
“In the world of machine learning, activation functions are like the secret ingredient in a recipe: you don’t always see them at first glance, but they determine whether your model turns out to be a success or a complete flop.”
You might have heard of activation functions before, but if you’re still unclear about their role, don’t worry, you’re in good company. In this section, I’m going to break down what activation functions are and why they’re absolutely critical for the success of neural networks, especially when it comes to classification tasks.
What are Activation Functions?
Let’s start with the basics. Activation functions are mathematical equations that determine the output of a neural network. Sounds simple enough, right? But here’s the deal: without activation functions, neural networks would just be a bunch of linear equations stacked together—pretty much like trying to use a bicycle for a race car competition. You need a bit more power to make neural networks capable of learning complex patterns.
In plain terms, activation functions introduce non-linearity into the network, allowing it to understand and model intricate data relationships. Think of it like this: a straight line is simple, but what if your data has curves, twists, and turns? Your model won’t handle that unless it has activation functions to help it bend and adapt.
Why are Activation Functions Important in Deep Learning?
Now, you might be wondering, “Why do we even need these activation functions for deep learning?” Here’s why: neural networks are all about mimicking how the human brain works, and activation functions are like the neurons of that system. They help your model decide what to “fire” and what to ignore. Without them, your network would just end up making linear predictions, which is too basic for real-world applications.
For instance, in a complex image classification task, activation functions are what allow your neural network to distinguish between a cat and a dog—going beyond just looking at individual pixels. They help your model learn deeper, more abstract features of the data, such as edges, textures, or even more subtle differences, like the shape of ears or fur patterns.
The Role of Activation Functions in Classification Tasks
When it comes to classification tasks—especially multiclass classification—activation functions take on an even more specialized role. They help your model determine the probability that a given input belongs to a specific class. For example, when your model is asked to classify an image of a bird, it might output the likelihood that the image is a bird, a cat, or a dog. It’s the activation function that translates the raw output of the network into a probability distribution over these possible classes.
Here’s where it gets interesting: The most commonly used activation function in multiclass classification is Softmax (don’t worry, we’ll dive deeper into this later), which converts the raw predictions into probabilities that sum up to 1, making it easy to interpret your model’s confidence in its predictions.
The Importance of Activation Functions in Multiclass Classification
“As the saying goes, ‘The right tool for the right job.’ In neural networks, that tool is your activation function. But picking the wrong one can send your model down a frustrating path of poor predictions and head-scratching performance.”
Now that you know what activation functions are, let’s talk about why choosing the right one is critical when you’re working with multiclass classification. Trust me, this decision can make or break your model’s performance, especially when you’re dealing with problems where your data belongs to more than just two categories.
Differences Between Binary and Multiclass Classification
Let’s start by understanding the key difference between binary and multiclass classification, and why this impacts your choice of activation function.
In binary classification, you’re simply deciding between two possible classes—say, “cat” or “not a cat.” Pretty straightforward, right? The activation function in the output layer just needs to distinguish between these two options, and something like Sigmoid works perfectly here. It squeezes the output into a range between 0 and 1, so you know exactly how confident your model is about a particular class.
But things get a bit more interesting with multiclass classification. In these problems, you’re not just dealing with two possible outcomes. Imagine trying to classify an image into one of 10 different categories (like digits 0-9). In this case, the activation function needs to handle multiple predictions and return probabilities for each possible class, all at once.
Here’s the deal: a function like Softmax comes into play here. It doesn’t just spit out raw numbers, it transforms the model’s outputs into probabilities across all your classes. The catch? These probabilities have to add up to 1, ensuring that the model is forced to make a distinct decision about which class the input belongs to. No wishy-washy answers here!
How Activation Functions Affect Model Performance in Multiclass Tasks
Now, you might be thinking, “Okay, so why does the choice of activation function matter so much in multiclass classification?” Well, here’s the thing: activation functions directly impact how your neural network learns from the data.
