
Have you ever heard the saying, “Not everything that counts can be counted?” Well, in machine learning, everything must be counted—especially categorical data. That’s where one-hot encoding and dummy variables come into play.
Brief Overview: If you’ve worked with machine learning models, you’ve likely come across categorical data—features that represent distinct categories rather than continuous values. But here’s the deal: most machine learning algorithms can’t handle categorical variables directly, and that’s why we need to convert them into numerical form. Two popular techniques to do this are one-hot encoding and dummy variables.
Why it Matters: Why should you care? Well, handling categorical data effectively can be the difference between a model that works and one that fails miserably. If you’re building a predictive model, like a decision tree or a linear regression model, and you don’t preprocess your categorical variables correctly, your model could be feeding on junk data.
Both techniques—one-hot encoding and dummy variables—convert categories into numerical values, but they go about it in slightly different ways. Understanding the nuances between these two approaches is key to making the right choice for your specific project.
Objective of the Blog: By the end of this post, you’ll know exactly:
- What makes one-hot encoding and dummy variables different.
- When and where to use each technique.
- The strengths and weaknesses of both.
So, if you’re ready to unlock the secrets of categorical encoding and boost your model’s performance, let’s dive in!
What are Categorical Variables?
Before we can talk about encoding, let’s start with the basics: categorical variables. Imagine you’re working with data on customers’ favorite colors—red, blue, and green. You can’t feed “blue” into your model the same way you would with a numerical value like “height” or “weight.” This is where categorical variables come in.
Definition: Categorical variables are features that represent distinct groups or categories. These categories don’t have a numeric relationship (at least in most cases) but rather represent labels or types. For example, gender, color, or city are classic examples of categorical variables.
But here’s the catch—machine learning algorithms, especially linear models and neural networks, can’t understand these labels directly. Algorithms need numbers, not words, which is why we need to transform these categories into numerical values before feeding them into models.
Types of Categorical Data: Now, not all categorical data is created equal. There are two main types you need to know:
- Nominal Data: Categories with no inherent order. Think of colors or city names—New York isn’t “more” or “less” than San Francisco.
- Ordinal Data: Categories that have a natural order. For instance, when we rate products as low, medium, or high—there’s a clear ranking here.
Understanding whether your data is nominal or ordinal is critical because it will influence your choice of encoding.
Challenges with Categorical Data: Why can’t we just plug these categories into our models? Well, algorithms like linear regression expect numerical inputs. They need to calculate distances, and they can’t do that with strings like “blue” or “green.” This might surprise you, but if you force categorical data into your model without encoding it properly, you’re essentially sabotaging your algorithm.
So, converting categorical variables into a usable numerical format is essential for the success of your machine learning model.
What is One-Hot Encoding?
Let’s get into the meat of it—one-hot encoding. If you’ve worked with categorical data before, chances are you’ve used this technique. It’s popular for a reason—it’s simple and effective.
Definition: In one-hot encoding, each category of a categorical variable is represented as a new binary column. Think of it like turning every category into its own “yes” or “no” question. The idea is to create a separate column for each unique category, and in that column, you use 1 to indicate that the category is present and 0 to show that it isn’t.
Process: Here’s how it works. Let’s say you have a categorical variable like color with three possible values: red, blue, and green. One-hot encoding will create three new binary columns:
- Is this color red? (1 or 0)
- Is this color blue? (1 or 0)
- Is this color green? (1 or 0)
The original color column disappears, and you’re left with three brand-new columns filled with 0s and 1s.
Example: Let’s look at an example to make things clearer:

This transformation makes the data understandable for machine learning algorithms. Each row is now a numeric vector that represents the presence or absence of each category.
Advantages:
- Easy to implement: If you’re using libraries like
pandasorscikit-learn, one-hot encoding is a breeze. With just a few lines of code, you can turn categorical data into numbers. - Works well for small datasets with fewer categories: If your categorical variables have a limited number of unique categories, one-hot encoding is a safe choice.
Disadvantages: But here’s the problem:
- Sparsity: In cases where your dataset has hundreds of categories (think: zip codes or product IDs), one-hot encoding will create a massive number of columns, most of which will be filled with zeros. This can lead to sparse matrices—matrices with lots of zeros and very little actual information.
- Curse of Dimensionality: With high cardinality categorical variables, one-hot encoding can quickly inflate the dimensionality of your dataset, which in turn can hurt the performance of many machine learning models.
