
Let’s face it, your machine learning models aren’t set-and-forget systems. They’re living, breathing algorithms that constantly interact with the outside world. And here’s the deal: the world changes. This is where “data drift” and “model drift” come into play, but many overlook just how critical these concepts are to maintaining strong model performance in production.
Whether you’re working in finance, healthcare, or retail, understanding the difference between data drift and model drift is key to avoiding nasty surprises when your model suddenly becomes unreliable. I’m here to walk you through not just what these drifts are, but how to spot and handle them—before they cost you.
Importance in Machine Learning
You might be wondering: why should you care so much about drift? Well, think of it this way—your model is only as good as the data it was trained on. But what happens when the world around it changes? Whether it’s shifting consumer behavior or a sudden market event, drift can quietly ruin your model’s predictive power. And the worst part? It often happens without anyone noticing—until it’s too late.
Imagine a fraud detection system that slowly loses its edge because the tactics of fraudsters evolve. That’s data drift in action. Or think about a recommendation engine that suddenly starts giving terrible suggestions after months of good performance—welcome to the world of model drift.
Overview
In this blog, I’ll break down data drift and model drift, explaining why these phenomena matter and how you can detect and mitigate them. By the end of this post, you’ll have a solid understanding of the subtle differences between these two drifts, and more importantly, actionable strategies to keep your machine learning models robust in production environments.
Understanding Data Drift
Definition
First, let’s get on the same page. Data drift refers to the gradual, and sometimes sneaky, change in the distribution of the input data over time. Think of it like this: the data your model is seeing today may not be the same type of data it was trained on a few months ago. And this is a problem.
To put it simply, data drift occurs when your data evolves, but your model remains stuck in the past. It’s like trying to navigate a new city with an old map—it’s bound to get you lost.
Types of Data Drift
Now, not all data drift is created equal. There are a few different types you should be aware of, and knowing these distinctions can help you pinpoint the issue more effectively.
Covariate Shift
This might surprise you, but one of the most common forms of drift is covariate shift, where the distribution of the independent variables (the features) changes. Imagine running a model predicting house prices, but suddenly, the average size of houses in the dataset increases. Your model is used to smaller houses—it’s not prepared for this.
Prior Probability Shift
Here’s where things get a little tricky. Prior probability shift refers to changes in the distribution of the target variable (the thing you’re trying to predict). For instance, say you’re predicting which users will churn in a subscription service, but suddenly your customer base grows rapidly. The probability of churn changes—and your model might not keep up.
Concept Drift (Brief Mention)
Without going into too much detail just yet, it’s worth briefly mentioning concept drift. While data drift affects the input data, concept drift changes the relationship between the features and the target. It’s a more complex issue, which we’ll dive into in the next section.
Causes of Data Drift
So, what causes data drift? The world is constantly changing, and so is your data. External factors like market conditions, seasonal trends, and even human behavior can affect the features your model relies on. For example, imagine you’re analyzing consumer spending habits—an economic downturn or a sudden change in consumer behavior (thanks to a viral trend or new tech) can create data drift without warning.
Real-World Examples
To make this concept more relatable, let’s walk through some real-world scenarios:
- Finance: In fraud detection, the techniques used by fraudsters evolve. A model trained on old fraud patterns may not be able to catch new types of fraudulent activity, leading to data drift.
- Healthcare: In a clinical setting, a model predicting patient outcomes could experience drift if new treatment protocols are introduced, or if the demographics of patients change over time.
- E-commerce: An e-commerce recommendation engine might experience data drift when trends or consumer preferences shift. For instance, if your model was trained on winter clothing sales data and is now dealing with summer purchases, the features it relies on may no longer apply.
Understanding Model Drift
Definition
Alright, let’s tackle model drift. While data drift is all about changes in the data your model sees, model drift happens when your model’s performance starts to degrade over time. This could be due to data drift (which we’ve already discussed), but there are other culprits at play too.
Think of your model like a skilled chef. When you first train it, you give it a perfect recipe. But as time goes on, the ingredients (your data) start to change. The chef doesn’t notice, keeps following the old recipe, and, suddenly, the dishes don’t taste quite right anymore. That’s model drift in a nutshell—the performance of the model declines because it’s no longer tuned to the changing world around it.
Distinguishing It from Data Drift
You might be wondering: “Wait, isn’t model drift just data drift in disguise?” Not exactly.
While data drift can cause model drift, they aren’t the same thing. Data drift is a change in the inputs; model drift is the result—a decline in the accuracy, precision, or other key performance metrics of the model itself. And here’s the kicker: model drift can happen even if there’s no obvious data drift. For example, if your model is re-trained using a suboptimal strategy or if feature engineering slowly becomes less effective, the model’s performance can degrade over time.
