the most relevant information is passed from one layer to the next.
Mathematical Formulation
At the heart of this dynamic routing process lies a simple but powerful mechanism: routing by agreement. Here’s how it works mathematically. Suppose you have a capsule iii in a lower layer that outputs a prediction vector ui∣j for each higher-layer capsule j. The routing coefficients cijc_{ij}cij decide how much influence capsule iii’s output has on capsule j. The goal is to adjust these coefficients so that capsules agreeing on the properties of an object reinforce each other.
To get a bit more technical, the coupling coefficient cij is determined through a softmax function, which ensures that all the coefficients for a capsule iii sum to 1. The softmax function ensures that more weight is given to the higher-level capsules that agree with the predictions of the lower-level capsules. The overall output of capsule j is then the weighted sum of all the lower-level capsule predictions:
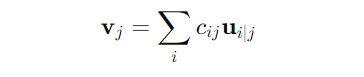
This iterative process is where the “dynamic” part comes in. As routing iterations progress, the coefficients cij are updated, effectively making sure that capsules routing correct information get stronger, while irrelevant ones get weaker.
Backpropagation and Routing Iterations
You might be wondering, “How does this fit into the training process?” Capsule Networks still use backpropagation, but with a twist. During each forward pass, the dynamic routing is performed iteratively, refining the routing coefficients based on agreement between capsules. Then, during backpropagation, the gradients adjust the internal weights of the capsules as well as the routing coefficients. The routing mechanism dynamically adjusts which capsule contributes to the next layer based on how much it “agrees” with the higher-layer capsules.
Now, what makes this different from backprop in CNNs? In a CNN, the pooling and convolution operations are static. You can think of CNNs as having a rigid pipeline that doesn’t adapt its internal routing of information, while Capsule Networks are constantly adapting the routing based on the data at each iteration. This creates more flexibility in how information is passed through the network, making it better at capturing complex spatial relationships.
Comparison to Traditional CNN Backpropagation
Here’s where the difference becomes stark: in CNNs, the backpropagation focuses purely on learning the weights for each neuron in the convolutional layers. The transformations that CNNs learn are fixed once the weights are trained. In Capsule Networks, the transformation matrices between capsules are dynamic, meaning that the transformations are learned and adjusted throughout the routing process. Essentially, Capsule Networks are learning how objects can transform in space, while CNNs are simply learning how to detect fixed patterns.
This ability to model transformations dynamically is what makes Capsule Networks better suited for tasks where objects can appear in various orientations or have complex spatial relationships. Capsule Networks don’t just learn “what” is in an image; they learn “how” that object is arranged in space, which is key to improving object recognition.
Why Capsule Networks Over CNNs?
Pose Estimation and Spatial Relationships
Let’s start with one of the most critical advantages of Capsule Networks: pose estimation and spatial relationships. You’ve probably noticed how CNNs can tell you what is in an image, but they don’t do a great job of figuring out where it is or how it’s positioned. Here’s the deal: Capsule Networks go beyond simple classification by encoding both what the object is and how it is arranged in space.
Picture this—you’re looking at an image of a chair. If that chair is rotated or viewed from a different angle, a CNN might struggle to recognize it unless it’s been trained on thousands of examples of chairs in every possible orientation. Capsule Networks? They handle this more elegantly. The capsules store information about the pose, orientation, and scale of objects in the form of vectors. This means that even if the chair is flipped upside down or rotated 45 degrees, the Capsule Network can still identify it. It knows, for example, that the legs and backrest are part of a chair and not random components.
In simpler terms, CNNs are like recognizing faces by memorizing a bunch of selfies, while Capsule Networks are like learning the structure of a face, so they can still recognize you even when you’re not facing straight at the camera.
Robustness to Affine Transformations
You might be wondering, “What about transformations like rotation or scaling?” CNNs have always struggled with affine transformations, where objects change position, orientation, or size. Sure, techniques like data augmentation can help, but they don’t solve the core issue—CNNs don’t inherently handle transformations well. This is where Capsule Networks really shine. They are inherently robust to affine transformations.
Capsule Networks encode both the presence of features and how they transform. So, instead of needing a million images of a rotated cat, Capsule Networks can understand that the cat’s head, legs, and body are still the same object, even if they appear at a different angle or scale. This is because the transformations are modeled explicitly within the capsules, preserving spatial hierarchies that CNNs tend to lose after pooling layers.
Solving the Invariance-Equivariance Problem
This might surprise you: while CNNs aim for invariance to changes like rotation or translation, Capsule Networks aim for equivariance. Let me explain. Invariance means that the network gives the same output regardless of how an object is transformed. This sounds good, but it often comes at the cost of losing spatial information. CNNs achieve this through pooling, which, as you know, throws away a lot of spatial detail. But what if we didn’t want to lose that information?