One-hot encoding is great, but it’s not always the best choice—especially when your categorical data has a lot of unique values.
What are Dummy Variables?
So, what about dummy variables? You might be wondering if they’re just another name for one-hot encoding. Well, not quite. They’re similar, but there’s a crucial difference that can save you a lot of headaches in certain situations.
Definition: Dummy variables are a simplified version of one-hot encoding. Instead of creating a new binary column for every category, dummy variables drop one of the categories to avoid something called the dummy variable trap.
Dummy Variable Trap: You might be asking, “What’s the dummy variable trap?” Good question. It happens when you include a binary column for each category, leading to perfect multicollinearity—meaning one column can be perfectly predicted from the others. This can mess up algorithms like linear regression that assume no perfect relationships between independent variables.
Process: To create dummy variables, you drop one of the categories—usually the first or last category. The dropped category becomes the reference category, and the remaining categories are encoded with binary columns.
Example: Let’s revisit our color example:

We’ve dropped the Green category. If the values for Red and Blue are both 0, we know the color must be Green by elimination.
Advantages:
- Prevents multicollinearity: By dropping one category, you avoid the dummy variable trap, making your data more suitable for linear models.
- Reduces dimensionality: With dummy variables, you’ll have fewer columns compared to one-hot encoding, which can make your data easier to work with.
Disadvantages:
- Careful selection of the reference category: You’ll need to think carefully about which category to drop, as it will serve as the baseline for interpretation in models like linear regression.
- Still involves multiple columns: Even though dummy variables reduce the number of columns, they can still bloat your dataset if your categorical variable has many unique values.
Key Differences Between One-Hot Encoding and Dummy Variables
When it comes to handling categorical data, both one-hot encoding and dummy variables offer different strengths and weaknesses. You might think they’re practically the same, but the details can make a huge difference depending on your model and dataset.
Sparsity
Here’s the deal: One-hot encoding has a tendency to blow up your dataset. Imagine having a column with ten different categories—one-hot encoding will turn that into ten new binary columns. Now, picture this for 100 categories. That’s right—you’ll end up with 100 columns! This can lead to what’s called sparse matrices, meaning your dataset is mostly filled with zeros. And that’s not ideal, especially for large datasets. It makes computation more demanding, slows down processing, and consumes more memory.
Dummy variables, on the other hand, give you a slight relief. Since you’re dropping one category (more on that in a bit), you avoid having quite as many columns, which reduces the overall dimensionality just a bit. It’s like clearing a bit of clutter from a packed closet—it doesn’t solve everything, but it helps.
Multicollinearity
Here’s something you might not know: one-hot encoding can cause trouble when used in models like linear regression. Why? It’s called multicollinearity. When you have a column for each category, those columns add redundant information, which confuses models like linear regression because they expect independent features. This leads to unreliable coefficients and inflated standard errors.
Dummy variables dodge this issue. By dropping one category—known as the “reference category”—you avoid multicollinearity. Think of it like subtracting an unnecessary element from a recipe. Everything still works, but you prevent overloading your ingredients. This makes dummy variables the go-to choice for models that are sensitive to multicollinearity, like linear or logistic regression.
Interpretability in Linear Models
Let’s talk about something that often gets overlooked: how the model interprets your data. When you drop one category in dummy variables, the remaining categories are compared to the one you dropped. This makes it easier to interpret coefficients in models like linear regression.
For instance, if you’re modeling how “color” affects house prices, and you drop the “Red” category, then the coefficients for “Blue” and “Green” will represent the impact of those colors compared to “Red.” That way, you know exactly what each coefficient means in relation to the dropped category. In contrast, with one-hot encoding, you might struggle with interpretation because every category has its own column, making comparisons a little murky.
When to Use Each
You might be wondering: when should you use one-hot encoding, and when are dummy variables the better choice? It boils down to three things—your model, your dataset, and your goals.
For Linear Models
If you’re working with models like linear regression or logistic regression, dummy variables are your friend. The key reason? These models don’t handle multicollinearity well, and as we’ve covered, dummy variables sidestep that issue by dropping a category.
But there’s a catch: when you drop a category, make sure it’s the right one. Typically, you’ll want to drop the most common or least important category, depending on what you’re analyzing. Dropping the wrong one could skew your interpretations.
