
“The journey of a thousand miles begins with a single step.” — Lao Tzu. When it comes to machine learning, especially binary classification, that first step begins with understanding the problem at hand.
What is Binary Classification?
At its core, binary classification is a type of supervised learning where your model needs to distinguish between two possible outcomes—yes or no, true or false, spam or not spam. The beauty of binary classification lies in its simplicity: you’re working with just two labels. But as simple as it sounds, it’s the foundation for solving real-world problems.
Imagine you’re developing a spam filter for your email. Each incoming email needs to be classified as either “spam” or “not spam”—this is a binary classification task. Or consider a medical diagnosis model where the algorithm determines whether a patient has a certain disease (positive) or not (negative). These applications of binary classification are everywhere, from fraud detection in banking to predicting customer churn in businesses.
Now, you might be thinking, “Okay, I get what binary classification is, but what role do activation functions play?”
Importance of Activation Functions in Binary Classification
Here’s the deal: activation functions are the silent heroes of neural networks. They help your model make decisions, turning raw data into meaningful predictions.
Think of a neural network as a decision-making machine. The job of the activation function is to draw the line between the two classes you’re trying to separate. It does this by transforming the input (which is often a number) into a range that the model can interpret, like probabilities between 0 and 1. Without an activation function, your neural network would simply churn out linear combinations, and trust me, you don’t want that. Linear models aren’t flexible enough for real-world data complexities.
Take, for example, the sigmoid activation function. It’s like a gatekeeper—by squashing the output into a range between 0 and 1, it helps your model decide whether the prediction leans more towards “0” or “1,” which in binary classification terms could mean something like “safe” or “risky,” depending on your use case.
But that’s not all! The choice of activation function also impacts your model’s decision boundaries—the lines or curves it draws in the feature space to separate the two classes. A sigmoid might give you smooth, probabilistic boundaries, while functions like ReLU or Tanh could make them sharper or more complex. The activation function you choose ultimately determines how accurate your model is in making those binary decisions.
You might be wondering, “How do I know which activation function to choose?” That’s exactly what we’ll explore in the sections to come. But trust me, getting this right is crucial to achieving that sweet spot of model accuracy and efficiency.
Understanding Activation Functions
“You don’t really understand something unless you can explain it to your grandmother.” — Albert Einstein. Let’s put that to the test with activation functions, a concept that might seem technical at first but plays a vital role in your machine learning models.
What are Activation Functions?
Think of your neural network as a collection of neurons—each neuron takes inputs, processes them, and spits out an output. But here’s where the magic happens: without activation functions, the output of your neurons would just be a boring, linear combination of the inputs. In essence, your network would be as limited as a basic linear regression model.
Activation functions add a spark of non-linearity, and this non-linearity is crucial. Why? Because real-world data is complex. Let’s say you’re building a model to classify emails into spam or not spam. The decision-making process isn’t linear. Some emails might have certain keywords, but others could look suspicious based on combinations of features like the sender’s address or unusual patterns in the content. Activation functions allow your model to capture these complex relationships.
In simple terms, an activation function decides whether a neuron should be activated (i.e., fire) based on the input it receives. Without this, your model would never be able to learn patterns beyond straight lines. The purpose of the activation function is to give your model the ability to learn and represent intricate patterns in data, allowing it to make smarter, more accurate predictions.
Importance of Non-Linearity
Now, here’s something you’ll want to keep in mind: non-linearity is the secret sauce of activation functions. You might be wondering, “Why is this so important?”
Let me give you an analogy. Imagine trying to predict the path of a rocket using just a ruler. You can draw straight lines, sure, but rockets don’t fly in straight lines. They curve, they accelerate, they adjust their trajectory. To truly predict that path, you need a tool that understands those curves and twists. That’s what non-linear activation functions do—they give your neural network the flexibility to handle the complexity of real-world data, just like a rocket’s path.
Without non-linearity, no matter how deep your neural network is, it’s still going to act like a simple straight-line model. So, when you’re building a model to predict whether a customer will churn or not, it’s these activation functions that allow your network to capture non-linear relationships and improve accuracy.
How Activation Functions Work in Binary Classification
Now, let’s zoom in on binary classification. Here’s the deal: in binary classification, your model needs to predict one of two outcomes—either a “0” or a “1.” This is where the activation function steps in to transform the model’s raw output into something interpretable.
