
“Without data, you’re just another person with an opinion” — W. Edwards Deming.
When you’re building machine learning models, it’s easy to get lost in the sea of features, parameters, and endless datasets. But here’s the truth: your model is only as good as its ability to generalize. This is where regularization comes into play. You see, overfitting is the silent enemy of every data scientist. It’s like trying to memorize the answers to every possible question in an exam instead of truly understanding the material. Sure, you might ace that specific test, but try applying that knowledge to a different scenario—things fall apart quickly.
Objective of the Post
You might be wondering, Why is understanding Ridge and Lasso regression so important for me as a data scientist? The answer is simple: both Ridge and Lasso are essential tools in your arsenal when it comes to regularizing machine learning models and preventing them from overfitting. These techniques allow you to fine-tune your models, making them robust enough to handle real-world data while still maintaining predictive power.
As a data scientist, it’s not enough to simply fit a model—you need to ensure that your model can perform well when faced with new data, and regularization helps you strike that balance between underfitting and overfitting. In this post, I’m going to walk you through why Ridge and Lasso are must-know methods, and by the end, you’ll understand exactly when to use each one and how they can enhance your machine learning projects.
Why Is This Comparison Important?
Here’s the deal: regularization is crucial when you’re dealing with models that have many features. It keeps your model grounded by penalizing overly complex structures, preventing it from memorizing noise in your data. Ridge and Lasso both achieve this goal, but in slightly different ways—and these differences matter.
Lasso tends to shrink some of your coefficients to zero, effectively performing feature selection. On the other hand, Ridge works by shrinking coefficients but retains all the features. So, depending on whether you want to simplify your model or preserve all variables, choosing between Ridge and Lasso becomes critical. This comparison is not just academic—it’s something you’ll have to decide on in real-world scenarios. Think of this as the guide you wish you had when you were first learning about regularization.
Overview
In this post, I’ll break things down into bite-sized, understandable pieces. We’ll start by explaining the basics of Ridge Regression, followed by Lasso, then dive into the key differences between the two. You’ll learn when to use each one, and we’ll even cover some real-world use cases. Whether you’re looking to handle multicollinearity with Ridge or perform feature selection with Lasso, I’ve got you covered. And as a bonus, I’ll introduce you to Elastic Net, a hybrid approach that combines the strengths of both.
By the end, you’ll have a crystal-clear understanding of these regularization techniques, so you can make informed decisions in your own machine learning projects. Let’s dive in and get started!
The Problem of Overfitting
What is Overfitting?
Let’s start with a simple analogy. Imagine you’re studying for an exam, and instead of understanding the core concepts, you memorize every single practice question. When the exam comes, you do great—but only if the questions are exactly the same. The moment a new question appears, you’re stuck. This is overfitting in a nutshell.
Overfitting occurs when your machine learning model tries too hard to fit the training data. It learns every tiny detail and noise, which makes it excellent on that particular dataset but terrible at predicting new, unseen data. Essentially, your model is too specific—it’s like knowing the answers by heart but not the method behind solving the problem.
The problem? Your model becomes less generalizable. It performs exceptionally well on your training data but struggles when you throw real-world data at it. And as a data scientist, generalization is the ultimate goal. You want your model to handle unseen data with ease. That’s where regularization steps in.
The Role of Regularization
Here’s the deal: Regularization helps to tame overfitting. Instead of allowing your model to fit every single data point perfectly, it introduces a penalty for complexity. Think of it like adding a constraint to your memorization: instead of memorizing every answer, you focus on the core concepts. This forces the model to generalize better.
Regularization methods like Ridge and Lasso apply penalties to the coefficients of the model, reducing the impact of less important features. By doing this, they strike a balance between bias and variance, ensuring that your model doesn’t overcomplicate things.
Now, let’s dive into the first technique: Ridge Regression.
What is Ridge Regression?