For Tree-Based Models
Here’s the surprise: when it comes to tree-based models like Random Forest or Decision Trees, one-hot encoding is usually acceptable. These models don’t care about multicollinearity the way linear models do. In fact, tree-based models are great at handling a lot of features because they split on the most important ones automatically. So, if you’re building a Random Forest classifier, go ahead and use one-hot encoding without fear of multicollinearity.
Dataset Size and Categories
Now, let’s talk about your dataset. For large datasets with tons of categories, dummy variables are often the better option. Since you’re reducing the number of columns by dropping a category, you’re also cutting down on memory usage and processing time. This can be a lifesaver when you’re dealing with real-world data that has hundreds of categories—like customer demographics or product types.
For smaller datasets, one-hot encoding is fine. If you’re not dealing with dozens of categories, the additional columns won’t hurt your model’s performance, and you might even appreciate the clarity of having one column for each category.
Specific Use Cases
Linear and Logistic Regression
For linear and logistic regression, I always recommend sticking with dummy variables. The biggest reason is multicollinearity—you want to avoid it at all costs. Dropping one category keeps your data clean, and your coefficients will make sense.
Tree-Based Models
On the other hand, for tree-based models like Decision Trees or Random Forests, one-hot encoding works just fine. These models are less sensitive to multicollinearity, so you can freely use one-hot encoding without worrying about the additional columns cluttering your dataset.
Neural Networks
For deep learning models like neural networks, one-hot encoding is often required, especially when dealing with categorical data. Neural networks expect a fixed number of input columns, and one-hot encoding helps meet that expectation.
Ordinal Data
If you’re working with ordinal data (like ratings: poor, fair, good, excellent), you might want to consider other encoding techniques like label encoding or even target encoding, which preserve the order of categories. One-hot encoding and dummy variables treat categories as equally distinct, which might not be the best approach for ordinal data.
Cyclic Categories
Handling cyclic categories (think days of the week or months of the year) is another story. One-hot encoding can work, but in some cases, you might want to explore cyclic transformations that better represent the relationship between the categories.
Pros and Cons: Comparison Table
Sometimes, it’s easier to compare things when you can see everything side by side, right? So, let’s break it down visually and highlight the pros and cons of one-hot encoding vs dummy variables. This way, you can make quicker decisions about which method fits your use case best.
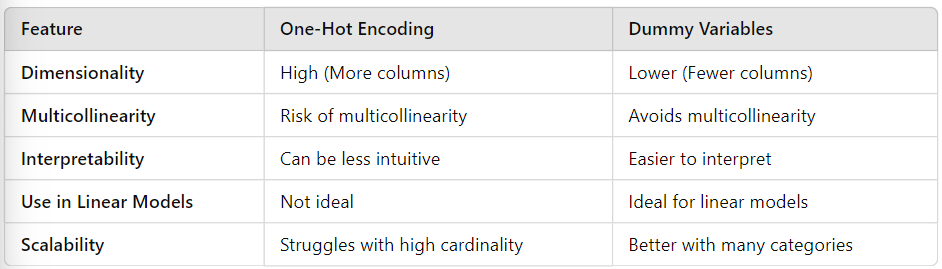
Dimensionality
Here’s something you might not realize until you try it: one-hot encoding tends to create more columns than you might expect. For every unique category, you get a new column. This makes the dimensionality of your dataset spike, which can slow things down and use more memory. On the other hand, dummy variables drop one category per feature, which slightly reduces the dimensionality and makes things a bit easier to manage.
Multicollinearity
When you’re working with models that assume features are independent—like linear regression—you’ll want to avoid multicollinearity at all costs. This is where dummy variables shine because they naturally avoid the problem by dropping one category. One-hot encoding, however, leaves you vulnerable to multicollinearity if you aren’t careful.
Interpretability
When it comes to interpretability, dummy variables make life easier. Since you’re comparing the remaining categories to the one that was dropped, it’s more intuitive to understand what each coefficient represents in linear models. With one-hot encoding, you have a column for every category, which can sometimes make it harder to interpret model outputs.
Use in Linear Models
For linear models (like linear regression or logistic regression), dummy variables are the better choice. Why? Because dropping one category helps you avoid the multicollinearity trap. One-hot encoding, on the other hand, is not ideal because of the extra columns and potential for multicollinearity.
