
You might not realize it, but every day, whether it’s scheduling flights, optimizing supply chains, or tuning machine learning models, deterministic optimization algorithms are silently at work, ensuring we get the best outcomes. They don’t rely on chance; they deliver precision—every single time.
Hook: The Relevance of Deterministic Optimization Algorithms
Here’s the deal: certainty is a luxury in many areas of science and technology, but when it comes to deterministic optimization algorithms, certainty is exactly what you get. These algorithms are indispensable across various fields—data science, machine learning, operations research, engineering—and that’s because they guarantee the same result for the same input every time. Imagine this: you’re tasked with allocating resources for a large company’s supply chain. Do you really want randomness in your solution, or do you need something you can rely on? That’s where deterministic optimization comes in.
Definition
Let me keep it simple: deterministic optimization algorithms are methods that follow a fixed procedure, ensuring the same output every time, given the same input. There’s no dice-rolling here—just a clear, defined path to a solution. In essence, these algorithms are the control freaks of the optimization world.
To give you an analogy: imagine navigating a maze. A deterministic algorithm always takes the same turns in the maze—no random guesses, no detours—ensuring you end up at the same exit every time. It’s reliable, predictable, and efficient.
Context & Importance
Why does this matter to you? Well, in many real-world problems, especially those involving high-stakes decisions (think: finance, engineering, or resource management), precision and predictability are critical. Unlike stochastic optimization algorithms, which incorporate randomness and might give you different answers on different runs, deterministic algorithms offer something special: consistency. You need a solution? You get it, without the unpredictability.
Take machine learning, for instance. When you’re training models, especially ones like Support Vector Machines (SVMs) or Linear Regression, deterministic optimization ensures you’re getting the same model every time you run it—no surprises, just pure reliability.
Key Characteristics of Deterministic Optimization Algorithms
Predictability
Imagine this: you’ve built a machine learning model, and every time you run it with the same data, you get a slightly different result. Frustrating, right? Deterministic algorithms spare you from that headache. They’re like a GPS—give them the same destination, and they’ll always guide you along the same path.
Convergence
Now, what’s particularly neat about deterministic optimization algorithms is their ability to converge. Convergence is a fancy way of saying that the algorithm is guaranteed to get closer and closer to the optimal solution, and eventually, it lands on it. Whether it’s a global minimum (the best possible solution) or a local minimum (a solution that’s the best in a small area), these algorithms have a knack for getting there.
Deterministic Nature
This might surprise you: deterministic algorithms can be both a blessing and a curse. Their deterministic nature means that they don’t wander off into random paths—they follow the rules strictly. This can be fantastic if you’re working with a well-structured problem. But if your problem is riddled with multiple local minima, sometimes you might wish for a little randomness to shake things up! (But we’ll get to that later.)
Computational Complexity
You might be wondering: what’s the catch? Well, deterministic algorithms, especially those that involve complex derivatives (like Newton’s method), can sometimes be computationally expensive. In plain English: they might need a lot of computing power and time to get to the solution, especially for larger problems. But in cases where you need accuracy, that computational cost is often worth it.
Scalability & Problem Size
Finally, let’s talk scalability. As the size of the problem increases—more variables, more constraints—deterministic algorithms might struggle a bit. Some algorithms scale better than others. Linear programming (Simplex), for instance, can handle large datasets quite well, but more complex methods like Gradient Descent can slow down when things get high-dimensional. It’s crucial to consider how your choice of algorithm matches the size of the problem you’re dealing with.
Types of Deterministic Optimization Algorithms
Optimization is all about choosing the right tool for the right job, and deterministic optimization algorithms come in many flavors, each with its own strengths. Whether you’re optimizing a machine learning model or solving complex industrial problems, these algorithms offer precision and reliability. Let’s break down some of the most important ones.
Gradient-Based Methods
Gradient-based methods are like hiking in the mountains with a map. These methods help you find the lowest point (or minimum) of a function by following the “steepest descent.”
