
Imagine you’re trying to teach a machine how to see—without ever giving it labeled examples of what it’s looking at. Sound challenging? That’s precisely the hurdle we’re tackling in unsupervised learning, especially when it comes to visual representation. Here’s the deal: labeling data, especially images, is time-consuming, expensive, and often impractical when the dataset scales to millions of images. But, in the absence of labeled data, how do you teach a machine to understand and categorize visual inputs?
This is where unsupervised learning shines, helping models learn from raw, unlabeled data. It’s become a game-changer in fields like computer vision, where self-supervised and unsupervised techniques are now the backbone of tasks like object recognition and scene understanding. However, traditional unsupervised methods have limitations, and that’s where Momentum Contrast (MoCo) steps into the spotlight.
You might be wondering: What makes MoCo special in the realm of unsupervised visual representation learning? In this blog, we’ll break down MoCo in a way that not only makes it easy to understand but also deep enough for you to see how to implement it in your work.
Background on Unsupervised Learning and Visual Representations
Before we dive into MoCo, let’s set the stage with a quick look at visual representation learning. At its core, visual representation learning is about teaching machines to understand images—extracting the essential features or representations of an image so that tasks like classification, object detection, and even image generation become more efficient. Now, when you don’t have labeled data, you have to teach the model to identify these features all by itself. This is why unsupervised learning is so critical.
For example: Imagine trying to build a facial recognition system. In a supervised setting, you would need millions of labeled face images. But with unsupervised learning, the model begins to recognize patterns—like the eyes, nose, and mouth—without explicit guidance. That’s the magic of visual representation learning!
Traditional Methods: You’ve probably heard of autoencoders, self-supervised learning (SSL), and contrastive learning. These have been the go-to methods for unsupervised tasks. Autoencoders, for instance, aim to compress an image into a low-dimensional space and then reconstruct it, essentially learning a compressed representation.
But here’s the catch: many of these traditional methods either struggle with scalability or lack the sophistication to truly capture complex visual patterns in large datasets. Contrastive learning made significant strides by focusing on creating positive (similar) and negative (dissimilar) pairs of images. However, it wasn’t always practical due to memory and computational constraints.
This might surprise you: even though contrastive learning works well, it’s often held back by the sheer size of datasets and the need for large batch sizes to learn effective representations. This is exactly where Momentum Contrast changes the game, and in the next section, we’ll explain how.
What is Momentum Contrast (MoCo)?
Let’s get right to it: Momentum Contrast, or MoCo, is a method for contrastive learning that aims to solve one of the core challenges in unsupervised visual representation learning—scaling efficiently while maintaining performance. In contrastive learning, the idea is simple: you want your model to map two augmented views of the same image to similar representations (positive pairs) and map different images to dissimilar representations (negative pairs).
Here’s the deal: MoCo uses a momentum-based encoder to generate stable key representations for these positive and negative pairs. It builds a dynamic dictionary, a queue of negative samples, to efficiently scale learning without the need for massive batch sizes. The dictionary helps keep a large pool of negatives, which is crucial for effective learning in contrastive frameworks.
Definition: Momentum Contrast (MoCo) and Contrastive Learning in Context
In plain terms, contrastive learning is about teaching a model to differentiate between “similar” and “dissimilar” images. Imagine you have two photos of the same dog, but from different angles. You’d want the model to learn that these two images represent the same concept—a dog. So, you create a positive pair by augmenting one image in different ways (maybe zooming in or flipping it), and a negative pair by comparing that image with a totally different image, like a cat. Your goal is for the model to push the representations of positive pairs closer together and the negative pairs further apart.
Now, why is MoCo special? Traditional contrastive learning methods like SimCLR require large batch sizes to generate diverse negative samples for comparison. But large batches can lead to memory constraints and make training slower. MoCo solves this by using a momentum-based encoder and a dynamic dictionary to store and recycle negative samples, making it scalable without needing massive computational resources.
High-Level Overview of MoCo
At a high level, MoCo works by maintaining two encoders:
- A query encoder, which is regularly updated during training.
- A key encoder, which is updated more slowly using a momentum mechanism. This slow update is key to maintaining stable representations over time.
When an image is augmented into two views, one goes through the query encoder, and the other through the key encoder. The query representation is compared against both the key representation (the positive pair) and a dynamic queue of negative samples to learn an effective representation.
You might be wondering: Why is this momentum mechanism important? Well, it ensures that the key encoder doesn’t change too rapidly, which would otherwise destabilize the learning process. This results in smoother, more consistent training.