Scalability
Finally, let’s talk scalability. If you’re dealing with datasets that have high cardinality—meaning tons of unique categories—dummy variables perform better because they reduce the number of columns. One-hot encoding struggles in this scenario since it increases the dimensionality dramatically, leading to slower training times and higher memory consumption.
Code Implementation
Now, let’s get our hands dirty with some Python code. I’ll show you how to implement both one-hot encoding and dummy variables using common libraries like pandas and scikit-learn. You’ll see how easy it is to switch between the two methods based on your model’s needs.
One-Hot Encoding Example
Here’s the deal: implementing one-hot encoding is straightforward with the help of pandas. Let’s say you’ve got a dataset with a column for “Color” (Red, Blue, Green). You can quickly convert this column into one-hot encoded columns.
import pandas as pd
# Sample DataFrame
df = pd.DataFrame({
'Color': ['Red', 'Blue', 'Green', 'Red', 'Green']
})
# Apply one-hot encoding
df_one_hot = pd.get_dummies(df, columns=['Color'])
print(df_one_hot)
Output:
Color_Blue Color_Green Color_Red
0 0 0 1
1 1 0 0
2 0 1 0
3 0 0 1
4 0 1 0Notice how it creates a new column for each color and uses binary values (0 or 1) to indicate the presence of each category.
Dummy Variables Example
Now, let’s tackle dummy variables. This is essentially one-hot encoding with one key difference: we drop one category to avoid the dummy variable trap.
# Apply dummy encoding (drop the first category to avoid multicollinearity)
df_dummy = pd.get_dummies(df, columns=['Color'], drop_first=True)
print(df_dummy)
Output:
Color_Green Color_Red
0 0 1
1 0 0
2 1 0
3 0 1
4 1 0As you can see, Color_Blue has been dropped, and now you only have columns for Color_Green and Color_Red. This way, we reduce the dimensionality and prevent multicollinearity when using models like linear regression.
Performance Consideration
Here’s something you might be wondering: how does performance stack up between one-hot encoding and dummy variables when working with large datasets? The answer depends largely on the size of your dataset and the number of categories involved.
One-Hot Encoding on Large Datasets
One-hot encoding is notorious for creating a large number of columns when you have high cardinality features. For example, if you’re working with a dataset of products and one of your features is “Product Category” with 1,000 unique values, one-hot encoding will create 1,000 new columns. This can slow down both the training process and memory usage significantly. So, if you’re using one-hot encoding on a massive dataset, be prepared for longer training times.
Dummy Variables on Large Datasets
Dummy variables perform better when you’re working with large datasets that have many categories. By dropping one category for each feature, you reduce the dimensionality slightly, which means less memory consumption and faster training times. For instance, instead of creating 1,000 columns, you’ll only create 999, which may not sound like a big difference, but it adds up when scaling.
How Different Frameworks Handle These Techniques
Here’s an interesting point: not all machine learning frameworks are equally affected by the increase in dimensionality caused by one-hot encoding. For example, tree-based models (like Random Forests or Decision Trees) handle the additional columns well because they automatically select the most important features during the split process. But linear models and even neural networks can struggle with the extra overhead created by too many features.
If you’re working with linear models, stick with dummy variables. If you’re using tree-based models, you can afford to use one-hot encoding without worrying too much about performance issues.
Conclusion
At the end of the day, the choice between one-hot encoding and dummy variables boils down to the type of model you’re working with and the size of your dataset. If you’re building linear models like regression or logistic regression, you’ll want to stick with dummy variables to avoid multicollinearity and keep things interpretable. On the other hand, if you’re working with tree-based models like decision trees or random forests, one-hot encoding is generally a safe and effective choice.
Here’s the bottom line:
- One-hot encoding is great when you’re working with models that can handle high dimensionality or when you want every category represented. However, it can lead to sparsity and higher computational costs, especially with large datasets.
- Dummy variables help reduce dimensionality and are perfect for linear models where multicollinearity would be an issue. They’re simpler and more interpretable, especially when you’re dealing with small to medium-sized datasets.
When in doubt, ask yourself:
- Are you using a linear model? Go with dummy variables.
- Are you working with a tree-based or neural network model? One-hot encoding will do just fine.
By understanding the trade-offs between these two techniques, you can choose the best one for your specific project, ensuring that your models are both efficient and easy to interpret. Remember, the right choice can not only save time but also lead to better model performance in the long run.
So, next time you’re faced with categorical data, you’ll be well-prepared to make the right encoding decision!