Gradient Descent
You might be familiar with this one—it’s a workhorse in machine learning. Gradient descent works by calculating the slope (or gradient) of the function at your current position and then taking a step downhill, toward a lower value of the function. The idea is simple: repeat this process until you reach the bottom (local minimum).
Here’s the catch: Gradient descent is guaranteed to find a minimum, but it might not always be the global minimum. It can get stuck in a local dip, especially in non-convex problems. Imagine trying to hike down a mountain but ending up in a small valley that isn’t the lowest point. You’re stuck, and that’s the challenge gradient descent faces.
Newton’s Method
Now, if gradient descent feels slow and steady, Newton’s method is more like taking a shortcut by calculating not just the gradient (first derivative) but also the curvature (second derivative). It uses this extra information to take bigger, more accurate steps toward the minimum.
But here’s the deal: Newton’s method needs you to compute the Hessian matrix (a matrix of second-order partial derivatives). This can be computationally expensive, especially when you’re working with high-dimensional problems. However, when the Hessian is available, Newton’s method can converge much faster than gradient descent.
Quasi-Newton Methods
You might be wondering: What if we could combine the speed of Newton’s method with the simplicity of gradient descent? That’s exactly what quasi-Newton methods, like BFGS (Broyden-Fletcher-Goldfarb-Shanno), try to do. They approximate the Hessian matrix instead of computing it directly, saving time and computational resources. BFGS strikes a balance between accuracy and efficiency, making it popular in many optimization problems.
Simplex Method (Linear Programming)
If you’ve ever worked on linear optimization problems, you’ve probably used the Simplex Method. Picture this: you’re in a multi-dimensional space, and your task is to find the highest or lowest point on a surface (subject to some constraints). The simplex method moves along the edges of this multi-dimensional shape (called a polytope) until it finds the optimal solution.
Here’s what makes Simplex powerful—it works incredibly well for problems that can be written in a linear form, and it’s widely used in industries like operations research for tasks like optimizing supply chains or resource allocation.
Branch and Bound
Branch and Bound is your go-to method when dealing with discrete optimization problems, like integer programming. Think of it as solving a jigsaw puzzle: you break the problem into smaller sub-problems (branch), solve them independently, and then use these solutions to prune away paths that won’t lead to the optimal answer (bound).
This method is particularly useful when you need an exact solution in combinatorial optimization problems. For example, if you’re assigning delivery trucks to routes, where each assignment must be an integer, Branch and Bound can efficiently search for the best solution.
Dynamic Programming
Dynamic programming is like divide-and-conquer—it breaks down a large problem into smaller, manageable sub-problems. Each sub-problem is solved once, and the results are stored for future reference (memoization). This makes dynamic programming especially powerful for structured problems like sequence alignment in bioinformatics or shortest path algorithms in network routing.
Let’s say you need to find the shortest path through a network of cities. Dynamic programming doesn’t just guess—it methodically solves each part of the problem and combines them for the best result.
Cutting Plane Methods
Here’s a method you might not encounter every day, but it’s essential for linear and convex optimization. Cutting plane methods iteratively refine the feasible region by “cutting away” sections that don’t contain the optimal solution. Imagine you’re trimming the fat off a piece of meat until only the best cut remains—this is how the algorithm hones in on the solution.
These methods are particularly useful in high-dimensional optimization problems where traditional approaches might struggle. They’re often used in integer programming and convex optimization.
Key Applications of Deterministic Optimization
You might be surprised by how many industries rely on deterministic optimization algorithms. Let’s explore some key areas where they play a pivotal role:
Operations Research
Whether it’s optimizing transportation routes, minimizing costs, or maximizing production efficiency, deterministic methods like linear programming are heavily used in operations research. For example, companies like Amazon and UPS use these algorithms to optimize their supply chains and ensure deliveries happen on time and at the lowest cost.
Machine Learning
When you’re training a Support Vector Machine (SVM), you’re using deterministic optimization to find the best separating hyperplane. Deterministic methods ensure that, given the same data and parameters, your model will be consistent every time.
