
What are Activation Functions in Neural Networks?
Let’s start with a simple analogy: imagine your brain trying to make a decision. When you touch something hot, your brain doesn’t just sit idle; it reacts and sends a signal to pull your hand away. Now, think of activation functions as the neurons in your brain—they decide whether a neural network should fire a signal or remain silent, based on the input it receives.
In neural networks, we rely on these activation functions to help the model make decisions. They are the gatekeepers, determining whether the input is relevant enough to pass through to the next layer. Without activation functions, our neural networks would be nothing more than basic linear regression models—bland, lacking depth, and unable to capture the complex relationships that make deep learning so powerful.
Why Activation Functions Matter
Here’s the deal: neural networks are designed to learn patterns. Whether you’re training a model to recognize faces, detect anomalies, or even predict the stock market, these networks need to process a vast amount of data. This is where activation functions come into play—they introduce non-linearity into the system. In simpler terms, they give neural networks the flexibility to understand and map more complex patterns, which linear models just can’t do.
Think about it like this: if you were only allowed to draw straight lines, could you accurately map the curves and bends of a mountain trail? Probably not. Similarly, without activation functions, a neural network wouldn’t be able to map the twists and turns of real-world data.
The Purpose of This Article
By now, you might be wondering, “Okay, I get that activation functions are important, but what exactly will I learn here?”
Well, I’ve got you covered. In this article, we’ll dive deep into the world of activation functions. We’ll explore what they are, why they matter, and how they work. From the old-school functions like Sigmoid and Tanh to modern advancements like ReLU and Swish, you’ll come away with a clear understanding of when and why to use each one.
As deep learning continues to evolve, so does the importance of mastering concepts like activation functions. Whether you’re a budding machine learning enthusiast or an experienced data scientist, understanding these functions is crucial to building robust and efficient models.
In today’s AI-driven world, deep learning has permeated industries like healthcare, finance, and even entertainment. The ability to create smart algorithms is no longer a niche skill but a must-have. This article will help you stay ahead of the curve by deepening your understanding of one of the most fundamental aspects of neural networks.
So buckle up! By the end of this article, you’ll not only know what activation functions are but also how they can make or break your deep learning projects.
What is an Activation Function?
Let’s get to the heart of it: what exactly is an activation function, and why should you care?
Imagine neurons in your brain—each one deciding whether to pass a signal based on the information it receives. Neural networks work the same way. Activation functions are what determine if a neuron should “fire” and pass its output forward to the next layer. In simple terms, they allow the network to learn and represent complex patterns by transforming inputs into outputs that the network can process.
Here’s where things get interesting: without activation functions, a neural network would just be a series of linear operations, meaning no matter how many layers you add, it would still behave like a basic linear regression. That would be like trying to solve a jigsaw puzzle using only straight edges—definitely not going to work for those curved pieces! This is why activation functions are so critical. They inject the non-linearity that allows neural networks to handle real-world, complicated data.
How Activation Functions Work
Here’s the deal: when a neuron receives an input, it performs a calculation—usually a weighted sum of the inputs—and then passes that result to the activation function. The activation function steps in and decides, “Should I pass this value on, or should I squash it down to zero?”
You might be wondering how this decision-making process happens. The activation function takes the weighted input and transforms it, often squeezing it into a smaller range (like between 0 and 1, or -1 and 1) to keep the numbers manageable and meaningful. This transformation makes sure the network doesn’t end up with runaway values that explode out of control.
Types of Activation Functions: A Brief Overview
When it comes to activation functions, it’s important to understand that not all are created equal. Some activation functions have been around since the early days of neural networks, while others have emerged more recently as deep learning has advanced. Each activation function serves a unique purpose and comes with its own strengths and weaknesses.
Broadly speaking, activation functions can be divided into two categories:
- Linear vs. Non-linear – Linear functions don’t add much complexity, while non-linear ones allow networks to model intricate relationships.
- Differentiable vs. Non-differentiable – Differentiability is key in backpropagation, where the network adjusts weights to minimize errors.
Now, let’s break down some of the most commonly used activation functions, step by step.
3.1. Step Function
The Step Function is like the “on/off” switch of neural networks. It’s binary—either the neuron activates (outputs 1) or it doesn’t (outputs 0), depending on whether the input crosses a certain threshold.
Here’s how it works: If the input xxx is greater than a set threshold (often 0), the neuron outputs 1. Otherwise, it outputs 0.
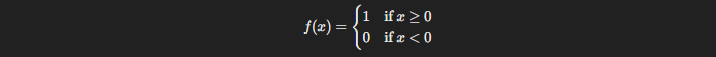
Use Case
The Step Function was widely used in early neural networks and perceptrons. Back then, the idea was simple—if something crossed a threshold, it was considered important.