Definition
You might be wondering, What exactly is Ridge Regression? Ridge Regression, also known as Tikhonov regularization, is a technique used to prevent overfitting by applying a penalty to the size of the coefficients in a linear regression model. Specifically, Ridge uses the L2 penalty, which means it minimizes the sum of the squared coefficients.
In simpler terms: Ridge Regression helps shrink the coefficients of less important features, effectively reducing their influence on the model. It’s like asking your model to focus on the bigger picture rather than the small details that might not matter.
How It Works
Now, you might be wondering, How does Ridge actually shrink coefficients?
Here’s how: when you apply the L2 penalty, Ridge essentially forces the model to keep all the features, but it shrinks their influence. This is especially helpful when you have features that are highly correlated (known as multicollinearity). Instead of letting those features dominate the model, Ridge balances things out by shrinking their coefficients, ensuring that no single feature can distort the predictions.
This might surprise you, but Ridge doesn’t set any coefficient to zero—it just reduces their magnitude. This means all your features remain in the model, which can be useful when you believe every feature has some predictive value.
When to Use Ridge
So, when should you reach for Ridge Regression? I’ll give you a few scenarios where Ridge shines:
- Multicollinearity: If your features are highly correlated, Ridge helps stabilize the model by shrinking the impact of those correlated features. In linear regression, multicollinearity can cause wildly fluctuating coefficients, but Ridge smooths this out.
- Lots of Features: When you’re working with datasets that have many features, Ridge is a great choice to prevent your model from becoming too complex. It retains all the features but reduces their individual impact, giving you a well-balanced model.
- Overfitting Prevention: Whenever you’re concerned about overfitting, Ridge Regression helps you create a more generalizable model by penalizing large coefficients.
What is Lasso Regression?
Definition
Here’s the deal: Lasso stands for Least Absolute Shrinkage and Selection Operator. Quite a mouthful, right? But don’t worry, it’s simpler than it sounds. Lasso is a type of regression analysis that applies an L1 penalty to the coefficients in a linear model. In essence, it helps you shrink some coefficients to zero—this means that Lasso doesn’t just reduce the impact of certain features; it can actually eliminate them entirely!
This ability to perform automatic feature selection is what makes Lasso so powerful, especially when you’re dealing with datasets with tons of predictors. It’s like having a model that says, Hey, I’ll keep only the most relevant variables and ignore the noise.
How It Works
Now, this might surprise you: Lasso’s ability to set coefficients to zero means that it automatically performs feature selection. Imagine you have a dataset with 100 variables, but only 10 of them actually contribute meaningfully to your predictions. Lasso will shrink the other 90 down to nothing, leaving you with a simplified, more interpretable model.
Conceptually, this works because the L1 penalty applies more pressure on smaller coefficients than the L2 penalty used by Ridge. As a result, instead of just shrinking coefficients equally, Lasso aggressively pushes some coefficients to zero while allowing others to remain impactful.
When to Use Lasso
So, when should you use Lasso Regression? Here’s a quick guide:
- High-Dimensional Data: If you’re dealing with datasets that have a large number of features, especially when the number of predictors is greater than the number of observations, Lasso shines. It helps you by automatically selecting the most important features.
- Feature Selection: If you need a model that’s not only accurate but also interpretable, Lasso helps by reducing the number of predictors in the final model. This makes it much easier to explain which variables are actually driving your predictions.
- Sparse Solutions: When you want a model where many coefficients are zero, effectively ignoring irrelevant features, Lasso is your go-to tool.
Advantages & Disadvantages of Lasso
Advantages
- Feature Selection: This is Lasso’s superpower. It can eliminate unnecessary features, which helps in building simpler, more interpretable models.
- Interpretable Models: By reducing the number of predictors, Lasso makes it easier for you to understand what’s actually influencing the outcome, which is critical in fields like finance, healthcare, or any domain where explainability is key.
Disadvantages
- Discarding Important Variables: One downside of Lasso is that it might discard features that, while not highly correlated with the outcome, still contribute valuable information. This is especially problematic when features are highly correlated with each other—Lasso may arbitrarily zero out one of the important ones.