Economics & Finance
Portfolio optimization is a classic problem in finance, where you aim to maximize returns while minimizing risk. Deterministic optimization ensures that you get the exact optimal portfolio allocation, which can be crucial when managing millions of dollars.
Engineering & Design
From structural optimization to resource allocation, deterministic algorithms help engineers design more efficient systems. Think about optimizing the layout of a building to use the least amount of material while maintaining strength—deterministic optimization finds the best solution without any guesswork.
Control Systems
In control processes—whether it’s managing energy in power grids or regulating the temperature in a chemical reactor—precision is key. Deterministic optimization ensures that the control systems behave predictably, leading to more reliable outcomes.
Deterministic vs. Stochastic Optimization
At this point, you might be asking yourself: When should I use deterministic optimization, and when is stochastic a better choice? Let’s break it down:
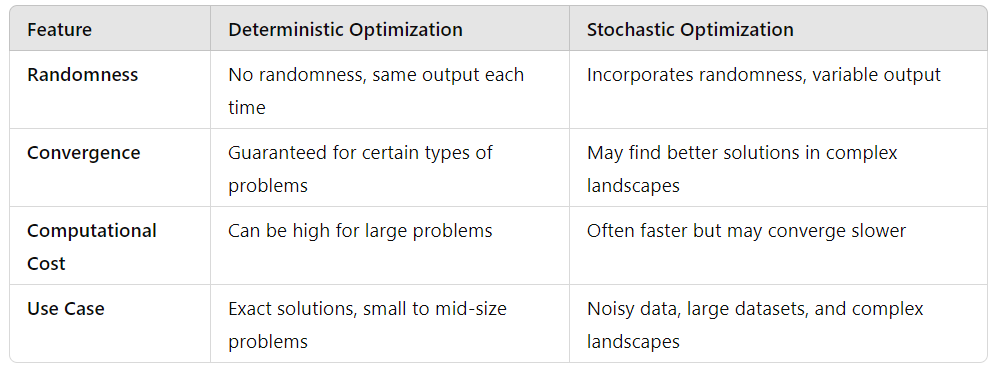
When to Use Each
- Use deterministic methods when you need precision, reliability, and the ability to reproduce results. For example, if you’re optimizing a machine learning model with clean data, deterministic algorithms like Gradient Descent or Simplex are ideal.
- On the other hand, stochastic methods shine when your problem space is vast or noisy. If you’re working with deep learning models on massive datasets, stochastic gradient descent (SGD) can explore more of the solution space, finding good (if not exact) solutions faster.
Tools and Libraries for Implementing Deterministic Optimization
You’ve got the theory down, and now you’re ready to roll up your sleeves and put deterministic optimization algorithms into practice. Luckily, the right tools can make implementing these algorithms a lot easier, whether you’re working in Python, R, or MATLAB, or dealing with large-scale industrial problems using solvers like Gurobi or CPLEX. Let’s walk through the essential tools you’ll want in your optimization toolkit.
Python Libraries
Python has become the go-to language for many data scientists, and for good reason. When it comes to deterministic optimization, Python’s ecosystem is rich with libraries that offer powerful solutions.
1. scipy.optimize
If you’ve worked with Python, you’ve probably heard of SciPy, a scientific computing library that’s as versatile as it is powerful. The scipy.optimize module is where you’ll find several deterministic optimization methods, from linear programming to constrained optimization. For example, if you want to solve a minimization problem, scipy.optimize.minimize provides access to algorithms like BFGS, Newton’s method, and Simplex.
Here’s a quick example: Let’s say you’re trying to minimize a function representing costs in a supply chain. SciPy’s optimization functions can help you find the most cost-efficient solution without any randomness involved, ensuring you get consistent results every time.
from scipy.optimize import minimize
def objective_function(x):
return x**2 + 3*x + 2
result = minimize(objective_function, 0)
print(result.x)
2. cvxpy
Next up is cvxpy, a library specifically designed for convex optimization. If you’re dealing with problems that can be formulated as convex, like linear or quadratic programs, cvxpy is an intuitive and powerful tool. It allows you to describe your optimization problem using simple mathematical expressions, and then it solves them using deterministic methods.