Why MoCo Stands Out
Here’s what makes MoCo different from other methods like SimCLR:
- Momentum-based encoder: Instead of relying on large batch sizes to provide negative examples, MoCo uses a slowly updated key encoder that provides more stable representations.
- Dynamic dictionary: MoCo maintains a queue of negative samples that dynamically updates as new samples are added. This allows MoCo to scale with a large number of negative samples, without requiring huge batch sizes.
In contrast, SimCLR requires extremely large batches because its negative samples are restricted to the current batch. MoCo decouples the need for large batches by keeping a history of negatives in its queue, making it far more scalable.
The Core Components of Momentum Contrast
Now that we’ve got the basics down, let’s dig deeper into the critical components that make MoCo work so effectively. We’ll focus on two main parts: the Momentum Encoder and the Queue of Negative Samples.
Momentum Encoder
What It Is: MoCo’s architecture revolves around two encoders: a query encoder and a key encoder. The query encoder is regularly updated through backpropagation, just like any typical neural network. But the key encoder? That’s a bit special. It’s updated using a momentum mechanism—a slow, gradual update based on the query encoder.
Why Momentum? You might be asking, “Why go through all this trouble with momentum?” Well, let me put it this way: if the key encoder were updated too quickly, it would make learning unstable. Think of the key encoder as the “memory” of the model. If this memory is rewritten too rapidly, the model loses consistency, especially when comparing recent and older samples. Momentum updates ensure that the key encoder changes slowly, preserving stable representations over time and making training much smoother.
Queue of Negative Samples
What It Is: Instead of relying on the current batch to provide negative samples, MoCo maintains a queue (or dynamic dictionary) of negative examples. This queue is essentially a memory bank that stores representations of images processed in previous batches, constantly updated as new data comes in.
Why a Queue? Here’s the problem with contrastive learning in traditional setups: the model needs lots of negative samples to effectively learn to differentiate between images. SimCLR, for example, uses massive batch sizes because it generates its negatives from within each batch. But what if your batch size is small? You end up with too few negative samples, which can hurt performance.
MoCo sidesteps this issue by storing a large number of negative samples in a queue, allowing it to scale up without needing large batches. The queue is updated as new samples are processed, meaning it always has fresh negatives for the model to learn from. Think of it as a revolving door: new samples come in, old ones leave, but the pool remains consistently large and diverse.
Dynamic vs. Fixed: Here’s where MoCo really stands out. In SimCLR, the negative samples are fixed within the batch—they don’t get recycled. But in MoCo, the queue is dynamic, constantly refreshing and ensuring that you have a larger, more diverse set of negatives over time. This makes MoCo significantly more memory-efficient and scalable, particularly for large datasets.
Step-by-Step: How MoCo Works
Let’s break down Momentum Contrast (MoCo) step-by-step. I want to make sure you get a clear picture of how this powerful framework operates without getting lost in technicalities. You might be wondering: What’s really happening under the hood when MoCo is training a model? Don’t worry, I’ve got you covered with a simple yet detailed walkthrough.
Step 1: Augment an Image to Generate Two Views: Query and Key
Imagine this scenario: You take an image, let’s say a photo of a cat. In MoCo, this image is augmented twice to create two different views—one will be used as the query and the other as the key. These augmentations could involve random cropping, flipping, color jittering, or any transformation that changes the appearance of the image without altering its fundamental features.
The idea is that both views represent the same image (positive pair), but they look different enough for the model to learn meaningful representations.
Step 2: Pass the Query Through the Query Encoder
Now, you pass the query (one of the augmented views) through the query encoder. This encoder extracts features from the image, mapping it into a high-dimensional representation space. In simple terms, the model takes the query and translates it into a series of numbers that represent the essential characteristics of that image.
Step 3: Pass the Key Through the Key Encoder (Momentum-Based)
Here’s where MoCo’s magic happens. The other augmented view (the key) is passed through the key encoder—but, unlike the query encoder, the key encoder is updated using momentum. This encoder changes more slowly than the query encoder, ensuring that the representations it generates remain stable over time. Think of it as having a slow-moving observer, keeping track of key features without rapidly changing its mind.
Step 4: Compare the Query Representation to the Representations of the Key and Negative Samples in the Queue
Now comes the contrastive part of the learning process. Once the query and key representations are generated, the query is compared not only with the key (its positive pair) but also with a large set of negative samples stored in the dynamic queue. These negative samples represent other, dissimilar images.