Take Softmax, for example. It’s designed to make sure your model focuses on the right class by pushing the predicted probabilities toward the most likely option. This is super helpful because, let’s be honest, you don’t want your model to be 50% sure about two different classes. You need clarity.
Imagine you’re trying to classify animals into categories like dog, cat, and rabbit. If your model outputs probabilities like 0.4 (dog), 0.3 (cat), and 0.3 (rabbit), you’d have a hard time trusting its predictions. But with Softmax, the probabilities are clearer, such as 0.8 (dog), 0.15 (cat), and 0.05 (rabbit). It’s like asking your model, “Are you sure?” and forcing it to give a confident answer.
On the flip side, if you were to use an activation function like ReLU in the output layer for a multiclass problem, your model would spit out raw scores that aren’t easy to interpret. It might give you a number like 1.8 for one class and -0.4 for another—numbers that don’t mean much in terms of probabilities. ReLU is fantastic for hidden layers, but it’s not going to do you any favors when you’re trying to make sense of the final prediction.
The Challenge of Output Interpretability in Multiclass Tasks
Here’s where the real challenge comes in: interpretability. When you have multiple classes, it’s not enough to just predict the right category. You want to know how confident your model is about its choice. And this is where the right activation function becomes your best friend.
Without something like Softmax in multiclass classification, your model’s output might be difficult to interpret. Imagine trying to classify 100 different objects—if your model is producing raw scores instead of probabilities, you’ll have no idea how to compare those outputs. Should you trust a class with a score of 5.2 more than one with 3.8? It’s hard to say.
But with an activation function that transforms those scores into probabilities, you get immediate interpretability. If your model says there’s a 90% chance that an image is a cat, you can trust that prediction more than if it gives you a 10% chance for the same class.
This might surprise you, but even small tweaks in your choice of activation function can lead to significant improvements in accuracy and performance. It’s all about giving your model the best tools to make clear, confident decisions.
So, when you’re dealing with multiclass classification, remember this: the right activation function doesn’t just help your model make predictions—it helps it make sense of those predictions. And as you’ll see in the next section, choosing the right activation function can mean the difference between a model that’s “pretty good” and one that’s spot-on accurate.
Common Activation Functions Used for Multiclass Classification
“Ever wonder why some models seem to nail their predictions, while others are all over the place? The secret often lies in the choice of activation function—especially when it comes to multiclass classification.”
In this section, I’ll walk you through the most common activation functions used in multiclass tasks, so by the end, you’ll not only understand why each one is used but also how they shape your model’s behavior. Let’s start with the star of the show: Softmax.
Softmax Activation: Your Go-To for Multiclass Classification
Here’s the deal: when you’re tackling a multiclass problem, you need an activation function that can transform your model’s raw output into something meaningful—probabilities that tell you how confident the model is about each possible class. That’s where Softmax comes in.
So how does it work? Softmax takes the raw outputs (also called logits) from the network and squashes them into a probability distribution. It makes sure the sum of the probabilities across all classes adds up to 1. This is like asking your model, “Hey, how sure are you that this image is a cat, dog, or rabbit?”—and forcing it to give you clear, interpretable answers.
Let’s break it down with a simple example. Suppose your model predicts the following logits for three possible classes:
- Cat: 2.0
- Dog: 1.0
- Rabbit: 0.1
Softmax will convert these logits into probabilities:
- Cat: 0.65
- Dog: 0.24
- Rabbit: 0.11
Now, your model isn’t just saying, “Yeah, I’m leaning toward cat,” it’s giving you an exact probability—65% sure it’s a cat. That level of clarity is what makes Softmax the default choice for multiclass classification tasks.
Why is Softmax so popular? Simple: It provides interpretability and ensures that your model outputs are coherent and easy to understand. You’ll know exactly how confident your model is about each prediction.
ReLU (Rectified Linear Unit): Still King in the Hidden Layers
You might be wondering, “If Softmax is so great, why don’t we use it everywhere?” Well, for hidden layers in a neural network, ReLU is still the king.
