
Let’s kick things off with a strong opening. When it comes to categorical data, translating words, labels, or categories into a format that machines can understand is a critical step. Machine learning models, after all, only comprehend numbers. This might surprise you: one of the simplest yet most effective ways to accomplish this is through one-hot encoding—a method that’s been around for a while but continues to play a vital role in the machine learning ecosystem.
What the Reader Will Learn:
So, what exactly will you take away from this? By the end of this post, you’ll have a solid understanding of how one-hot encoding works, why it’s an essential tool for machine learning, and when to use it (or when not to). Plus, you’ll see practical examples in action, and I’ll even break down the common challenges you may face when using one-hot encoding.
Importance of Encoding Categorical Data:
Now, let’s talk about categorical data and why it needs special treatment. Imagine you’re working with a dataset that contains colors: red, blue, and green. A machine learning model doesn’t inherently understand what these words mean. It can’t process “red” as it would a number like 10 or 0.05. Without converting these categories into a numerical form, most machine learning algorithms would simply fail to work.
There are a few ways to handle this, and that’s where encoding comes in. One option is label encoding, which assigns a unique number to each category (e.g., red = 1, blue = 2, green = 3). While that sounds simple, it introduces a problem: models might interpret the numbers as having a ranking or order. Suddenly, blue seems “greater” than red just because it has a higher number! That’s not what we want.
How One-Hot Encoding Works:
Here’s the deal: instead of assigning numbers directly, one-hot encoding solves this by creating a new column for each category. If the category exists in a given observation, the corresponding column gets a ‘1’. Otherwise, it gets a ‘0’. Think of it as a way of creating “flags” for each category, without any implied hierarchy.
Example of One-Hot Encoding:
Let’s dive into an example. Imagine you’re working with a simple dataset that contains the “Color” column with three values: Red, Blue, and Green. Here’s what happens after applying one-hot encoding:

Comparison with Label Encoding:
At this point, you might be wondering: Why not just use label encoding? It’s a fair question. Label encoding can work well in certain scenarios, especially when dealing with ordinal categorical data, where the order matters (like ranking preferences from “low” to “high”). But for nominal categorical variables, such as colors or city names, one-hot encoding shines because it avoids introducing any kind of artificial order.
To sum up: label encoding is quick and simple but risky for nominal categories, whereas one-hot encoding ensures that each category is treated independently.
With this solid foundation, you’re already well on your way to understanding the nuances of one-hot encoding. Up next, we’ll break down when and why you should use this method—and dive into a few practical challenges and optimizations you can leverage.
How One-Hot Encoding Works
Step-by-Step Process:
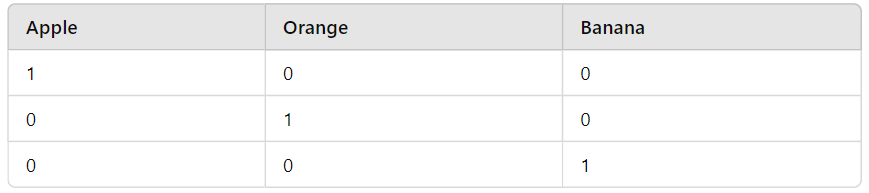
Let’s walk through the one-hot encoding process step by step. Imagine we have a simple dataset with a column of fruits:
Fruit
-----
Apple
Orange
Banana- 1. Creating Binary Columns:
To apply one-hot encoding, we create a new binary column for each fruit. If a row contains a specific fruit, the corresponding column gets a ‘1’, otherwise, it gets a ‘0’. Here’s what that looks like:
2. Coding it in Python:
Now, let’s jump into how you’d implement this in Python. We’ll use pandas or sklearn, which make this incredibly easy. Here’s an example using pandas:
import pandas as pd
# Sample data
df = pd.DataFrame({
'Fruit': ['Apple', 'Orange', 'Banana']
})
# One-hot encoding
one_hot = pd.get_dummies(df['Fruit'])
print(one_hot)Output:
Apple Banana Orange
0 1 0 0
1 0 0 1
2 0 1 0
Using sklearn, you can use the OneHotEncoder function:
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse=False)
one_hot = enc.fit_transform(df[['Fruit']])
print(one_hot)
Mathematical Representation:
For those of you who like seeing things more mathematically, here’s how one-hot encoding looks as a matrix transformation. Imagine we have three categories (Apple, Orange, Banana):
Let x∈{Apple,Orange,Banana}x \in \{Apple, Orange, Banana\}x∈{Apple,Orange,Banana}. After one-hot encoding, this becomes:
x_1 = [1, 0, 0] (Apple)
x_2 = [0, 1, 0] (Orange)
x_3 = [0, 0, 1] (Banana)
This matrix representation ensures that the machine learning model sees only numerical values, making the data easier to process.
Why and When to Use One-Hot Encoding
Why Use One-Hot Encoding:
One-hot encoding is vital for machine learning, especially with categorical features. Machine learning models like decision trees, random forests, and k-nearest neighbors don’t know what to do with text labels like “Apple” or “Orange.” They need the data in numerical form.
Here’s the deal: algorithms such as decision trees or k-nearest neighbors rely on distances between data points. If you pass text data directly, the model will crash or perform poorly because it can’t compute distances between strings. That’s where one-hot encoding steps in, translating categories into a format the model can handle effectively.
For example, in tree-based models like random forests, one-hot encoded features allow the model to branch on each category independently. In distance-based algorithms like SVM or k-NN, one-hot encoding helps calculate the distance between data points properly, without implying any ordering between categories.
