
Let’s begin with the basics: the Hierarchical Dirichlet Process (HDP) is a non-parametric Bayesian method designed to model grouped data. Now, I know “non-parametric” might sound like something out of a statistics textbook, but don’t worry—I’ve got you covered. What non-parametric means here is that the model doesn’t require you to specify the number of clusters or groups in advance. In fact, the beauty of HDP lies in its ability to automatically adapt to your data, even when the number of clusters is potentially infinite.
To give you some context: HDP is like the big brother of the Dirichlet Process (DP). While DP is great for modeling data from a single group, HDP extends that power to handle multiple groups of data—each group with its own unique properties, but connected under a larger, global distribution. Think of it as a way to manage multiple restaurants, each offering different dishes, but still part of the same franchise. This “hierarchical” structure allows for both group-specific variations and global patterns.
Real-world Relevance
Why should you care about HDP? Well, this might surprise you, but HDP has some seriously cool applications. If you’ve ever heard of topic modeling, HDP is often used to uncover the underlying themes or topics in large collections of documents. For instance, in document clustering or hierarchical clustering of text corpora, HDP helps you group related documents together without you needing to say upfront, “I expect 5 topics.”
But that’s not all. HDP’s flexibility makes it perfect for bioinformatics, where you’re dealing with complex biological data that’s naturally grouped (like different types of cells or genetic data). It’s also a powerhouse in machine learning for clustering tasks, where you might not know the number of clusters your data will naturally form.
Why Use HDP?
You might be wondering: Why HDP over traditional models? Traditional parametric models—like k-means clustering—require you to specify the number of clusters ahead of time. But let’s face it, in the real world, you often don’t know how many clusters are hiding in your data. And that’s where HDP shines. It’s able to handle infinite dimensions, meaning it can grow in complexity as your data grows, all without you having to set limits. HDP learns from your data, constantly refining its structure as more data comes in.
It’s like hosting a party and not worrying about how many tables or chairs you need—you just adapt as more guests arrive. That’s the beauty of HDP. You get flexibility without the need for rigid predefined parameters.
Preliminaries: Key Concepts
Now that you’ve got an idea of what HDP is, let’s step back and make sure we’re on the same page with some foundational concepts. After all, HDP builds on some key ideas that we need to understand before diving deeper.
Dirichlet Process (DP) Recap
First up, the Dirichlet Process (DP). Imagine you’re at a restaurant with an infinite number of tables, but there’s a catch—new customers arriving at the restaurant prefer sitting at tables that already have people (they’re social like that). This is known as the Chinese Restaurant Process (CRP), a metaphor for how DP works. It clusters data by assigning each data point to a group (or “table”) with a certain probability, and the number of clusters grows as new data points come in.
In simple terms, DP allows you to model uncertainty about how many clusters (or groups) exist in your data, and it’s brilliant for when you have data from a single group. However, when your data is split into multiple groups, DP alone won’t cut it—and that’s where the hierarchical part comes in.
Stick-Breaking Construction
Here’s another interesting way to think about DP: through a process called stick-breaking. Imagine you have a stick of length 1. You break off a piece, assign it to one cluster, and then keep breaking the remaining piece for other clusters. Each piece gets smaller, but you never actually run out of stick. This process ensures that you can model a potentially infinite number of clusters, with each cluster’s probability determined by how big a piece of the “stick” it got.
It’s a bit like allocating shares of a pie to guests at your dinner party—the first few guests get big slices, but as more people arrive, you have to cut smaller pieces, although there’s always some pie left.
Grouped Data and the Need for a Hierarchical Model
You might now be thinking: “This is great for one group, but what if I have multiple groups of data?” Here’s the deal: DP works well for single groups, but if you have something like multiple restaurants, each serving its own clientele (or in data terms, multiple groups of observations), DP doesn’t account for the shared structure between groups. That’s where HDP steps in, creating a hierarchical structure where each group’s clusters are influenced by a global base distribution, allowing for both unique and shared patterns across groups.
Think of HDP as the multi-restaurant franchise version of DP. Each restaurant (group of data) has its own menu (clusters), but they’re all part of the same franchise, which ensures there are some similarities across menus, even though they’re all a little different.
Hierarchical Dirichlet Process (HDP) Explained
HDP Framework
Alright, let’s get to the heart of the Hierarchical Dirichlet Process (HDP). By now, you already know that HDP is a non-parametric Bayesian model designed for grouped data, but how exactly does it work?
Here’s the deal: HDP organizes your data into multiple groups, and each of these groups is governed by its own Dirichlet Process (DP). However, there’s something special happening here. Instead of each group being completely independent, they all share a common structure—a global base distribution—which ensures that while each group has its own unique clusters, these clusters are influenced by a higher-level distribution.