In other words, data drift is about the data; model drift is about the model. The two are connected but distinct issues.
Causes of Model Drift
Let’s break down the main reasons model drift might sneak up on you:
Changes in Data Patterns (Data Drift)
As we just discussed, the most common cause of model drift is data drift itself. When the data your model was trained on no longer represents the data it’s making predictions on, things go wrong. Your model is like an outdated map trying to navigate a new city. It’s bound to lead you astray.
Incorrect Feature Engineering Over Time
Here’s something that might surprise you: even if the data doesn’t change, your feature engineering can become stale. Imagine you’re using a set of features that were perfect when you first trained your model. But over time, those features may lose their predictive power because of changes in external conditions or new trends in the data. For example, let’s say you’re predicting customer churn, but your feature engineering relies heavily on outdated customer behavior patterns.
Suboptimal Model Re-Training Schedules
It’s easy to fall into the trap of thinking that re-training your model regularly will solve all your problems. But here’s the deal: if you’re re-training your model on data that hasn’t been properly cleaned or segmented, or if you’re not considering the drift, you could end up harming your model instead of improving it. Think of it as giving your chef bad ingredients—no matter how often they cook, the meal is going to suffer.
Examples of Model Drift in Practice
Let’s ground this theory with some real-world scenarios:
- Recommendation Systems: Picture this—you’ve built a recommendation engine for an e-commerce site. Over time, your users’ tastes change (data drift), but your model doesn’t adjust accordingly. Suddenly, the once-accurate recommendations feel way off. Your model drifts because it’s relying on patterns that no longer exist.
- Fraud Detection: Fraudsters evolve. A model trained to detect old fraud patterns might not pick up on newer tactics, leading to model drift. The result? Missed fraud cases and a model that’s increasingly unreliable.
- Marketing Campaigns: Suppose you’ve built a model to predict the success of marketing campaigns based on past data. Over time, user engagement habits shift due to new social media trends. Even though your data collection is consistent, the model no longer performs well because the feature-target relationship has evolved (concept drift, which we’ll explore next).
Data Drift vs. Concept Drift vs. Model Drift
Now that you understand model drift, let’s lay everything out clearly. This section is all about helping you distinguish between data drift, concept drift, and model drift.
Comparison Table/Visual
Here’s a handy table that breaks down the key differences:
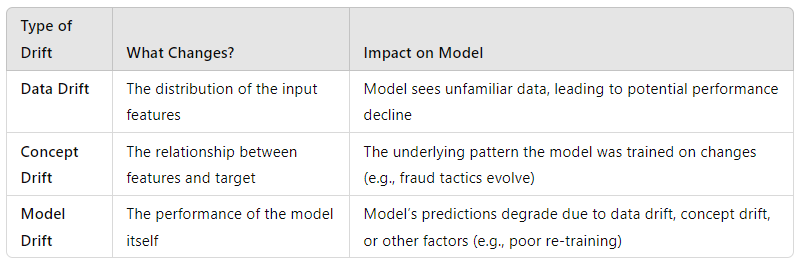
Key Takeaways
Here’s the simplest way to think about it:
- Data Drift: Your model is seeing different data than it was trained on.
- Concept Drift: The relationship between inputs and outputs changes. The model can no longer trust its previous logic.
- Model Drift: Your model is getting worse over time. Whether it’s data drift or poor maintenance, your predictions suffer.
You can’t afford to ignore any of these. Data drift, concept drift, and model drift can silently erode the performance of even the best models. So, it’s not just about building the right model—it’s about maintaining it in an ever-changing world.
Methods to Detect Data Drift
Now that you know what data drift is, the next logical question is: how do you detect it? After all, you can’t fix what you can’t see. The good news? You’ve got a number of tools in your toolkit—ranging from statistical methods to machine learning models—that can help you spot data drift before it wreaks havoc on your predictions.
Statistical Methods
Kolmogorov-Smirnov Test (for univariate continuous data)
Here’s the deal: if you’re dealing with continuous variables, the Kolmogorov-Smirnov (KS) test is your go-to method. It measures the difference between two distributions—your model’s training data versus new incoming data. If the test shows a significant difference, bam—you’ve got data drift. Think of it as a thermometer for your data; it tells you if something’s off, but it doesn’t explain why.