- Less Stable Than Ridge: Lasso can be more sensitive to changes in the data, meaning that its results might fluctuate more if the dataset is noisy or changes slightly.
Ridge vs Lasso: Key Differences
Penalty Type
Let’s compare the penalties first:
- Ridge Regression uses an L2 penalty, which squares the coefficients and sums them. This makes the shrinkage uniform across all coefficients.
- Lasso Regression uses an L1 penalty, which sums the absolute values of the coefficients. This allows it to push some coefficients to zero, effectively performing feature selection.
Effect on Coefficients
- Ridge shrinks all coefficients but never forces any of them to zero. Every feature remains in the model, but their influence is reduced.
- Lasso not only shrinks coefficients but can drive some to exactly zero. This makes Lasso a great option for automatic feature selection, whereas Ridge keeps all features in play.
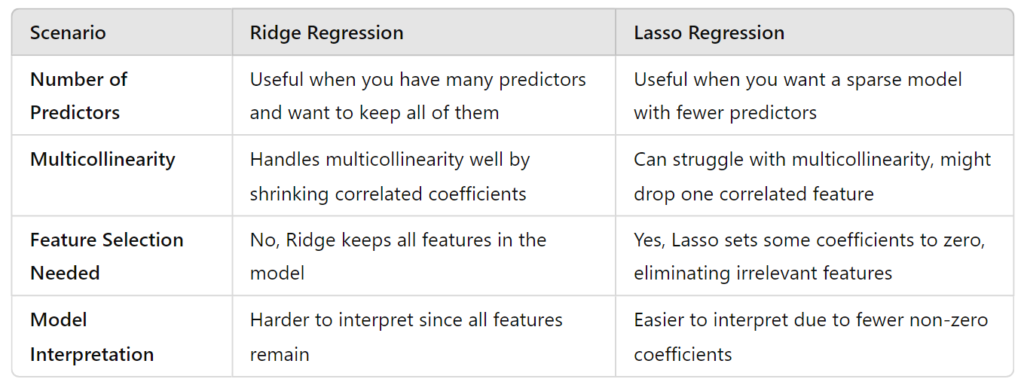
Here’s a table summarizing when to use Ridge vs Lasso:
Practical Implementation
Code Examples
Here’s the deal: Putting theory into practice can make all the difference. Let’s explore how to implement Ridge, Lasso, and Elastic Net in Python using scikit-learn. I’ll walk you through each step with code snippets and explanations.
1. Ridge Regression
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
# Generating synthetic data
X, y = make_regression(n_samples=100, n_features=10, noise=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Creating Ridge Regression model
ridge = Ridge(alpha=1.0) # Alpha is the regularization parameter
ridge.fit(X_train, y_train)
# Making predictions
y_pred = ridge.predict(X_test)Explanation:
Ridge(alpha=1.0): Here,alphacontrols the strength of the regularization. A higheralphameans more regularization.fit()trains the model on your training data.predict()generates predictions for the test data.
2. Lasso Regression
from sklearn.linear_model import Lasso
# Creating Lasso Regression model
lasso = Lasso(alpha=0.1) # Adjust alpha for more or less regularization
lasso.fit(X_train, y_train)
# Making predictions
y_pred_lasso = lasso.predict(X_test)Explanation:
Lasso(alpha=0.1): Similarly,alphahere controls the regularization strength. Lower values ofalphamean less regularization.- The process is the same as Ridge, but Lasso might zero out some coefficients, giving you a sparse model.
3. Elastic Net
from sklearn.linear_model import ElasticNet
# Creating Elastic Net model
elastic_net = ElasticNet(alpha=1.0, l1_ratio=0.5) # l1_ratio balances L1 and L2 penalties
elastic_net.fit(X_train, y_train)
# Making predictions
y_pred_en = elastic_net.predict(X_test)
Explanation:
ElasticNet(alpha=1.0, l1_ratio=0.5):l1_ratiocontrols the balance between Lasso (L1) and Ridge (L2) penalties.l1_ratio=0.5means equal weighting of L1 and L2 penalties.- It combines the properties of both Ridge and Lasso, providing a flexible regularization approach.