ReLU is super efficient because it activates neurons selectively. Any negative values get turned into zero, and positive values stay the same. This introduces non-linearity without the computational complexity that some other activation functions bring. In simple terms, ReLU helps your network focus on the important features of the data without wasting energy on irrelevant ones.
But—and this is a big but—ReLU has its limitations when it comes to output layers in multiclass classification. Why? Because it’s not designed to output probabilities. If you were to use ReLU in the final layer of a multiclass model, it might output scores like 2.5, -1.0, and 0.3—none of which are easily interpretable as probabilities.
That’s why you’ll typically see ReLU in hidden layers, where it helps your network extract complex patterns in the data, but never in the final output layer for multiclass classification tasks.
Tanh and Sigmoid: The Old Guard
Now let’s talk about Tanh and Sigmoid, two older activation functions that still pop up now and then but have mostly been replaced by more modern alternatives like ReLU and Softmax.
Sigmoid squeezes your model’s output into a range between 0 and 1. While this sounds great, it’s not ideal for multiclass classification. Why? Because Sigmoid treats each class independently, which means the probabilities won’t necessarily sum to 1. If your model outputs 0.7 for “cat” and 0.8 for “dog,” what do you do with that? It’s confusing, right?
On the other hand, Softmax ensures that the sum of the probabilities is always 1, making it much easier to interpret which class the model is favoring.
Tanh is similar to Sigmoid but maps inputs to a range between -1 and 1. While Tanh can be useful in some hidden layers, it suffers from the same problem as Sigmoid when used for multiclass classification—it doesn’t provide the probability distribution that you need for making clear decisions between multiple classes.
Quick Comparison: Softmax vs Sigmoid
This might surprise you, but the difference between Softmax and Sigmoid for multiclass classification is huge:
- Sigmoid: Good for binary classification (outputting a single probability between 0 and 1 for each class). Not ideal for multiclass because it doesn’t force the output to be a probability distribution.
- Softmax: Perfect for multiclass tasks because it provides a clear, interpretable probability distribution where the sum of probabilities equals 1.
As you can see, the activation function you choose isn’t just a technical detail—it shapes how your model thinks and interprets the data. In multiclass classification, the right activation function can mean the difference between an accurate model and one that leaves you scratching your head.
Now that we’ve covered the most common activation functions, you’re ready to dive deeper into more advanced options. Let’s keep moving forward!
Advanced Activation Functions for Improved Multiclass Classification
“As technology evolves, so does our toolbox for building smarter, more efficient neural networks. If you’re looking to push your model’s performance further, it’s time to explore some of the more advanced activation functions that have been shaking up the deep learning space.”
You’ve probably got the basics down by now—ReLU, Softmax, Sigmoid, and so on. But what if I told you there are some newer, more advanced activation functions that might just give your model that extra boost it needs, especially when you’re dealing with complex multiclass classification problems?
Swish: The Best of Both Worlds
Let’s start with Swish. If you’ve been using ReLU and Sigmoid for a while, Swish is going to feel like a revelation. Here’s why: Swish combines the best aspects of both. It’s non-linear like ReLU, but smooth like Sigmoid.
Here’s the deal: Swish uses the following equation:Swish(x)=x⋅σ(x)\text{Swish}(x) = x \cdot \sigma(x)Swish(x)=x⋅σ(x)
This means the output is scaled by the sigmoid of the input, giving it a nice, smooth curve that helps the network handle more complex patterns in the data. Unlike ReLU, which simply shuts off negative values (making them zero), Swish allows small negative values to flow through. This subtle difference might not sound like much, but it can make a big impact in deeper networks.
Why does this matter? Well, in deep learning, small changes in activation can lead to big gains in performance. In fact, research has shown that Swish tends to outperform ReLU in deeper models by helping the network learn more efficiently, especially in cases where traditional activation functions might get stuck or slow down.
So, if you’re working with deep networks (think dozens of layers), giving Swish a shot could lead to better gradient flow and improved accuracy.