When to Use One-Hot Encoding:
You should use one-hot encoding when dealing with nominal categorical variables—that is, categories without any natural order (like colors, fruits, or cities). This method shines when you have a limited number of categories.
However, beware of high cardinality. If a categorical feature has hundreds or thousands of unique values (like zip codes or user IDs), one-hot encoding can create a very large and sparse matrix, which can slow down training and increase memory usage. For high-cardinality features, you might want to consider alternative methods like target encoding or embedding layers.
Advantages and Disadvantages of One-Hot Encoding
Advantages:
- Preserves the Independence of Categories: One of the major perks of one-hot encoding is that it treats each category as an independent entity. This is crucial when dealing with nominal data (i.e., data with no intrinsic order, like colors or cities). By using a binary matrix, one-hot encoding ensures that no ordinal relationship is mistakenly imposed between categories. This independence is critical for many machine learning models, especially tree-based methods like random forests and decision trees.
- Works Well with Many Machine Learning Algorithms: Algorithms like k-nearest neighbors (k-NN) and support vector machines (SVM) heavily rely on distances between data points. When categories are transformed into binary vectors, these algorithms can better capture relationships in the data. Neural networks also benefit because the binary representation fits nicely into input layers, where each category is treated independently.
- Simple to Implement: This might surprise you: one-hot encoding is incredibly easy to implement using Python libraries like pandas or sklearn. With just one line of code, you can transform categorical data into a format that most machine learning models can work with.
Disadvantages:
- Curse of Dimensionality: Here’s the deal: one-hot encoding can lead to something called the curse of dimensionality. Every new category gets its own binary column. If you’re dealing with high-cardinality features—like hundreds of cities or product names—this approach creates a sparse dataset with a lot of zeroes. Too many columns can slow down your model, increase memory usage, and even reduce performance.
- Memory Inefficiency: You might be wondering, “What’s wrong with a few extra columns?” Well, it’s not just about columns—it’s about the zeros. When you’re dealing with thousands or even millions of data points, all those zeros can create a serious memory problem. Storing these large sparse matrices becomes inefficient, especially for big data applications.
- May Not Work Well with Certain Models: While one-hot encoding is great for some algorithms, it can introduce multicollinearity in others, particularly linear regression. Since each category is represented by multiple binary columns, these columns can be correlated, which messes with model assumptions and can lead to overfitting or distorted predictions.
Alternatives to One-Hot Encoding
- Label Encoding: Label encoding assigns each category a unique integer. While it’s simple and reduces the dimensionality issue, it imposes an ordinal relationship. This means the model might think that “Apple” (encoded as 0) is somehow ‘less’ than “Banana” (encoded as 1), which isn’t true for nominal data. It’s great for ordinal data (like rating scales) where the order matters, but for nominal categories, one-hot encoding is often the safer choice.
- Binary Encoding: Want a middle ground? Binary encoding is a compact alternative that transforms categories into binary numbers. It reduces the number of dimensions while avoiding ordinal relationships. For example, instead of having 100 columns for 100 categories, binary encoding may only require 7 or 8 columns, significantly reducing sparsity.
- Frequency and Target Encoding: If you’re dealing with high-cardinality features, frequency encoding might be a good choice. This method replaces each category with its frequency in the dataset. Target encoding, on the other hand, replaces categories with the mean of the target variable. While more advanced, these techniques can help models capture more nuanced relationships, especially in supervised learning.
Practical Applications of One-Hot Encoding in Machine Learning
One-Hot Encoding in Neural Networks:
Neural networks, particularly deep learning models, thrive on numerical input. One-hot encoded vectors fit perfectly into the input layers, where each feature can be treated independently. In fact, one-hot encoding is often the first step before embedding layers in models like Word2Vec or GloVe in NLP tasks. You can think of one-hot encoding as the raw, unrefined input that the model learns to transform into more meaningful representations during training.
Text Classification and NLP:
Before the rise of word embeddings, one-hot encoding was a go-to method for representing text in natural language processing (NLP) tasks. Although it’s largely been replaced by more advanced methods like Word2Vec and BERT, one-hot encoding still serves as a foundational technique. For instance, when you’re building a text classifier from scratch, one-hot encoding can be an easy way to represent the presence or absence of certain words or tokens.
Real-World Example:
Let’s look at a Kaggle competition example. In the Titanic dataset, one-hot encoding is often used to represent categorical variables like “Sex” or “Embarked” (the port of departure). Here’s how you might apply it in a pipeline with sklearn:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Sample data
X = titanic_df[['Sex', 'Embarked']]
y = titanic_df['Survived']
# Preprocessing: One-hot encoding
preprocessor = ColumnTransformer(
transformers=[('encoder', OneHotEncoder(), ['Sex', 'Embarked'])])
# Build a pipeline
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression())])
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Fit the model
pipeline.fit(X_train, y_train)
print(f"Model score: {pipeline.score(X_test, y_test)}")
By one-hot encoding the categorical variables, you improve the model’s ability to learn from features that aren’t naturally numerical, increasing predictive power.
Conclusion
As we wrap up our exploration of one-hot encoding, it’s clear that this technique plays a crucial role in the preprocessing pipeline for machine learning models. By converting categorical variables into a binary format, one-hot encoding allows algorithms to interpret the data effectively, preserving the independence of categories and enhancing model performance.
But it’s not all sunshine and rainbows. The curse of dimensionality, memory inefficiencies, and potential issues with multicollinearity remind us that one-hot encoding isn’t a one-size-fits-all solution. Understanding its advantages and disadvantages empowers you to make informed choices based on the specific needs of your dataset and the algorithms you’re using.