Limitations
Here’s the problem: The Step Function doesn’t have a gradient. That means you can’t use it for backpropagation, which is essential for training modern deep learning models. Without a gradient, the network can’t learn, making this function largely obsolete in today’s applications.
3.2. Sigmoid Function
The Sigmoid Function is a classic. If you’ve been around neural networks for a while, you’ve probably seen it. The Sigmoid function squashes its input into a range between 0 and 1, making it useful for models where we need probabilities.
Here’s the formula:
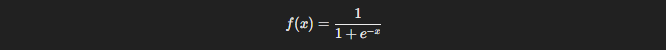
Advantages
- Smooth gradient: Unlike the Step Function, the Sigmoid function has a smooth, differentiable curve, making it useful in backpropagation.
- Bounded output: The output is between 0 and 1, which makes it ideal for tasks where probabilities are needed, like binary classification.
Limitations
Now, here’s the catch: the Sigmoid function suffers from the vanishing gradient problem. As the input moves far from 0 (either positively or negatively), the gradient becomes incredibly small. This makes learning slow or, in some cases, ineffective for deep networks.
Use Cases
You’ll often find Sigmoid used in early neural networks and binary classification tasks—when you’re trying to determine whether something belongs to one of two categories.
3.3. Hyperbolic Tangent (Tanh)
The Tanh function is like the cooler sibling of Sigmoid. It’s very similar but scales the output to a range between -1 and 1, which means it’s zero-centered.
Here’s the formula:
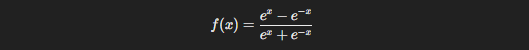
Advantages
- Zero-centered output: Unlike Sigmoid, where the output is always positive, Tanh allows negative outputs, which can make optimization easier.
- Stronger gradients: Because Tanh outputs values between -1 and 1, it can provide stronger gradients during backpropagation, which can help with learning.
Limitations
Like Sigmoid, Tanh isn’t immune to the vanishing gradient problem. As the input gets larger or smaller, the gradients start to shrink toward zero.
Use Cases
Tanh is often used in tasks where you need both negative and positive outputs, such as in certain types of regression or when your model benefits from having zero-centered data.
3.4. ReLU (Rectified Linear Unit)
Here’s the activation function that took the deep learning world by storm: ReLU. Unlike Sigmoid or Tanh, ReLU is incredibly simple and efficient. It outputs the input directly if it’s positive and zero otherwise.
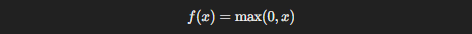
Advantages
- Efficient computation: ReLU is lightning fast, which is critical when training deep networks.
- Mitigates vanishing gradient: Since it doesn’t squash large inputs like Sigmoid or Tanh, ReLU is far less likely to suffer from vanishing gradients.
Limitations
But it’s not all perfect. You might run into the “dying ReLU” problem—when neurons get stuck outputting zero for every input, especially with negative values, and they stop learning altogether.
Variants
- Leaky ReLU: It allows small negative values, so the neuron doesn’t completely die.
- Parametric ReLU (PReLU): The negative slope is learned, which can make the function more adaptable.
- Randomized ReLU (RReLU): A random slope is assigned to negative inputs during training.
Use Cases
ReLU is everywhere in modern deep learning, from Convolutional Neural Networks (CNNs) used in image processing to Recurrent Neural Networks (RNNs) used in time-series analysis and natural language processing.
3.5. Softmax Function
If you’re working with multi-class classification problems, the Softmax Function is your go-to. Softmax takes a vector of inputs and converts them into probabilities that sum to 1, which is essential when you need to assign a sample to one of several categories.
Here’s the formula:
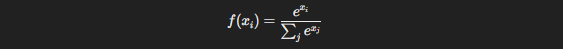
Advantages
- Useful for multiclass problems: Softmax helps break down the decision-making process when you have more than two classes.
- Probabilities: It converts raw scores (logits) into probabilities, making interpretation easy.
Limitations
One downside is that Softmax can be computationally expensive in larger networks. Also, like other activation functions, it can suffer from gradient issues in deeper layers.
Use Cases
Softmax is almost exclusively used in the output layer of a network for multi-class classification tasks like recognizing handwritten digits or categorizing images into distinct classes.
Advanced Activation Functions
Now that you’ve got the basics down, let’s dive into some of the more advanced activation functions. These are the cutting-edge tools in a deep learning practitioner’s toolkit, designed to address specific limitations of older functions like ReLU and Sigmoid.
The functions we’ll explore here—Swish, GELU, and Mish—represent newer advancements in the field of deep learning. You’ll often find these used in high-performance models where every percentage improvement in accuracy counts.