Here’s the goal: You want to maximize the similarity between the query and the key (positive pair) while minimizing the similarity between the query and all the negative samples. This process pushes the model to differentiate between what “belongs together” and what doesn’t.
Step 5: Update the Encoders
Now that the comparison is done, we update the encoders:
- The query encoder is updated using traditional backpropagation based on the gradients computed from the loss function.
- The key encoder is updated more slowly, using a momentum mechanism. This prevents it from changing too rapidly and helps maintain consistency over time.
This ensures that while the query encoder is adapting quickly to new information, the key encoder provides a more stable reference for learning.
Step 6: Add the Key Representation to the Queue and Remove the Oldest Entry to Maintain Queue Size
Finally, the key representation is added to the dynamic queue of negative samples, which is constantly updated. The queue is like a revolving door: as new samples are added, the oldest ones are removed to maintain a fixed size. This way, the model always has a fresh, diverse pool of negative samples to learn from, without needing massive batch sizes.
Advantages of MoCo
Now that you have a step-by-step understanding of MoCo, let’s dive into why it’s so effective. You might be wondering: What makes MoCo better than traditional methods? Let’s explore the advantages.
Scalability
MoCo scales far better than traditional self-supervised learning (SSL) methods. In SSL, like SimCLR, negative samples are usually generated within each batch, meaning that to get more negatives, you’d need to increase the batch size. But with MoCo’s dynamic queue, the size of your negative sample pool is decoupled from the batch size, making it much more scalable without requiring massive computational resources. The bottom line: You can train MoCo efficiently, even on smaller GPUs, and still maintain a large number of negative samples.
Training Efficiency
By using a dynamic dictionary (the queue of negative samples), MoCo avoids the memory constraints that traditional contrastive learning models face. This queue allows MoCo to learn with smaller batches while still getting a rich set of negatives. This makes training not only faster but also more memory-efficient. In other words: You get the benefits of large-batch learning without the computational cost.
Consistency in Representations
The momentum encoder is another secret weapon of MoCo. Because the key encoder is updated slowly, the representations it generates remain stable and consistent over time. Why does this matter? If the key encoder changed too rapidly, the model wouldn’t have reliable comparisons between positive and negative samples, and this could destabilize the learning process. Think of it like this: MoCo keeps a steady hand, ensuring smooth and consistent learning throughout.
Applications of MoCo
MoCo isn’t just a theoretical concept—it’s been put to work in real-world scenarios with impressive results. Here’s where it gets interesting:
Real-World Use Cases
MoCo has been successfully applied in areas like:
- Image retrieval: Finding similar images in large datasets without any labeled data.
- Object detection: Learning object representations for tasks like detecting objects in real-world scenes.
- Semantic segmentation: Helping models understand the layout and boundaries of objects within images, which is crucial for things like autonomous driving.
You might be wondering: Why MoCo? Because it doesn’t rely on labeled data, which makes it highly versatile across different fields that need visual representation learning, even when labeled datasets are hard to come by.
Pretraining for Downstream Tasks
MoCo is also widely used as a pretraining technique for models that are later fine-tuned for supervised tasks. For example, a MoCo-pretrained model can be fine-tuned for tasks like image classification or object detection, saving both time and resources. This transfer learning approach is becoming a standard in unsupervised learning workflows.
Limitations of MoCo
As powerful as MoCo is, no method is without its downsides. Let’s look at a few limitations you need to keep in mind.
Need for Large Negative Samples
MoCo relies heavily on a large pool of negative samples for effective contrastive learning. While the dynamic queue helps manage this more efficiently than methods like SimCLR, there’s still a dependence on maintaining a large number of negative samples. In some cases, this can make MoCo less effective when the number of negative samples is small or when they’re not diverse enough.
Complexity
Here’s the trade-off: While MoCo’s dual-encoder setup (with query and key encoders) gives it a unique advantage, it also adds to the overall complexity of the system. Managing two encoders and a dynamic queue requires more architectural considerations compared to simpler contrastive learning frameworks. This complexity may not always be worth the extra performance gains, depending on your task.
How MoCo Evolved (MoCo v2, v3)
Now, you might be thinking: “If MoCo was already powerful, why the need for versions like MoCo v2 and MoCo v3?” It’s a valid question, and the answer is simple—innovation doesn’t stop. Researchers are constantly pushing boundaries, making even great methods like MoCo more efficient, more accurate, and more versatile. So let’s look at how MoCo has evolved.