Capsule Networks solve this with equivariance—the idea that as the input changes (e.g., an object rotates), the output changes in a predictable way. In other words, the network not only knows what the object is, but how it has changed. This allows Capsule Networks to maintain spatial relationships throughout the network, giving them a much richer and more contextual understanding of the data.
Limitations and Current Challenges
No architecture is perfect, and Capsule Networks have their share of challenges. Let’s dive into the most pressing ones.
Computational Overhead
One of the first things you’ll notice with Capsule Networks is that they come with increased computational complexity. The dynamic routing process, while powerful, is far more computationally expensive than traditional CNN operations like pooling. Capsule Networks perform multiple routing iterations between layers, which significantly slows down training and inference times.
You might be wondering, “How are researchers addressing this?” Several optimizations have been proposed, such as reducing the number of routing iterations or approximating the routing process to make it more efficient. Some studies also explore distributed computing and GPU acceleration to tackle this bottleneck. However, this computational overhead remains a key challenge, especially when scaling Capsule Networks to larger datasets or real-time applications.
Scalability
Speaking of scaling, here’s another challenge: scalability. Capsule Networks work beautifully on smaller datasets like MNIST, but scaling them to more complex, real-world datasets (e.g., ImageNet) is where things get tricky. The primary issue lies in the number of parameters that grow with the size of the network. As you increase the number of capsules and layers, the computational cost skyrockets. This makes it challenging to use Capsule Networks for high-resolution images or tasks that require deep architectures.
Researchers are currently exploring ways to make Capsule Networks more scalable. For example, some approaches reduce the number of parameters through sparsity techniques or by incorporating attention mechanisms to prioritize certain capsules over others. But scalability is still an open research area, and we’re not yet at the point where Capsule Networks can easily replace CNNs for large-scale tasks.
Training Instability
Finally, let’s talk about training instability. Capsule Networks, especially in their original form, suffer from issues related to unstable training. This primarily arises from the dynamic routing process, which can make optimization difficult. Since the routing coefficients are updated iteratively, small changes can sometimes lead to large fluctuations in the gradients, making the network hard to train reliably.
Some solutions have been proposed, such as routing optimization techniques that stabilize the training process or modify the routing algorithm to make it less sensitive to small changes. Techniques like regularization and adaptive routing have also been explored to mitigate this instability. But if you’ve tried training a Capsule Network, you’ve likely experienced firsthand how finicky the training process can be.
Applications of Capsule Networks
Image Classification and Segmentation
You might be wondering, “Where exactly have Capsule Networks made their mark?” Let’s start with the most familiar domain: image classification and segmentation. Capsule Networks have shown great promise in handling complex tasks like recognizing and segmenting objects in images, thanks to their ability to preserve spatial hierarchies and understand part-whole relationships.
Take the well-known MNIST dataset as an example. Capsule Networks, in their early experiments, achieved state-of-the-art performance, with fewer misclassifications than CNNs. But here’s the kicker: they did so while being significantly more robust to distortions in the images. Imagine an MNIST digit rotated or partially occluded—Capsule Networks could still recognize it correctly, something CNNs struggled with.
Capsule Networks have also been applied to more complex datasets like CIFAR-10, showing that they can outperform traditional CNNs in certain object recognition tasks, especially where objects appear in various orientations. In image segmentation, they excel by accurately identifying the boundaries of objects, even in cluttered or noisy scenes. Capsule Networks’ superior understanding of spatial relationships gives them an edge in understanding how different parts of an object connect, making them ideal for tasks like object detection.
Medical Imaging
Now, let’s shift to a domain where part-whole relationships aren’t just helpful—they’re critical: medical imaging. Think about tumor detection or identifying anomalies in X-rays or MRIs. In these tasks, understanding the spatial structure of the tissues or organs is key. Capsule Networks can identify the spatial configurations of these structures far more effectively than traditional CNNs.
For instance, when scanning for tumors, a Capsule Network doesn’t just detect abnormal patches—it understands the relationship between those patches and the surrounding tissues. This level of spatial awareness makes it far better suited for tasks where you need to distinguish between benign and malignant growths, or where anomalies might be subtle but spatially significant.
A study applied Capsule Networks to medical imaging tasks like lung nodule classification and breast cancer detection, showing improved accuracy and interpretability over CNNs. The part-whole hierarchy modeled by capsules allows for a better understanding of how tumors or lesions relate to surrounding tissues—something that CNNs, with their pooling layers, often miss.
