
When you hear “motivation,” you probably think of why we do what we do, right? Well, the same applies to machines—sort of. Reinforcement learning (RL) is all about teaching machines how to make decisions, but here’s where it gets interesting: traditionally, RL relies on external rewards, like a robot getting a point for reaching a goal. But what happens when those rewards are few and far between, or worse, they don’t exist at all?
This might surprise you: classical RL struggles when rewards are sparse or too delayed. Imagine trying to learn how to play a game where you only get feedback once every 100 moves—that’s frustrating for us, and it’s just as inefficient for machines.
That’s where intrinsic motivation comes in. In humans, it’s the desire to learn for the sake of learning—think curiosity, mastery, or solving a puzzle just because it’s fun. In RL, we’re borrowing this idea to help machines explore and learn on their own, even when the rewards are scarce. This blog is all about how intrinsic motivation can turn reinforcement learning from reactive to proactive, pushing machines to explore, learn, and thrive without constant hand-holding.
By the end of this, you’ll have a complete understanding of how intrinsic motivation works in RL, why it’s so powerful, and how algorithms are taking advantage of it. We’ll cover:
- What intrinsic motivation means in the RL world
- Different types of intrinsic rewards (like curiosity-based approaches)
- The algorithms making it all possible (and the math behind them)
- Real-world applications where this strategy is already making waves
Now, let’s lay down some foundational knowledge so you’re on solid ground for the rest of the blog.
Reinforcement Learning Recap (for Context)
Before we get too far into the concept of intrinsic motivation, it’s worth making sure we’re on the same page when it comes to reinforcement learning itself.
At its core, RL is about agents (think robots, algorithms, or any decision-making system) interacting with an environment to achieve some goal. The agent takes actions, which lead to changes in the state of the environment. Based on those actions, the agent receives rewards (or penalties), and over time, it learns the best way to behave to maximize the reward.
Now, you might be wondering: “How exactly do agents learn what to do?”
It all comes down to something called a Markov Decision Process (MDP). Imagine you’re playing chess, and each move you make changes the state of the board. An MDP models these kinds of situations mathematically, where each state leads to another based on the action you take. The key challenge in RL is to find the right policy—that is, a strategy that tells the agent what action to take in each state to maximize its long-term reward.
But here’s the deal: real-world problems are rarely this simple. Agents don’t always know what to do, and the rewards can be sparse, delayed, or sometimes misleading. This leads us to one of the most important trade-offs in RL: exploration vs. exploitation.
You’ve probably experienced this yourself. Imagine you’re at a new restaurant, and you can either order your favorite dish (exploitation—you know it’s good), or you can try something new (exploration—you might find something even better). RL agents face the same dilemma: should they stick to what they know works, or explore to find potentially better solutions? Traditional RL relies on external rewards to guide this exploration, but this is where it often falls short.
Challenges with External Rewards: If rewards are too sparse, delayed, or hard to define, the agent can spend too much time floundering around, unsure of what to do next. Think about training a robot to clean a house but only giving it a reward after the whole house is clean—it might take forever for the robot to figure out what actions contribute to the end goal.
This is why intrinsic motivation is so exciting—it allows agents to explore and learn in a more natural, efficient way, even when rewards are hard to come by. But to really appreciate that, you’ll need to understand how RL models work without intrinsic motivation.
What is Intrinsic Motivation?
Here’s the deal: intrinsic motivation is something you and I experience every day, and it’s not all that different when we apply it to machines. In psychology, intrinsic motivation refers to behaviors driven by internal rewards—doing something because it’s inherently satisfying, like reading a good book or solving a puzzle just because you’re curious.
Now, how does that apply to reinforcement learning (RL)? Well, traditional RL often relies on external rewards (think of it as the carrot at the end of the stick), but in the absence of clear rewards, agents tend to struggle. That’s where intrinsic motivation steps in.
Intrinsic motivation in RL is the internal push that drives agents to explore and learn for the sake of learning itself. It’s like when a robot explores an unknown room not because someone told it to, but because it’s curious about what’s behind the door.
Let’s break it down into a few key types of intrinsic motivation:
- Curiosity: You know that itch you feel when you encounter something new and want to figure it out? That’s curiosity, and in RL, agents are designed to explore unknown environments just for the sake of gaining knowledge. For example, an agent might move toward a part of the environment it hasn’t visited before, simply because it’s curious about what’s there.