Think of it like this: imagine you own multiple restaurants, each with a different menu (that’s your group-specific DP). But the twist is that all these restaurants belong to the same franchise, so there’s a shared list of popular dishes (the global base distribution) that each restaurant draws from, even though they still have some localized specialties.
Base Measures and Their Role in the Hierarchy
In this hierarchical structure, the base measure is critical. The global DP, represented as G0G_0G0, acts as a base measure for all the group-specific DPs. So, each group-specific DP (let’s call it GiG_iGi) doesn’t start from scratch; instead, it uses G0G_0G0 as a foundation to build its own clusters. This hierarchy allows HDP to capture both the common structure across groups and the unique features within each group.
To put it simply: the base measure G0G_0G0 is like a master chef providing a basic recipe to each restaurant, but every local chef (group-specific DP) can tweak that recipe to suit the tastes of their customers. This setup ensures that while all restaurants have something in common, they’re still different enough to offer a variety of experiences.
Chinese Restaurant Franchise (CRF)
Let’s bring back the Chinese Restaurant Process (CRP) metaphor, but this time we’re leveling it up to a Chinese Restaurant Franchise (CRF). Imagine multiple restaurants (representing groups of data), each with its own tables (clusters), but all these restaurants are part of the same franchise. In each restaurant, customers (data points) prefer to sit at tables that are already occupied, just like in the CRP. However, the twist here is that the different restaurants are connected. They share a global menu of dishes (clusters) offered across all the restaurants, though each restaurant might specialize in some local variations.
In this way, the CRF metaphor perfectly captures how HDP works: it allows for both shared and group-specific clusters, which is essential when modeling grouped data where some patterns are common across groups and others are unique.
Mathematical Formulation
Now, let’s dive into the mathematical formulation of HDP. Don’t worry—I’ll walk you through it, and you’ll see how this all fits together.
At the top level, we have the global Dirichlet Process:
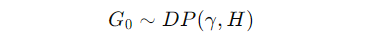
Here, G0 is our global base measure (shared across all groups), and it’s drawn from a Dirichlet Process with concentration parameter γ and a base distribution H (which is often chosen based on prior knowledge about the data).
For each group iii, we have a group-specific Dirichlet Process:
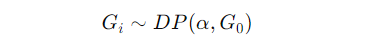
This means that each group GiG_iGi is drawn from its own DP, but instead of using a fixed base distribution, it uses the global DP G0 as its base measure. In other words, each group borrows clusters from the global distribution while still maintaining its own distinct characteristics.
So, the beauty of HDP is that the global DP G0 governs the overall structure, while each group-specific DP Gi introduces variability and uniqueness for each group.
Parameters and Hyperparameters
Now, let’s talk about those important knobs you can tune: concentration parameters α\alphaα and γ.
- α controls the clustering behavior within each group. A smaller α\alphaα leads to fewer, larger clusters, while a larger α encourages more clusters. It’s like deciding how much variety you want on the menu of each individual restaurant—do you want just a few big tables (fewer clusters) or lots of small ones (more clusters)?
- γ, on the other hand, controls the clustering behavior across all groups. It determines how much the groups borrow from the global base distribution G0. A smaller γ leads to more sharing of clusters across groups (more franchise-like), while a larger γ means that each group becomes more independent and develops its own unique clusters.
To sum it up: tuning these parameters lets you control how similar or different the groups are, and how many clusters you expect to see both within and across groups.
HDP in Practice: Applications
Now that we’ve covered the framework, let’s get into the real-world applications of HDP and why it’s such a game-changer.
Topic Modeling with HDP
One of the most popular applications of HDP is in topic modeling, especially as an extension of Latent Dirichlet Allocation (LDA). LDA is great for discovering topics in large collections of text, but it has one big limitation: you need to predefine the number of topics. That’s where HDP steps in.
Imagine you’re working with a massive collection of documents, but you have no clue how many topics are lurking in there. HDP allows you to infer the number of topics automatically. It not only clusters the documents into topics but also captures the hierarchical structure of those topics across different groups (e.g., different subdomains of the text).
For example, let’s say you’re working on a dataset of scientific articles from different fields—physics, biology, and chemistry. Each field might have its own set of unique topics, but some topics (like “data analysis” or “experimental methods”) could be shared across all fields. HDP can capture this overlap, making it ideal for unsupervised clustering in complex text corpora.
Clustering of Grouped Data
HDP isn’t just limited to text. You can apply it to bioinformatics, where you have grouped data like genetic samples from different populations. Here, HDP helps you cluster these samples into meaningful groups without needing to define how many clusters you expect.
Another interesting application is in customer segmentation for businesses. If you’ve ever tried to cluster customers based on behavior, HDP can help group similar customers together, while still allowing for group-specific characteristics based on geography, product lines, or purchase behavior.