3D Object Recognition
You might think, “Capsule Networks work well with 2D images, but what about 3D?” Great question! In environments like autonomous driving, where a car needs to recognize and understand the 3D shape and spatial orientation of objects, Capsule Networks are particularly promising.
Capsule Networks have shown potential in 3D object recognition, where understanding an object from different angles is crucial. They can model the spatial orientation of 3D shapes far more effectively than CNNs, which tend to treat these perspectives as entirely new images. Capsule Networks, on the other hand, understand that a car is still a car, whether it’s viewed from the front, side, or top.
For example, in autonomous vehicles, where detecting pedestrians, other vehicles, or obstacles is essential, Capsule Networks could enhance the ability to accurately recognize objects, even when viewed from different angles or when partially obscured.
Future Directions and Research Areas
Optimization of Dynamic Routing
You might be wondering, “If dynamic routing is so powerful, why isn’t everyone using it?” The truth is, while dynamic routing is one of the key innovations in Capsule Networks, it’s also their Achilles’ heel in terms of efficiency. The iterative process of routing by agreement introduces significant computational overhead, which limits scalability.
Researchers are actively exploring ways to optimize dynamic routing. Some methods aim to reduce the number of routing iterations, while others focus on making the routing process more efficient through approximations. There’s even work being done on making routing adaptive—dynamically adjusting the number of iterations based on the complexity of the task at hand.
A particularly interesting approach is routing by agreement using fewer layers, or even integrating routing with attention mechanisms to only focus on the most critical parts of the input. These optimizations are essential for making Capsule Networks scalable to larger datasets like ImageNet or practical real-time applications like autonomous driving or video analysis.
Integration with Other Architectures
Now, let’s talk about one of the more exciting possibilities: combining Capsule Networks with other state-of-the-art architectures. Imagine the power of Capsule Networks integrated with transformers or attention mechanisms. You get the best of both worlds—the ability to model spatial hierarchies from Capsule Networks and the sequence modeling or global attention capabilities from transformers.
Some early research has explored combining capsules with convolutional layers or even embedding them in architectures like Vision Transformers (ViTs). These hybrid models could open up new avenues in fields like natural language processing (NLP), where capsules could represent semantic hierarchies while transformers handle sequence-level information.
There’s also potential in reinforcement learning, where capsules could be used to model hierarchical relationships in state representations, making learning policies more efficient and interpretable.
Capsules Beyond Vision
Finally, here’s something you might not expect: while Capsule Networks were designed for vision, they have the potential to go far beyond it. Researchers are already looking at applying capsules in areas like NLP and reinforcement learning. In NLP, capsules could model sentence structures or represent word hierarchies, making them useful for tasks like sentiment analysis or machine translation.
In reinforcement learning, capsules could model the environment in a way that captures the relationships between different parts of the state space. For instance, in robotics, understanding how different parts of an object move in relation to each other is key for tasks like grasping or manipulation, and Capsule Networks could provide a more structured representation of these dynamics.
There’s also talk of using capsules for graph data or social network analysis, where understanding the relationships between nodes (e.g., users) is critical. This is still early-stage research, but the potential for Capsule Networks to extend beyond vision into these domains is very real.
Conclusion
So, where does this leave us in the grand scheme of deep learning? Capsule Networks represent a major shift in how we approach object recognition and spatial understanding. By addressing the shortcomings of CNNs—such as their inability to capture spatial hierarchies and their reliance on large datasets for varied transformations—Capsule Networks bring us closer to more human-like vision systems that don’t just detect objects but understand how they fit together.
You’ve seen how pose estimation and spatial relationships make Capsule Networks particularly powerful, allowing them to recognize objects even when viewed from different angles, in different orientations, or with some parts missing. Their ability to handle affine transformations and preserve spatial relationships through equivariance gives them an edge over CNNs, especially in complex tasks like image segmentation and 3D object recognition.
Of course, Capsule Networks are not without their challenges. The increased computational complexity, issues with scalability, and training instability mean that this architecture is still evolving. However, ongoing research into optimizing dynamic routing, integrating capsules with other architectures, and extending their application beyond vision into fields like NLP and reinforcement learning holds enormous promise for the future.
In the end, Capsule Networks offer a glimpse into the future of AI—one where machines can understand the world not just as a collection of pixels, but as a series of interconnected parts with meaningful relationships. As research continues to push the boundaries of what Capsule Networks can achieve, we’re likely to see them play a critical role in advancing both vision-based AI systems and beyond. Whether they eventually replace CNNs entirely or become a key component in hybrid models, one thing is clear: Hinton’s next big idea is only just beginning.