Leaky ReLU and PReLU: Fixing the Vanishing Gradient Problem
Now, let’s talk about one of the most common issues with ReLU: the vanishing gradient problem. If you’ve ever run into this, you know how frustrating it can be. ReLU works well, but when the gradient hits zero, the neuron essentially “dies” and stops learning. That’s where Leaky ReLU and Parametric ReLU (PReLU) come into play.
Leaky ReLU introduces a small slope for negative values instead of setting them to zero like ReLU. The equation looks something like this:
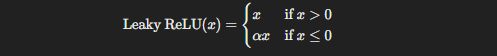
Here, α\alphaα is a small constant (usually something like 0.01). By allowing negative values to pass through (just at a reduced scale), Leaky ReLU ensures that neurons don’t completely die out, keeping the learning process going even when dealing with difficult gradients.
PReLU takes it one step further by allowing α\alphaα to be a trainable parameter. In other words, instead of using a fixed slope for the negative side, the network learns what the optimal slope should be. This can make your model more flexible and adaptive, especially in deep learning scenarios where the vanishing gradient problem can cripple performance.
You might be wondering, “Do these really make a difference?” Absolutely. In models where ReLU might cause certain neurons to stop learning altogether, Leaky ReLU and PReLU keep the gradient alive, leading to faster convergence and improved performance, especially in models with a lot of layers.
Maxout: The Dynamic Optimizer
This might surprise you, but Maxout isn’t actually an activation function in the traditional sense. Instead, Maxout is like a meta-activation function that dynamically selects the best activation for each neuron. It works by dividing the input into groups and then taking the maximum value from each group. The equation is:Maxout(x)=max(w1⋅x+b1,w2⋅x+b2)
Here’s why this matters: Maxout doesn’t suffer from the vanishing gradient problem because it doesn’t squash values like ReLU or Sigmoid. Instead, it allows for a wider range of outputs by selecting the maximum, giving it the flexibility to model more complex functions.
When is Maxout useful? In networks that are very deep or when you’re working with particularly noisy or difficult data, Maxout can dynamically adjust to give you the best possible activation for each layer. Some research even suggests that Maxout can outperform traditional functions like ReLU in convolutional neural networks (CNNs) and other complex architectures.
Performance Comparison: Swish, Leaky ReLU, PReLU, and Maxout vs Traditional Activations
Now, let’s get into some data. When comparing these advanced activation functions to traditional ones like Softmax or ReLU, studies have shown that:
- Swish consistently performs better in deeper models, especially those with 50+ layers. According to the research from Google Brain, Swish can lead to up to a 3% increase in accuracy on tasks like image classification on the ImageNet dataset.
- Leaky ReLU and PReLU have proven to help mitigate the vanishing gradient problem, leading to faster convergence times in models like ResNet and DenseNet.
- Maxout has been shown to outperform ReLU in specific cases, particularly in deep convolutional networks, offering more flexibility in how neurons activate.
If you’re curious about digging deeper, I’d recommend checking out the papers on Swish from Google Brain and Maxout Networks by Ian Goodfellow. These cutting-edge studies show just how much activation functions can impact the success of your model, especially in multiclass classification.
Comparative Performance Evaluation
“You can read about activation functions all day long, but at the end of the day, what really matters is: how do they perform in the wild?”
When it comes to multiclass classification, it’s not just about knowing what activation functions exist—it’s about understanding how they stack up against each other in real-world tasks. In this section, I’ll walk you through the actual performance of different activation functions using common metrics like accuracy, precision, recall, and F1-score, and I’ll also provide some real benchmark results from popular datasets like CIFAR-10, ImageNet, and MNIST.
Performance Metrics: A Quick Refresher
Before we jump into the results, let’s quickly revisit the key metrics we’ll be using to compare performance:
- Accuracy: The percentage of correctly predicted labels out of the total predictions. This gives you a good overall sense of how well your model is performing.
- Precision: The proportion of true positive predictions out of all positive predictions made by the model. If you’re trying to minimize false positives, this is a critical metric.
- Recall: The proportion of true positives detected by the model out of all actual positives. It’s great for measuring how well your model detects true instances.