For example, let’s talk about the sigmoid function, one of the most commonly used activation functions in binary classification. The sigmoid function squeezes any input (which can range from negative infinity to positive infinity) into a number between 0 and 1. This output can then be interpreted as a probability, making it ideal for tasks where you need to decide between two possible outcomes.
Here’s a quick example to make it clear. Suppose your model outputs a value of 0.7 after processing some input. Using the sigmoid function, you can translate that value into a probability, meaning there’s a 70% chance that the input belongs to class 1 (e.g., “spam”) and a 30% chance that it belongs to class 0 (e.g., “not spam”). The model can then choose the class with the highest probability. This probabilistic interpretation is critical in applications like medical diagnoses, where you need to gauge the likelihood of a condition.
In short, activation functions like sigmoid are essential because they allow your binary classification model to output values that are easy to interpret, offering probabilities that guide decision-making. Without them, your model’s output would just be a raw number, and you’d have no clear way to interpret it.
So, next time you’re choosing an activation function, remember: you’re not just selecting a mathematical formula; you’re giving your model the power to think in probabilities, which is key to making accurate, real-world predictions.
Key Activation Functions for Binary Classification
“Numbers have life; they’re not just symbols on paper.” — Shakuntala Devi. And in the world of machine learning, activation functions breathe life into those numbers, helping you understand which ones to trust and which ones to ignore. Now let’s dive into the most commonly used activation functions and their role in binary classification.
3.1 Sigmoid Function
You’ve likely come across the sigmoid function before, and for good reason—it’s one of the simplest and most intuitive activation functions out there.
Mathematically, the sigmoid function is expressed as:
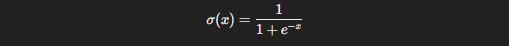
Here’s what makes it special: the output of the sigmoid function always lies between 0 and 1, making it perfect for binary classification tasks where you need to assign probabilities to outcomes. You can think of it as the translator between raw numbers and real-world decisions. For example, if your model predicts an output of 0.85 after applying the sigmoid function, you can interpret that as an 85% chance that the input belongs to the “positive” class.
Advantages:
- Probabilistic Output: The sigmoid’s ability to output values between 0 and 1 makes it ideal when you need to interpret predictions as probabilities—especially in tasks like logistic regression.
- Smooth Gradient: Sigmoid functions ensure that small changes in the input cause small changes in the output, which helps your model learn continuously during training.
But wait, it’s not all perfect.
Limitations:
- Saturation Problem: Here’s the catch—when the input values are too large or too small (extreme positive or negative), the sigmoid function tends to saturate. This means the gradient becomes almost zero, making it hard for the model to learn from the data.
- Vanishing Gradients: This leads us to the famous vanishing gradient problem, where the learning process becomes painfully slow, especially in deep networks.
So, while the sigmoid function is great for simple binary classification tasks, it might not be your best choice if you’re working with deep neural networks where vanishing gradients could become a serious bottleneck.
3.2 Tanh (Hyperbolic Tangent)
Now, let’s talk about tanh, which is like the cooler, more balanced sibling of sigmoid. Its formula looks like this:
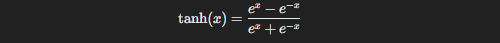
Unlike the sigmoid, the tanh function outputs values between -1 and 1. This makes it more “centered” around zero, which might not seem like a big deal at first, but it can be a game-changer when you’re dealing with data that includes negative inputs.
Advantages:
- Centered Outputs: One of the most significant advantages of tanh is that it deals with negative inputs more effectively than sigmoid. Since its output is centered at zero, tanh reduces the bias in the model’s predictions.
- Stronger Gradients: Compared to the sigmoid, tanh provides stronger gradients, which helps accelerate learning in some scenarios.
However, don’t get too excited just yet.
Limitations:
- Vanishing Gradient Problem (Again): Yes, tanh also suffers from the vanishing gradient issue when working with extreme values. If your inputs push the function towards its saturation zones, you’ll face similar learning slowdowns as with sigmoid.
In essence, if you’re looking for a more balanced alternative to sigmoid, especially when handling both positive and negative data, tanh is worth considering. But beware of the gradient problem—it lurks in the shadows here too.