Chi-Square Test (for categorical data)
If you’re working with categorical data, the Chi-Square test is your friend. It compares the observed and expected frequencies of categorical features between two datasets (training data vs. new data). For example, say you’re working with product categories in an e-commerce system. If the frequency of a certain category suddenly shifts, the Chi-Square test will pick it up.
Population Stability Index (PSI)
PSI is a powerful metric when you’re dealing with demographic or time-dependent data. This method compares the distribution of data between two time periods—let’s say your model was trained on last year’s data, and you want to see how this year’s data compares. PSI gives you a score, and based on that score, you can determine if drift is happening. I like to think of PSI as a “health check” for your features. Anything above a certain threshold? Time to dig deeper.
Machine Learning Methods
Unsupervised Models: Autoencoders or Clustering for Anomaly Detection
You might be wondering: “What if I need a more nuanced way to detect drift?” That’s where unsupervised learning models come in. Autoencoders, for instance, are fantastic at learning patterns in your training data. If new data looks wildly different from what the autoencoder expects, it raises a red flag. Similarly, clustering algorithms like k-means can group your data into clusters, and if new data doesn’t fit any existing cluster, that’s your signal for potential drift.
Supervised Approaches: Train a Model to Classify Between Old and New Data Distributions
This might surprise you, but sometimes the best way to detect data drift is by using a supervised learning approach. Here’s the idea: you create a binary classification model that tries to distinguish between old (training) data and new (current) data. If your model can easily differentiate between the two, guess what? Drift detected.
Monitoring and Tools
You’re probably thinking, “This all sounds great, but how do I actually implement this?” Luckily, there are several fantastic tools available to make data drift detection easier.
- Evidently: This open-source library is excellent for monitoring both data and concept drift, offering detailed visual reports.
- WhyLabs: A robust monitoring platform that helps detect, understand, and correct data quality issues in real-time.
- Built-in Features from AWS/Google Cloud: If you’re using platforms like SageMaker or Vertex AI, you can take advantage of built-in drift detection features to automate the process.
Methods to Detect Model Drift
Alright, now let’s talk about model drift. Data drift is only part of the problem—you also need to know when your model is slipping. Think of this like checking your car’s performance. Even if the road (data) looks fine, your engine (model) might still be wearing down.
Performance Monitoring
The easiest way to spot model drift? Keep an eye on performance metrics like accuracy, F1 score, or ROC-AUC. But here’s the catch: you’ve got to track them over time. Let’s say your model’s accuracy was 95% when you first deployed it, and now it’s hovering around 80%. That’s a clear sign that something’s going wrong. Tracking these metrics over time helps you notice when the drift begins, so you can take action.
Comparison with Baseline Models
Here’s a little trick I like to use: always keep a baseline model around. This is a simple model, like a decision tree or a logistic regression, trained on the same data as your complex model. If your current model’s performance starts to degrade compared to the baseline, you know it’s time to investigate model drift. This keeps you grounded and gives you something to compare against.
Validation on New Data
One thing I’ve noticed is that people often re-train models without validating them properly. To catch drift, make sure you’re validating on new data, not just your training or validation sets. One effective method is using temporal validation, where you split the data based on time. If your model performs well on old data but poorly on recent data, you’ve got a drift issue on your hands.
Drift Detection Algorithms
Now, let’s get into some algorithms that are specifically designed to detect drift:
ADWIN (Adaptive Windowing)
This algorithm is perfect if you’re working with streaming data. ADWIN dynamically adjusts the window of recent data that it considers, detecting when there’s a significant change in data distribution. It’s like a radar, constantly scanning for changes and adjusting as needed. It’s particularly useful in situations where you’re dealing with real-time data streams, such as IoT or financial systems.
Page-Hinkley Test
Another great tool for detecting abrupt changes in your model’s performance is the Page-Hinkley Test. This statistical test helps you spot sudden drifts by keeping track of a moving average of your performance metrics. If there’s a sharp decline, the test flags it. It’s simple, effective, and widely used in dynamic environments.
Techniques to Handle Data Drift
So, you’ve detected data drift. Now what? This is where things get interesting because handling data drift isn’t just about knowing it’s there—you need to have strategies in place to deal with it before it messes with your model’s performance.
Retraining the Model
Sometimes, the best solution to data drift is simple: retrain your model. But here’s the deal—you don’t want to retrain it too often or too late. There’s a sweet spot, and here are a few approaches you can take to make sure your model stays fresh:
Automated Re-training Pipelines
You’ve probably thought, “What if I could just automate all this?” Good news—you can. By setting up automated re-training pipelines, you can schedule model re-training based on either time intervals (e.g., retrain every week or month) or performance triggers (e.g., when accuracy drops below a certain threshold). This way, you’re not waiting until things get bad—you’re proactively staying ahead of the drift. It’s like setting your model on auto-pilot while still keeping an eye on the dashboard.