Time-Series Data
HDP can also be a powerful tool for modeling time-series data with hierarchical structures. Imagine tracking the performance of different stores in a retail chain over time. Each store (group) may have its own unique sales patterns, but HDP allows you to model the shared trends across stores while still accounting for the variability in each individual store’s data.
This is particularly useful for dynamic systems, where the patterns evolve over time, and the hierarchical structure allows you to model both global trends and localized differences effectively.
How HDP Solves Key Challenges
Non-Parametric Nature
Here’s the deal: one of the biggest challenges you’ll face when modeling data is trying to figure out how many clusters you actually have. Most traditional clustering methods, like k-means or Gaussian Mixture Models (GMMs), force you to specify the number of clusters upfront. But, let’s be honest—how often do you really know that number before analyzing your data? Probably never.
This is where HDP really shines. It completely sidesteps the need for you to predefine the number of clusters. HDP is non-parametric, which means it adapts as your data grows. You could start with a few clusters, and as more data comes in, HDP will automatically adjust by adding or refining clusters as needed.
To put it in practical terms: imagine you’re hosting a dinner party and you don’t know how many guests will show up. HDP is like a smart host who can continuously set up new tables as more people arrive, without running out of space or asking how many tables you need in advance.
This flexibility makes HDP incredibly adaptive and ideal for situations where you have little to no idea about the underlying structure of your data.
Handling Complex Group Structures
Now, let’s tackle the next challenge: complex group structures. Real-world data often comes in hierarchical layers—think about customer data segmented by geography or scientific data split by experimental conditions. In cases like these, you have multiple groups of data, and each group might share some statistical properties with others but still remain distinct.
HDP captures this complexity effortlessly by creating a hierarchy of Dirichlet Processes. You’ve got a global DP that captures the commonalities across groups, and then each group has its own local DP that introduces unique characteristics. This hierarchy allows HDP to account for both the shared structure and the individual differences among your groups.
Imagine a franchise of coffee shops. Each store (group) follows a common recipe for making coffee (global DP), but they might have localized preferences for add-ons like oat milk or almond syrup (local DP). HDP handles this kind of scenario beautifully—modeling the global trends while preserving the local variations.
Comparison with Other Non-Parametric Models
You might be wondering, “How does HDP compare with other non-parametric models?” After all, there are other sophisticated models out there, like the Nested Chinese Restaurant Process (NCRP). While NCRP is great for certain hierarchical data structures, HDP offers more flexibility.
Here’s why: NCRP is designed specifically for nested hierarchical structures, but it assumes a rigid tree-like structure. So, it’s perfect for when your data naturally forms a nested hierarchy, like categories and subcategories in a taxonomy. However, real-world data is often messier than that, and you need a model that can handle overlapping or more fluid relationships between groups. This is where HDP is superior—it doesn’t require your data to follow a strict hierarchy. Instead, it can flexibly adapt to more complex, multi-group relationships.
In short: if your data fits into a clear, nested structure, NCRP might work well, but for more complex groupings where relationships aren’t strictly hierarchical, HDP is the go-to model.
In-Depth Example: HDP in Action
Now, let’s put all this theory into practice. I’ll walk you through a step-by-step example using a real-world dataset—let’s say a document classification task.
Detailed Walkthrough
Imagine you’re working with a dataset of scientific papers from different fields (e.g., biology, physics, chemistry), and you want to group these papers into topics without knowing in advance how many topics exist. This is a classic use case for HDP.
Step 1: Setting Up the Model
First, we’ll need to set up the HDP model. Here’s a simple Python implementation using the pyhsmm or hdp packages:
import hdp
# Create an HDP object
model = hdp.HDPModel(data=my_data, base_dist=my_base_dist)
# Fit the model to the dataset
model.fit()
# Generate cluster assignments
clusters = model.predict()
In this code snippet, my_data is your dataset (in this case, scientific papers), and my_base_dist is the base distribution that HDP will use to generate topics. After fitting the model, HDP will automatically discover the underlying topics without you needing to specify the number in advance.
Step 2: Interpreting Results
Once the model is trained, it will group the papers into topics. Here’s where it gets interesting: some topics will be shared across multiple fields (e.g., papers on data analysis techniques), while others will be unique to specific fields (e.g., papers on quantum mechanics in physics or genetic sequencing in biology). HDP will capture both the global and local trends, clustering similar papers together while allowing for group-specific variations.