4.1. Swish Function
You might be familiar with Google’s reputation for innovation in AI, and the Swish function is one of their contributions. Developed by researchers at Google, Swish is mathematically defined as:
f(x)=x⋅sigmoid(x)
At first glance, you might notice that Swish looks like a combination of the Sigmoid function with a linear factor of xxx. That’s exactly right! Swish takes the smoothness of Sigmoid and multiplies it by the input itself, which results in a flexible and adaptive activation function.
Advantages
Swish has a couple of interesting perks. First, it’s got smooth gradients, which help the network learn better during backpropagation. The smoothness allows for a more efficient gradient flow, reducing the chances of getting stuck in local minima during training.
Here’s the kicker: Swish consistently outperforms ReLU in certain deep learning models, especially in deeper networks. It enables a model to capture more complex interactions without sacrificing too much speed.
Limitations
However, Swish is computationally more expensive than ReLU. This complexity comes from the additional Sigmoid calculation, which can slow things down, particularly in very large-scale applications.
Use Cases
You’ll find Swish used in advanced deep learning models, particularly those where small boosts in performance are worth the computational trade-off. It’s especially helpful in scenarios where a smooth and continuous activation function can make a difference, such as in image recognition and natural language processing.
4.2. GELU (Gaussian Error Linear Unit)
Next up, we have GELU, which might sound a bit complex at first, but don’t worry—it’s surprisingly intuitive once you get the hang of it.
Mathematically, GELU is similar to ReLU, but instead of simply applying a threshold (like ReLU does with zero), it applies a smooth probabilistic function:
f(x)=x⋅P(X≤x)
Where P(X≤x)P(X \leq x)P(X≤x) is the cumulative distribution function (CDF) of the Gaussian distribution. Essentially, GELU applies a probabilistic approach to decide how much of the input passes through based on its value.
Advantages
Here’s the exciting part: GELU doesn’t just threshold inputs; it applies a smooth function that weights the output according to its significance. This results in better gradient flow compared to ReLU. Because of this, GELU empirically outperforms ReLU in several tasks, especially in Natural Language Processing (NLP).
In fact, if you’ve heard of BERT, one of the most famous transformer models, you’ve encountered GELU. It’s used in models like BERT because of its ability to capture subtle variations in data, which is crucial for complex tasks like language understanding.
Use Cases
You’ll often find GELU in transformer models and other cutting-edge NLP architectures. Its ability to handle the complexities of natural language data makes it the go-to activation function for state-of-the-art language models.
4.3. Mish
You might not have heard of Mish as much as the others, but trust me, it’s gaining traction in deep learning circles for good reason. Mish is related to Swish but with some improved properties that make it even more attractive for certain high-performance tasks.
Mathematically, Mish is defined as:
f(x)=x⋅tanh(softplus(x))
Here, softplus(x) is another smooth activation function that’s similar to ReLU but softer around the edges.
Advantages
What makes Mish special is its smoothness and gradient flow. Similar to Swish, it maintains a continuous curve that prevents sharp transitions, which is excellent for gradient-based optimization. However, Mish has been found to provide even better performance in some tasks by offering improved gradient flow and less signal distortion.
Mish’s ability to smoothly handle negative inputs (unlike ReLU) also gives it an edge in certain deep learning models, particularly where handling complex and varied data distributions is critical.
Use Cases
Mish shines in high-performance deep learning networks, especially in areas like image classification and reinforcement learning. When you’re looking to squeeze every last drop of performance from your model, Mish might just be the key to unlocking it.
Comparative Analysis of Activation Functions
Now that we’ve explored individual activation functions, it’s time to compare how they stack up against each other. This section will help you understand the trade-offs you’re making when choosing one activation function over another, and how those choices affect performance, speed, and learning efficiency.
Performance in Deep Learning Models
When you’re building a deep learning model, the activation function you choose can have a massive impact on your results. Some functions are optimized for speed, while others are more focused on accuracy or gradient flow. Let’s break it down:
ReLU vs. Swish
You might be wondering, “Why not always use ReLU since it’s fast?” Well, here’s the deal: ReLU is incredibly efficient, which is why it’s become the default choice for most models. It doesn’t have the computational overhead of more complex functions, and it avoids the vanishing gradient problem that plagues Sigmoid and Tanh. But when you start going deeper into your network, ReLU’s performance can plateau, especially in cutting-edge tasks. That’s where Swish comes in.
Swish, although a bit more computationally expensive, offers better gradient flow, particularly in deeper models. Studies have shown that Swish outperforms ReLU in models like EfficientNet (a family of convolutional neural networks) because its smoother gradient helps the model learn more effectively over time【source needed】.
Sigmoid vs. Softmax
Sigmoid is perfect when you’re dealing with binary classification problems—it outputs probabilities between 0 and 1. But when you’ve got multiple classes, Softmax is the better option. Softmax normalizes the outputs into probabilities across multiple classes, making it ideal for multi-class classification. Think of it like this: Sigmoid is your go-to when you need a yes-or-no answer, while Softmax helps when you’re deciding between multiple categories, like distinguishing between cat, dog, or bird in an image.