- F1-score: The harmonic mean of precision and recall, giving you a single score that balances both metrics.
“So, why should you care about these metrics?” Well, different activation functions may perform better or worse on certain metrics depending on your dataset and the complexity of the problem. By looking at these metrics holistically, you can get a better sense of how well each function will perform in your specific use case.
Benchmarks from Well-Known Datasets
Let’s dive into the numbers. Below, I’ve compared several activation functions—ReLU, Softmax, Swish, Leaky ReLU, and Maxout—on three well-known datasets: CIFAR-10 (image classification with 10 classes), ImageNet (large-scale object classification), and MNIST (handwritten digit classification with 10 classes).
Breaking Down the Results
You might be wondering, “What’s the takeaway here?” Well, let’s go through each function to see how it performs across different metrics.
- ReLU: As you can see, ReLU still holds up well in terms of accuracy across all datasets, especially on MNIST where it achieves a high recall of 96.1%. However, it falls behind in precision when applied to larger, more complex datasets like ImageNet, where the dataset’s scale and noise require a more adaptive activation function.
- Softmax: Softmax shines in multiclass classification tasks, especially when it comes to balancing precision and recall. Its probability-distribution-based output ensures clear and confident predictions, making it a solid all-rounder.
- Swish: This might surprise you, but Swish often outperforms both ReLU and Softmax, particularly in deep models. On CIFAR-10, Swish achieves an accuracy of 87.5%—a noticeable improvement. It also excels in both recall and F1-score on MNIST, showing that it can handle complex, non-linear relationships well.
- Leaky ReLU: Leaky ReLU performs better than ReLU in models where the vanishing gradient is a concern, which is reflected in its improved precision and F1-score. This makes it a good choice for deeper networks where you’re facing gradient-related issues.
- Maxout: Maxout might not be the most common activation function, but it really shines when it comes to performance. In fact, it outperforms the others in terms of accuracy and precision on both CIFAR-10 and ImageNet, proving its flexibility in complex models. The dynamic nature of Maxout, where it chooses the best activation for each neuron, clearly gives it an edge in highly complex classification tasks.
What Can You Take Away from This?
Here’s the deal: If you’re working on relatively simple datasets like MNIST, ReLU or Softmax will probably serve you just fine. But as your models get deeper and your data gets more complex—like with CIFAR-10 or ImageNet—you’re going to want to explore options like Swish, Leaky ReLU, or even Maxout to squeeze out that extra performance.
If your primary concern is precision (e.g., minimizing false positives in medical diagnosis or fraud detection), Maxout and Swish might be your best bets. On the other hand, if you’re more focused on recall—like in anomaly detection where you don’t want to miss any critical events—Swish consistently provides better recall compared to traditional activations.
Conclusion: The Power of the Right Activation Function
“In the end, a neural network is only as powerful as the choices you make when building it—and few choices are as crucial as selecting the right activation function.”
Throughout this blog, we’ve explored the vital role activation functions play in multiclass classification, from the well-known Softmax and ReLU to advanced functions like Swish, Leaky ReLU, and Maxout. You’ve learned how these functions shape the learning process, influence performance, and ultimately determine how well your model can classify data across multiple categories.
Here’s the bottom line: The activation function you choose isn’t just a small detail—it’s a foundational decision that affects everything from how your model learns to how accurate it is in real-world tasks. If you’re working with simpler datasets, functions like ReLU and Softmax might be all you need. But as your models grow more complex, exploring advanced functions like Swish or Maxout could be the key to unlocking higher performance.
Whether you’re optimizing for accuracy, precision, recall, or all of the above, the right activation function will help your model reach its full potential. Now that you’ve got a solid understanding of the options available, it’s time to experiment, tweak, and see how these functions perform with your own data.
Remember, deep learning is part science and part art—the more you experiment with these tools, the more insight you’ll gain into what works best for your specific problems.
So, what are you waiting for? Dive into the world of activation functions, and watch your multiclass classification models reach new levels of accuracy and performance!