
1. Introduction
Imagine trying to teach a machine to understand the beauty of different colors. Red, blue, green—they mean something to you, but to a machine, they’re just arbitrary labels. This is where the magic of feature encoding comes into play, and trust me, it’s more powerful than it seems. If you’re working with machine learning models, especially with categorical data, you’ve likely stumbled upon the importance of converting categories into a format that machines can process. And One Hot Encoding (OHE) is the key to making that happen.
Definition:
So, what exactly is One Hot Encoding? Picture this: you have a column of categories in your data, such as colors—Red, Blue, Green. Instead of assigning random numerical values to these categories (which might confuse your model), One Hot Encoding transforms each category into a new column, where each category is represented as a binary variable (1 or 0). It’s as if you’re giving your machine a cheat sheet to interpret these categories correctly, without making any misleading assumptions about their order or importance.
Why It’s Necessary:
You might be wondering, “Why can’t I just assign numbers to categories and be done with it?” The truth is, machine learning algorithms are inherently biased towards numbers—they interpret them as having some sort of order. This might surprise you: if you assign 1 to Blue, 2 to Red, and 3 to Green, algorithms like linear regression or neural networks might mistakenly assume that Green is more important than Blue or Red, simply because 3 > 1 or 2. One Hot Encoding solves this problem by ensuring that no such hierarchy exists among categories. Every category gets its own dimension, allowing your model to treat each one equally.
Preview:
In this guide, I’ll walk you through everything you need to know about One Hot Encoding in Python. From its core concept and practical examples using pandas and scikit-learn, to understanding its limitations and alternatives—you’ll have a clear roadmap on how to use it effectively in your machine learning projects. Ready? Let’s dive deeper into what makes One Hot Encoding so essential.
2. Understanding One Hot Encoding: The Concept
Categorical Data Types:
Not all categorical data is created equal. Let’s break it down: in the world of machine learning, we deal with two types of categorical data—nominal and ordinal. Nominal data refers to categories where there’s no specific order or rank, like colors (red, blue, green). On the other hand, ordinal data does have an inherent order (think of a rating system: poor, average, excellent). You might be asking, “Why does this matter?” Because One Hot Encoding is designed to handle nominal data, where the order doesn’t matter. Trying to apply it to ordinal data can lead to misinterpretation, which we definitely want to avoid.
How One Hot Encoding Works:
Now, let’s get into the mechanics of how this works. You have a categorical feature in your dataset, say ‘Color,’ with three possible values: Red, Blue, and Green. Here’s the deal: instead of assigning numbers like 1, 2, and 3 to these values, One Hot Encoding creates three new columns: ‘Color_Red,’ ‘Color_Blue,’ and ‘Color_Green.’ Each row will have a 1 in the column that corresponds to its category and a 0 in the others. For example:

By doing this, the model can understand that each category is distinct, without assuming any order between them.
Example:
Let’s walk through a quick example. Say you have a simple dataset of fruits: Apple, Banana, and Orange. If you applied One Hot Encoding, here’s what you’d get:
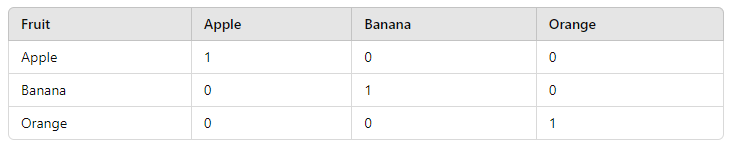
In this case, each fruit gets its own column, and now the model has a clear way of understanding the relationship (or lack thereof) between these categories.
The Pitfalls of Label Encoding:
Now, you might be thinking, “Can’t I just assign a unique number to each category?” Technically, you could. But here’s the problem: by assigning labels like 1, 2, and 3, you’re inadvertently telling the model that there’s a ranking between them, even when there isn’t. This is known as the ordinal trap. When you assign numbers to categories that don’t have a meaningful order, the model starts treating them as if they do. This can throw off your predictions in a big way. One Hot Encoding, however, avoids this pitfall entirely by ensuring that no relationships are implied between categories.
Practical Considerations When Using One Hot Encoding
Dealing with High Cardinality:
Let’s face it, not all features are created equal. Some features, like city names or product IDs, can have hundreds or even thousands of unique categories. This is what we call high cardinality, and here’s the deal: when you apply One Hot Encoding to a feature with high cardinality, you end up creating a massive number of new columns. Imagine turning a column with 1000 unique cities into 1000 binary features—it’s like turning a simple problem into a monster.
So, what can you do? You’ve got a few options:
- Frequency Encoding: This might surprise you, but instead of creating a binary feature for each category, you can encode each category based on how frequently it appears in the data. For example, if “New York” appears 20% of the time in your data, you encode it with 0.2. It’s a compact way to handle high cardinality without exploding your feature space.
- Grouping Rare Categories: Another clever trick is to group rare categories into an “Other” bucket. Let’s say you’re working with 1000 cities, but 90% of your data only comes from 10 major cities. Instead of creating individual features for every small town, you can group the rare cities into one category, reducing the number of features and avoiding a sparse matrix.
Feature Selection After One Hot Encoding:
Once you’ve performed One Hot Encoding, you might find yourself with a bloated dataset filled with tons of features, and not all of them are important. You might be wondering, “How do I know which features to keep?” One solution is to use techniques like Principal Component Analysis (PCA) to reduce dimensionality and retain only the most valuable information from your encoded data.