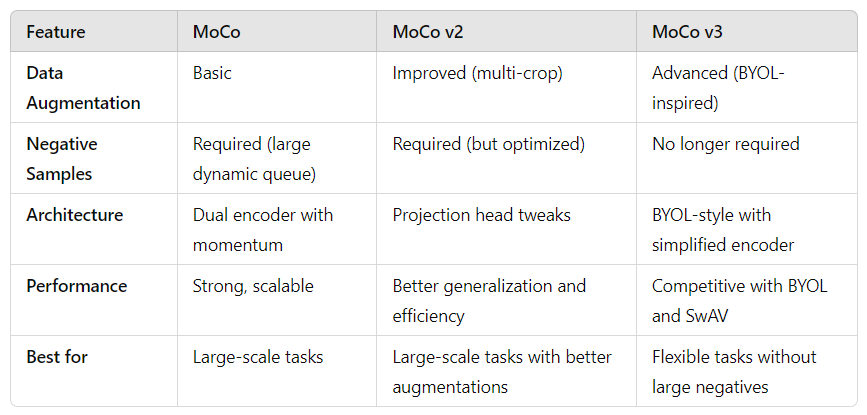
MoCo v2: Improvements in Data Augmentation and Architecture
Here’s the deal: MoCo v2 took everything that worked in the original MoCo framework and fine-tuned it. One of the most notable improvements in MoCo v2 was the incorporation of stronger data augmentation techniques. If you’ve worked with self-supervised learning, you know that data augmentation plays a crucial role in generating diverse views of the same image, which helps the model learn robust representations. MoCo v2 uses techniques like multi-crop augmentation, which introduces more variability in the augmented views and improves the model’s generalization ability.
But that’s not all: MoCo v2 also brought architectural tweaks, such as improvements in the design of projection heads—the final layers that map the output of the encoder to a lower-dimensional space where the contrastive loss is computed. These tweaks result in smoother training and more powerful representations, giving MoCo v2 a performance boost across various tasks.
Real-World Impact: This version of MoCo was shown to outperform the original in tasks like image classification, object detection, and segmentation, making it a go-to solution for many practitioners looking to fine-tune models with unlabeled data.
MoCo v3: Evolving to Compete with BYOL and SwAV
MoCo v3 takes things a step further and brings the framework closer to state-of-the-art methods like BYOL (Bootstrap Your Own Latent) and SwAV (Swapping Assignments Between Views). If you’ve kept an eye on the latest developments in contrastive learning, you know that these newer methods have dominated the unsupervised learning space.
Here’s what’s interesting about MoCo v3:
- No more need for negative samples. In MoCo v3, the architecture moves away from relying heavily on large negative sample queues. Instead, it adopts a more refined contrastive learning approach similar to BYOL, where only positive pairs are used to align representations. This shift simplifies the architecture and reduces the dependency on massive memory for storing negative samples.
- Improved learning efficiency. With fewer architectural constraints, MoCo v3 streamlines the learning process. The focus is on self-supervised learning without contrastive loss, yet still providing competitive representations for downstream tasks like image classification and semantic segmentation.
Why this matters: MoCo v3 is now able to compete head-to-head with the best unsupervised learning methods available. It brings MoCo closer to approaches like BYOL and SwAV, which are known for their ability to work without negative samples, offering even greater flexibility and simplicity for practical applications.
Comparison: MoCo, MoCo v2, and MoCo v3
Let’s summarize the evolution across the versions:
Conclusion
So there you have it! Momentum Contrast (MoCo) has steadily evolved from its initial form into one of the most powerful tools for unsupervised visual representation learning. Starting with the original MoCo framework, which introduced the innovative use of a momentum encoder and dynamic queue, to MoCo v2, which refined augmentation strategies and architectural design, and finally, to MoCo v3, which competes with the latest methods by eliminating the need for negative samples altogether.
What’s the takeaway for you? MoCo—and its later versions—give you a versatile, scalable toolset for training models without labeled data. Whether you’re working on tasks like image retrieval, object detection, or just pretraining for downstream supervised learning, MoCo provides the performance and efficiency you need. And with its steady evolution, it’s only getting better at solving the complex challenges of contrastive learning.
So, whether you’re diving into MoCo v2 for better data augmentations or exploring MoCo v3 for its simplicity and cutting-edge performance, you’re now equipped with the knowledge to choose the right tool for the job. The future of unsupervised learning is bright, and MoCo continues to push the envelope.