Incremental Learning
Imagine this: your model updates itself in real-time without needing to start from scratch every time. That’s exactly what incremental learning does. It’s particularly useful for time-series data or streaming data where the data evolves continuously. Instead of retraining on the entire dataset, the model only learns from new data. This keeps the model agile and adaptable, without the overhead of full retraining.
Feature Engineering Adjustments
Here’s something a lot of people overlook—sometimes it’s not the model that needs retraining; it’s the features. Think of your features as the inputs to your model’s brain. If the world around them is changing, they need to change too. By dynamically adjusting your feature engineering, you ensure that your model stays relevant. For example, if you’re predicting user engagement, you may need to add or drop features based on new trends (like sudden shifts in user behavior).
Using Ensemble Methods
If your data is constantly shifting, why rely on a single model? This is where ensemble methods come into play. Techniques like bagging or boosting allow you to combine multiple models, each specializing in different parts of the data. Think of it as having a team of experts, each tackling different problems. When one model doesn’t work, another can pick up the slack, making the overall system more resilient to data drift.
Adaptive Learning Models
Let’s get a bit futuristic for a moment. You’re dealing with a world where your model doesn’t just learn once—it keeps learning, even after deployment. Adaptive learning models, like those based on reinforcement learning, adjust their internal weights dynamically based on new data they encounter. Think of it as your model constantly refining itself, just like a human adjusting their behavior based on feedback.
Techniques to Handle Model Drift
Alright, so we’ve covered handling data drift, but what about model drift? Even if your data is fine, your model itself can degrade over time, and when it does, you’ve got to be ready to jump in and fix it.
Regular Model Evaluation and Tuning
You might be tempted to “set it and forget it,” but here’s the truth: regular evaluation is your best friend. Whether it’s weekly or monthly, you need to schedule regular check-ups on your model’s performance. During these evaluations, you’ll want to check key metrics like accuracy, precision, or F1 score. If you detect a drop, it’s time to take action—whether that’s tuning hyperparameters or retraining the model.
Updating Model Architecture
You might be wondering, “What if the problem isn’t with my data but with the model itself?” Sometimes, your model architecture simply outgrows its usefulness. For instance, what worked as a shallow neural network a year ago might now need a deeper, more complex architecture to handle today’s data. By updating the model architecture, you can introduce more robustness and adaptability, ensuring that the model remains efficient and accurate over time.
Active Learning Approaches
Here’s an interesting one—what if your model could learn from user feedback? That’s where active learning comes in. In an active learning system, your model actively seeks out data points it’s uncertain about and asks for human labels. This is particularly useful in situations where new data comes in, but you don’t have labels right away. Think of it as giving your model a direct line to an expert (or your users) for real-time learning.
For example, in a fraud detection system, if your model flags a transaction as potentially fraudulent, you could send it for human review. The feedback it receives helps fine-tune its decision-making process moving forward.
Transfer Learning
Imagine you don’t want to build a model from scratch every time there’s drift. Transfer learning is the answer. By leveraging a pre-trained model—whether it’s from your own archives or from a public repository—you can adapt it to new data patterns quickly. Transfer learning works particularly well when you have limited new data but want to capitalize on the strengths of an already well-trained model. It’s like handing over your model a new toolkit without making it start from scratch.
Conclusion
As you can see, data drift and model drift are more than just technicalities—they’re silent killers of machine learning model performance, especially when left unchecked. While your model may work perfectly in a test environment, the real world is constantly shifting. Whether it’s subtle changes in user behavior, evolving market trends, or unexpected events, your data and model must be equipped to handle this flux.
By now, you understand that detecting drift is only half the battle. You’ve got the tools and techniques to not only identify drift but also to respond effectively. From automated re-training pipelines to advanced techniques like adaptive learning and transfer learning, there’s no reason for your models to lose relevance over time.
The key takeaway? Monitoring and maintenance are just as important as building your model. Think of your machine learning model like a high-performance car—it needs regular check-ups, upgrades, and adjustments to keep it running smoothly. Whether you’re working with a simple classification model or a complex neural network, maintaining your model’s accuracy and reliability is an ongoing process, not a one-time task.
So, as you move forward, stay proactive. Set up the right monitoring systems, schedule regular evaluations, and remain flexible with your approach. Drift doesn’t have to spell disaster for your model—if you’re prepared, it becomes just another challenge to overcome in the ever-evolving world of machine learning.