Alternatively, if you’re using regularization-based models like Lasso Regression, you can automatically perform feature selection by penalizing less important features. This can help shrink those less impactful columns to zero, effectively removing them from your model. It’s like letting your model clean up the mess that OHE might leave behind.
Memory and Performance Impact:
Here’s something you might not have considered: One Hot Encoding can dramatically increase memory usage. Each new binary column requires storage, and when you have high cardinality, it can cause a serious memory blow-up. If you’re working with large datasets, this becomes even more critical. One trick to mitigate this is to use sparse matrices. By storing only the positions of the 1s and ignoring all the 0s, you can significantly reduce memory usage without sacrificing performance.
Another tip: batch processing your data. Instead of loading the entire dataset into memory, process it in smaller chunks, applying One Hot Encoding in a streaming fashion. It takes a bit more effort, but your RAM will thank you.
6. Common Mistakes to Avoid
Encoding Test Data Separately:
One of the biggest rookie mistakes—and I’ve seen it far too often—is encoding your training and test data separately. You might think it’s fine, but here’s the deal: when you fit your encoder on the training data, it learns the categories present in that dataset. If you then apply a fresh One Hot Encoding on the test set, it might generate new columns for categories that weren’t present in the training set—or worse, drop columns for categories that aren’t in the test set but were in training. This leads to mismatched feature sets between training and test, which throws your model into chaos.
The fix? Simple: fit your encoder on the training data and then use that same encoder to transform both your training and test sets. That way, your features remain consistent throughout.
Overfitting with Rare Categories:
Here’s another trap that even experienced data scientists fall into: overfitting on rare categories. Let’s say you’re working with a dataset where a certain category only appears a handful of times. If you create a binary feature for it, your model might start overfitting on this rare case because it treats it as highly specific information. This can distort your model’s predictions, especially if that category doesn’t show up in the test set or real-world data.
To avoid this, you can either group rare categories (as we discussed earlier) or use regularization to prevent the model from over-relying on features with little statistical significance.
Multicollinearity:
This might surprise you: One Hot Encoding can introduce multicollinearity into your model. Since each category is represented as a separate feature, the model can face issues if all categories are included. For instance, if you have three categories—Red, Blue, and Green—one of them is fully determined by the other two. This introduces redundancy, which can mess with algorithms like linear regression.
The fix? Simply drop one of the categories when encoding. This is often referred to as drop-first encoding. By removing one category, you ensure that the remaining features are independent, which helps avoid multicollinearity.
7. Comparison with Other Encoding Methods
One Hot Encoding vs Label Encoding:
Let’s do a quick recap. Label encoding assigns a unique integer to each category. It’s simple, but it has one major flaw: the model assumes that the categories have a numerical order. Imagine assigning 1 to “Dog” and 2 to “Cat.” Does that mean Cats are somehow “greater” than Dogs? Of course not. Label encoding can mislead your model in situations where no natural order exists between categories. That’s where One Hot Encoding comes to the rescue, ensuring that each category is treated independently, without any implied ranking.
However, in scenarios where ordinality exists—for example, in a rating system like “Poor, Average, Good”—label encoding can still be useful, since the order of categories has meaning.
One Hot Encoding vs Ordinal Encoding:
Ordinal encoding works well when the categories have a meaningful order. Think about customer satisfaction ratings: “Poor, Average, Good, Excellent.” In such cases, you want your model to understand that “Excellent” is better than “Good,” which is better than “Poor.” But if you tried applying One Hot Encoding here, you’d lose this inherent order, and your model wouldn’t know how to prioritize these values.
So, when should you use which? The answer is simple: use Ordinal Encoding when order matters, and stick with One Hot Encoding when you want to treat categories as equals.
One Hot Encoding vs Target/Mean Encoding:
You might be wondering, “Is there an alternative to One Hot Encoding for high cardinality features?” There is, and it’s called target encoding (or mean encoding). Instead of creating binary features for each category, target encoding replaces each category with the mean of the target variable (for classification, this is the mean probability). This is especially useful when you have categories like product IDs or zip codes with thousands of unique values.
For example, if you’re predicting whether a customer will buy a product, you can replace each category (e.g., product type) with the average probability of purchase for that type. This helps reduce dimensionality and avoids the sparse matrix problem that One Hot Encoding can cause.
Conclusion
And there you have it—everything you need to know about One Hot Encoding in Python. As you’ve seen, One Hot Encoding plays a critical role in preparing categorical data for machine learning models, helping to avoid the pitfalls of label encoding and ensuring that your models don’t make incorrect assumptions about the relationships between categories.
Here’s the takeaway: while One Hot Encoding is powerful and often the go-to solution for categorical data, it’s not without its challenges. From high cardinality issues to memory concerns, you’ve got to be smart about how and when you use it. Whether it’s frequency encoding to deal with too many unique categories, PCA for feature reduction, or ensuring that you don’t overfit to rare categories, being aware of these practical considerations will elevate the performance of your models.
But remember, no single method fits all situations. In some cases, label encoding, ordinal encoding, or target encoding might be more appropriate based on your dataset and the problem at hand. The real trick is knowing when and how to apply these techniques—like a craftsman selecting the right tool from their toolbox.
So, whether you’re building pipelines with scikit-learn or diving deep into large-scale projects, I hope this guide has given you the knowledge to use One Hot Encoding effectively. If you want to go further, experiment with real-world datasets, and don’t hesitate to try out different encoding strategies to see what works best for your model.
Good luck, and may your features always be as clean and efficient as your code!