3.3 ReLU (Rectified Linear Unit)
Here’s where things get exciting. ReLU, which is defined as:
ReLU(x)=max(0,x)
ReLU is simple, yet incredibly powerful. Unlike sigmoid or tanh, ReLU outputs zero for any negative input and simply passes the positive input as it is. This might surprise you, but this simplicity is precisely why ReLU works so well, especially in deep neural networks.
Advantages:
- Faster Convergence: Because ReLU doesn’t saturate like sigmoid or tanh, it avoids the vanishing gradient problem, allowing models to converge faster during training.
- Sparsity: Since ReLU outputs zero for all negative values, it introduces sparsity in the model, which can improve both training time and model efficiency.
But—there’s always a but.
Limitations:
- Dead Neurons: ReLU’s biggest issue is that it can create dead neurons. When a neuron consistently outputs zero, it effectively “dies” and stops learning altogether. This is particularly common when the input is mostly negative.
So, ReLU is a fantastic choice for deep networks, but you have to watch out for the dead neuron problem. Fortunately, we have a solution for that.
3.4 Leaky ReLU
Enter Leaky ReLU—ReLU’s improved version that helps fix the dead neuron problem. Its formula is:Leaky ReLU(x)=max(αx,x)
Where α\alphaα is a small positive slope, usually something like 0.01. In other words, instead of outputting zero for negative inputs, Leaky ReLU allows a small, non-zero gradient.
Advantages:
- No Dead Neurons: Leaky ReLU’s primary strength is that it avoids the dead neuron problem by keeping the gradient small but non-zero for negative inputs.
- Faster Training: Like ReLU, it accelerates the training process, making it a solid choice for deep learning.
However:
Limitations:
- Slightly More Computationally Expensive: Leaky ReLU introduces a small computational overhead because it has to handle the slope α\alphaα. It’s not a huge deal, but in large-scale models, every little bit counts.
Leaky ReLU is often the go-to option when you need the speed and efficiency of ReLU without the risk of neurons dying off.
3.5 Softmax Function (with Binary Use Case Focus)
Now, you might be thinking: “Isn’t Softmax for multi-class classification?” Yes, you’re right, but let’s talk about why Softmax can also be useful in binary classification under certain circumstances.
The Softmax function is defined as:
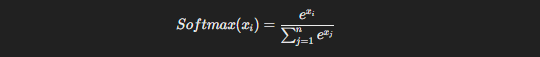
This function takes a set of raw output scores and turns them into a probability distribution, where the sum of probabilities across all classes equals 1. While typically used in multi-class problems, Softmax can be applied in binary classification tasks, especially when paired with log-loss.
Advantages:
- Probability Distribution: Softmax offers a clear probability distribution across all possible classes, which can sometimes be useful in binary classification if you need to compare the relative likelihood of two outcomes.
Limitations:
- Overkill for Binary Tasks: In most binary classification problems, Softmax is often unnecessary because simpler functions like sigmoid can do the job. It’s typically more useful when you have three or more classes to predict.
Conclusion
“The whole is greater than the sum of its parts.” — Aristotle. When it comes to binary classification, the activation function you choose is one of those critical “parts” that can dramatically affect your model’s overall performance.
Throughout this journey, we’ve explored some of the most commonly used activation functions—Sigmoid, Tanh, ReLU, Leaky ReLU, and even Softmax. Each of these functions brings something unique to the table, whether it’s the probabilistic interpretation of Sigmoid or the speed and efficiency of ReLU.
But here’s the takeaway: there’s no one-size-fits-all solution when it comes to activation functions. The best choice depends on your specific problem, the architecture of your neural network, and the characteristics of your data. For simple binary classification problems, Sigmoid is often the go-to option due to its probabilistic output. However, if you’re working with deep networks or more complex tasks, you might find that ReLU or Leaky ReLU gives you faster convergence and better overall results.
That said, you should always keep potential pitfalls like vanishing gradients or dead neurons in mind, as these can severely hinder your model’s learning process. The key is to experiment, tweak, and test. Machine learning is as much an art as it is a science, and sometimes the most effective solution is the one you least expect.
So, whether you’re building a spam filter, a fraud detection model, or even predicting customer churn, remember: your choice of activation function can make or break your model’s success. Choose wisely, and your model will reward you with accuracy, speed, and a better understanding of the data it’s processing.
Now, it’s your turn. Go ahead and test these functions in your next project, and watch as your binary classification models become sharper and more efficient than ever before. Happy coding!