For example, you could use cvxpy to optimize a portfolio in finance, balancing risk and return by minimizing variance while ensuring a certain expected return. It’s widely used in operations research and finance, where precision is key.
3. PuLP
When your optimization problem involves linear programming, PuLP is another Python library worth considering. It’s simple, lightweight, and integrates well with larger solvers like Gurobi and CPLEX. If you’re working on optimizing resource allocation or transportation logistics, PuLP makes it easy to formulate and solve these linear problems.
R Libraries
If you’re an R user, the world of deterministic optimization is still at your fingertips. While Python might be the current favorite, R offers some strong optimization tools for both linear and non-linear problems.
1. optim
The optim function in R is a versatile tool for solving unconstrained and constrained optimization problems. You can use it to implement algorithms like BFGS, Newton’s method, and Nelder-Mead. The power of optim lies in its flexibility—it can handle non-linear optimization just as easily as linear problems.
2. lpSolve
For linear programming tasks, lpSolve is the go-to library in R. It’s robust and handles everything from integer programming to mixed-integer linear programming (MILP). Suppose you’re managing inventory in a warehouse and need to minimize costs while meeting demand constraints—lpSolve helps you model that as a linear optimization problem.
Here’s a simple example:
library(lpSolve)
objective <- c(1, 3, 2)
constraints <- matrix(c(1, 1, 0, 0, 1, 1), nrow = 2, byrow = TRUE)
rhs <- c(100, 150)
direction <- c("<=", "<=")
result <- lp("max", objective, constraints, direction, rhs)
print(result$solution)
MATLAB
MATLAB might be a bit pricier, but when it comes to optimization, it’s hard to beat its Optimization Toolbox. Whether you’re solving linear, quadratic, or nonlinear problems, MATLAB has a deterministic solver for the job.
MATLAB’s Optimization Toolbox
The Optimization Toolbox in MATLAB is like having an entire optimization arsenal at your disposal. It offers deterministic methods like Simplex, BFGS, Interior-Point algorithms, and more. You can solve anything from small linear systems to large-scale nonlinear problems with precision. Plus, MATLAB’s graphical tools allow you to visualize convergence in real time, which is a nice touch when you’re debugging or trying to understand the optimization landscape.
For example, if you’re optimizing the design of an airplane wing for minimum drag while adhering to strength constraints, MATLAB provides the deterministic solvers you need to get accurate, reliable results every time.
Solver Software: Gurobi & CPLEX
For industrial-strength optimization, you might need something a little more powerful. This is where solvers like Gurobi and CPLEX come in. These are high-performance optimization engines designed for large-scale, complex problems where both speed and precision are critical.
1. Gurobi
Gurobi is one of the fastest solvers available for deterministic optimization. It handles everything from linear programming (LP) to quadratic programming (QP) and mixed-integer programming (MIP). If you’re working on problems like vehicle routing, scheduling, or energy grid optimization, Gurobi is a powerhouse that guarantees consistent, deterministic solutions.
2. CPLEX
IBM’s CPLEX is another heavyweight in the optimization world. Like Gurobi, CPLEX is designed for large-scale optimization and offers solvers for linear, mixed-integer, and quadratic programming. One of its standout features is the ability to solve multi-objective problems, making it ideal for scenarios where you need to balance multiple competing objectives, like maximizing profits while minimizing environmental impact.
Conclusion
By now, you’ve seen how deterministic optimization algorithms provide a clear, reliable path to solving complex problems. Whether you’re working in Python, R, or MATLAB, or need the horsepower of Gurobi or CPLEX, the tools and libraries available today make it easier than ever to implement these algorithms with precision.
But here’s the big takeaway: deterministic optimization is about more than just solving a problem—it’s about solving it consistently and predictably. You know that when precision and repeatability matter, these algorithms are your best bet.