Tuning Hyperparameters
Here’s the deal: Tuning the regularization parameter is crucial for getting the best model. You can use cross-validation to find the optimal alpha for Ridge and Lasso.
Example: Cross-Validation for Lasso
from sklearn.model_selection import GridSearchCV
# Defining the model
lasso = Lasso()
# Defining the parameter grid
param_grid = {'alpha': [0.01, 0.1, 1, 10, 100]}
# Performing Grid Search
grid_search = GridSearchCV(lasso, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# Best parameter
print("Best alpha:", grid_search.best_params_)
Explanation:
GridSearchCVtries differentalphavalues (from theparam_grid) and evaluates their performance using cross-validation.best_params_gives you thealphathat performed best.
Performance Evaluation: When Ridge or Lasso is Better
Now, let’s compare Ridge and Lasso to see when one might be better than the other. We’ll use metrics such as Mean Squared Error (MSE), coefficient stability, and interpretability.
Model Comparison
from sklearn.metrics import mean_squared_error
# Ridge predictions and evaluation
y_pred_ridge = ridge.predict(X_test)
mse_ridge = mean_squared_error(y_test, y_pred_ridge)
# Lasso predictions and evaluation
mse_lasso = mean_squared_error(y_test, y_pred_lasso)
print("Ridge MSE:", mse_ridge)
print("Lasso MSE:", mse_lasso)
Explanation:
mean_squared_errormeasures how well the model predictions match the actual values. Lower MSE indicates better performance.- Ridge might perform better when all features are valuable but are correlated, while Lasso might simplify the model more by eliminating irrelevant features.
Real-World Use Cases
- Ridge Regression: Best used in situations where multicollinearity is a concern. For example, in economic forecasting where all predictors are expected to contribute to the outcome, Ridge can handle correlated predictors without removing any.
- Lasso Regression: Ideal for high-dimensional datasets where feature selection is crucial. For instance, in genetic studies where the number of features (genes) far exceeds the number of samples, Lasso helps by focusing on the most relevant genes.
Best Practices for Choosing Ridge vs Lasso
General Guidelines
- Use Ridge when you have many predictors and suspect that most of them are relevant. Ridge provides a stable solution by shrinking coefficients but keeping all features.
- Use Lasso when you want to perform automatic feature selection and end up with a simpler model. This is especially useful in high-dimensional settings where interpretability is important.
Cross-Validation for Selection
To choose between Ridge, Lasso, or Elastic Net, use cross-validation to compare their performance based on your dataset:
from sklearn.model_selection import cross_val_score
# Evaluating Ridge
ridge_cv_scores = cross_val_score(ridge, X, y, cv=5)
# Evaluating Lasso
lasso_cv_scores = cross_val_score(lasso, X, y, cv=5)
print("Ridge CV Scores:", ridge_cv_scores)
print("Lasso CV Scores:", lasso_cv_scores)Considerations Based on Data
- Multicollinearity: If your data has high multicollinearity, Ridge is generally better because it handles correlated predictors well.
- High-Dimensionality: When dealing with many predictors, especially if you suspect that only a few are important, Lasso can help by selecting a subset of features.
- Interpretability: If having a smaller number of predictors is important for model interpretability, Lasso’s feature selection can be advantageous.
Conclusion
In this section, you’ve seen how to implement Ridge, Lasso, and Elastic Net regression using Python. We’ve covered the crucial aspect of tuning hyperparameters and evaluating model performance. I’ve also provided practical advice on when to use each method based on real-world scenarios.
Feel free to experiment with these techniques and see how they fit your specific use case. If you’re ever unsure which method to use, remember to rely on cross-validation and consider the characteristics of your data.
Stay tuned for more insights and practical tips in the next section!