Step 3: Visualizing the Results
To make this even clearer, let’s say you want to visualize the results. You can use libraries like matplotlib or seaborn to create a heatmap of topics and their distributions across the different fields.
import seaborn as sns
import matplotlib.pyplot as plt
# Create a heatmap of topic distributions
sns.heatmap(topic_distributions, cmap='Blues')
plt.title("Topic Distributions Across Scientific Fields")
plt.show()
In this heatmap, each row represents a scientific field (biology, physics, etc.), and each column represents a topic. The intensity of the color indicates the strength of the topic in each field. What’s cool here is that HDP allows you to see both the shared and unique topics across fields.
Model Diagnostics and Evaluating Performance
When it comes to evaluating your HDP model, there are several metrics you can use:
- Perplexity: A measure of how well the model fits unseen data. Lower perplexity indicates better generalization.
- Posterior Predictive Check: You can generate new samples from the model and compare them to your actual data to see how well the model captures the underlying structure.
- Visual Inspection: Sometimes, the best way to evaluate performance is by looking at the clusters themselves. Are they meaningful? Do the papers within each cluster seem related? If yes, your HDP model is doing a good job.
In summary, with HDP, you can uncover complex, multi-level relationships in your data without the need to specify cluster numbers upfront. It’s flexible, powerful, and perfect for a wide range of tasks—from text analysis to customer segmentation.
Extensions of HDP
HDP-HMM (Hidden Markov Models)
You might be wondering: What happens when you need to model data that evolves over time or in sequences? Well, here’s where the Hierarchical Dirichlet Process Hidden Markov Model (HDP-HMM) comes into play. HDP-HMM is an extension of HDP designed specifically for time series and sequential data.
Let me break it down for you. A Hidden Markov Model (HMM) is commonly used to model systems where you have hidden states evolving over time, and you only observe outputs related to these states. A classic example is speech recognition, where the underlying phonemes are hidden states, and the actual audio signal is the observable output.
Now, HMMs typically require you to predefine the number of hidden states (which, let’s face it, is a challenge because you rarely know how many states are hiding in your data). Here’s where HDP-HMM takes things to the next level: it uses the flexibility of HDP to infer the number of hidden states dynamically. This is particularly useful for applications like:
- Speech and audio processing: Automatically discovering the number of phonemes or segments in a sequence.
- Financial modeling: Uncovering hidden states in time series of stock prices or other economic indicators.
- Biological data: Identifying hidden states in gene expression data over time.
In HDP-HMM, each hidden state is associated with its own cluster, and as the model processes sequential data, it can dynamically adjust the number of states without you needing to fix it in advance. This might surprise you: by doing this, HDP-HMM becomes incredibly adaptive for complex time-varying systems, capturing rich hierarchical patterns as they evolve.
HDP-LDA (Latent Dirichlet Allocation)
Now, let’s switch gears and talk about HDP-LDA, which stands for Hierarchical Dirichlet Process – Latent Dirichlet Allocation. If you’ve worked with topic modeling before, you probably know that LDA is the go-to algorithm for finding hidden topics in a collection of documents. However, there’s one catch: you need to tell LDA how many topics you expect to find ahead of time.
But life’s messy, right? You often have no clue how many topics are buried in your text data. That’s where HDP-LDA steps in to save the day. HDP-LDA is a more flexible version of LDA that removes the need for you to specify the number of topics in advance. It uses HDP’s non-parametric nature to infer the number of topics directly from the data.
Let’s say you’re analyzing a huge collection of news articles spanning multiple years. Some topics (like “technology” or “politics”) will stay relatively consistent over time, but others might come and go (like “blockchain” or “pandemics”). HDP-LDA allows you to capture these evolving topic structures without needing to force-fit a fixed number of topics at the start.
In essence: HDP-LDA adapts to your text data, expanding and contracting the number of topics as needed, which is perfect when you’re dealing with large, complex corpora where the underlying topic structure is unknown or constantly changing.
Conclusion
So, what’s the big takeaway here?
The Hierarchical Dirichlet Process (HDP) is an incredibly powerful, flexible, and adaptive tool for modeling grouped data. Whether you’re working with complex hierarchical structures, sequential data, or even large text corpora with unknown topic counts, HDP provides a non-parametric solution that grows with your data.
Here’s why I love HDP: it handles the complexity of grouped data without forcing you to lock down the number of clusters or topics beforehand. This makes it ideal for real-world applications where the structure of your data is more dynamic and unpredictable. From HDP-HMM for time series modeling to HDP-LDA for topic discovery, the extensions of HDP ensure that you’re equipped to tackle some of the most challenging clustering and modeling tasks out there.
And remember, HDP’s adaptability doesn’t come at the cost of performance—it balances flexibility with rigor, allowing you to model everything from customer segments to hidden states in dynamic systems, all without needing to micromanage the details.
So, the next time you find yourself staring at a complex dataset with no idea how many groups or topics are hiding in there, just think of HDP as your go-to tool for uncovering structure without restrictions.