Empirical Benchmarks
Various studies have benchmarked these activation functions in terms of their speed and accuracy. For example, in tasks like image classification and NLP, Swish and GELU tend to outperform ReLU in deeper networks due to their smoother gradients.
Trade-offs Between Activation Functions
Choosing the right activation function is all about understanding the trade-offs:
- Speed vs. Accuracy: ReLU is fast and efficient, making it ideal for real-time applications where computational cost is a concern. However, for deeper or more complex networks, Swish and Mish can offer better accuracy at the expense of speed.
- Gradient Flow: Functions like ReLU can suffer from the dying neuron problem, where neurons stop learning if they consistently output zero. In contrast, GELU and Swish offer smoother gradients, leading to better learning in deeper layers, particularly in tasks like natural language processing.
- Non-linearity vs. Simplicity: Sigmoid and Tanh introduce non-linearity but can suffer from vanishing gradients, slowing down training. ReLU, while simple, often needs variants (like Leaky ReLU) to handle certain edge cases, while Swish and Mish inherently provide more nuanced non-linearity without these issues.
You might be asking yourself, “When should I use which?” Here’s a quick breakdown:
- ReLU: Fast, good for most tasks unless you’re dealing with deeper networks where gradient flow becomes critical.
- Swish: Ideal for deep networks or tasks that require nuanced learning, like image classification or NLP models.
- Sigmoid: Use for binary classification, but watch out for vanishing gradients.
- Softmax: Best for multi-class classification problems, like recognizing multiple objects in an image.
Impact on Gradient Descent
The activation function you choose directly affects gradient descent—the optimization algorithm that helps your model learn. Gradient descent relies on the derivative (or slope) of the activation function to update weights. So, if your activation function squashes inputs too much (like Sigmoid or Tanh), you end up with tiny gradients, leading to slow learning. This is known as the vanishing gradient problem.
ReLU’s Impact
ReLU is popular because it maintains large gradients for positive inputs, ensuring faster convergence during gradient descent. However, when your inputs are negative, ReLU outputs zero, causing the dying neuron problem. This can be detrimental to your model’s learning process, as certain neurons may become inactive and stop contributing to the learning process.
Swish and GELU’s Impact
Here’s where Swish and GELU shine. These activation functions offer smooth and continuous gradients, which improve the learning process, especially in deep networks. Swish, in particular, doesn’t suffer from the same dying neuron issue that plagues ReLU. Instead, it offers a soft, continuous gradient that helps models converge more smoothly.
Trade-off in Computational Complexity
While functions like ReLU are computationally cheaper (no exponentials involved), more advanced functions like Swish and GELU are computationally expensive but deliver better gradient flow. In practical terms, this means your model might take a bit longer to train but will learn more effectively and yield better results in the long run.
To sum up, choosing an activation function isn’t just about blindly following defaults. It’s about understanding the trade-offs between speed, gradient flow, and computational complexity. As a rule of thumb:
- Go with ReLU for most tasks, especially when speed is a priority.
- Consider Swish or GELU for deeper models where performance matters more than training time.
- Use Sigmoid for binary classification and Softmax for multi-class classification.
Armed with this knowledge, you’ll be in a stronger position to select the best activation function for your specific deep learning model, ensuring your model trains efficiently and performs at its best.
Conclusion
As we wrap up this deep dive into activation functions, let’s take a moment to reflect on what we’ve learned. Activation functions are the backbone of neural networks, transforming raw inputs into meaningful outputs that drive a model’s learning. Without them, our models would be limited to simple, linear mappings that fail to capture the complexities of real-world data.
From the traditional Sigmoid and Tanh functions to the more modern and powerful ReLU, Swish, GELU, and Mish, each activation function serves a unique purpose. While some, like ReLU, are designed for speed and efficiency, others, like Swish and Mish, excel in complex, high-performance models where gradient flow is crucial.
Here’s the bottom line: the choice of activation function depends on the task at hand. If you’re building a quick, real-time system, ReLU might be your best bet. But if you’re working on deep, cutting-edge models—like NLP systems or advanced computer vision tasks—consider trying out more advanced options like Swish or GELU to squeeze out better performance.
In deep learning, no one-size-fits-all solution exists. Experimentation is key. I encourage you to test different activation functions, benchmark their performance in your specific use case, and adjust accordingly. As the field of AI continues to evolve, so will activation functions, and staying on top of these developments will keep you ahead in the game.
Remember: choosing the right activation function can be the difference between a model that just “works” and one that excels. Happy experimenting, and may your neural networks fire on all cylinders!