- Empowerment: This is all about control. You might feel empowered when you can influence your environment, like controlling the lights in your smart home with a simple voice command. In RL, empowerment is when an agent seeks to maximize its control over future states, essentially trying to “master” its environment.
- Novelty Seeking: We’re all attracted to new experiences, and RL agents are no different. Novelty-seeking behavior encourages agents to explore diverse states—the more unexpected or new the situation, the better the agent feels, so to speak.
- Competence and Mastery: Ever played a video game long enough that you got really good at it? The more competent you become, the more rewarding it feels. Similarly, RL agents might be motivated to improve their skills, focusing on actions that make them more efficient or capable in the long run.
The Need for Intrinsic Motivation in RL
You might be wondering, “Why does RL struggle without this kind of motivation?” Well, traditional RL methods rely almost entirely on external rewards. When those rewards are sparse—meaning the agent only gets feedback occasionally—or delayed, the agent has little guidance on what’s good or bad behavior. It’s like trying to learn a new skill but only getting feedback once a month. Frustrating, right?
Intrinsic motivation helps fill in those gaps. Instead of waiting for an external reward, the agent uses internal signals (like curiosity or empowerment) to guide its actions. It learns faster and explores more efficiently, especially in complex environments where external rewards are few and far between.
Intrinsic Reward Mechanisms in RL
So, how does intrinsic motivation actually work in practice? Here’s where things get technical but also really fascinating.
In RL, we usually think of rewards as something external—win a game, get a reward. But when you introduce intrinsic motivation, internal reward signals come into play. These signals drive behavior even when there are no immediate external rewards. Let’s break down how these rewards are structured.
Curiosity-Based Approaches
Curiosity is one of the most popular forms of intrinsic motivation in RL. Think of it like this: the agent is constantly trying to reduce its uncertainty about how the environment works. For instance, let’s say an agent is in a maze. It might get rewarded not just for finding the exit, but for predicting what happens when it moves in a particular direction. If its predictions are wrong, it becomes more curious and tries to learn the environment better.
One example of this is the Intrinsic Curiosity Module (ICM), where the agent is rewarded for exploring states it can’t predict well. Essentially, the more uncertain the agent is about what comes next, the more motivated it is to explore.
Empowerment
You might find this fascinating: empowerment is all about giving agents the ability to control their environment. In human terms, it’s like learning how to master a musical instrument—the more control you have, the more empowered you feel.
In RL, empowerment rewards agents for actions that increase their influence over the environment. For example, a robotic arm might be rewarded for learning how to manipulate objects, not just for completing tasks, but for developing mastery over its physical interactions. This motivates the agent to learn behaviors that give it predictable and controllable outcomes, which can be extremely useful when external rewards are not enough.
Information Gain and Novelty
Agents can also be motivated by information gain—learning new things just for the sake of learning. You’ve probably experienced this when you discover something novel while exploring a city. RL agents can be designed to actively seek out states that provide them with new information, essentially rewarding novelty.
This is where algorithms like Random Network Distillation (RND) come into play. RND rewards agents for visiting unfamiliar states by comparing them to previously learned states. If a state is “new” or “novel,” the agent gets rewarded. It’s like traveling to a country you’ve never been to—the new sights and experiences are their own reward.
Mathematical Formulation
You might be thinking, “How do these internal rewards fit into the RL framework?” Good question. Here’s a simplified look at how we integrate intrinsic rewards mathematically.
Let’s say the agent is trying to maximize a reward function RRR. Traditionally, this reward R is entirely based on external feedback. But with intrinsic motivation, we can redefine the reward function as:
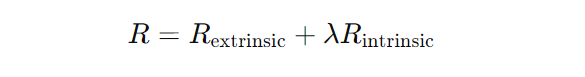
Where:
- Rextrinsic represents the external rewards (like completing a task),
- Rintrinsic represents the internal rewards (like curiosity or empowerment),
- λ is a scaling factor that balances the influence of intrinsic rewards.
In this setup, even when external rewards are missing, the agent can still learn and explore by maximizing its intrinsic rewards. It’s like balancing the satisfaction of curiosity with the need to achieve tangible goals.
Algorithms for RL with Intrinsic Motivation
You might be wondering, “How exactly do RL algorithms tap into intrinsic motivation?” Well, here’s the fun part: it’s not magic—it’s math, combined with clever models that mimic human-like curiosity, novelty-seeking, and empowerment. Let’s dive into the core algorithms that use intrinsic motivation to guide RL agents.
Curiosity-Driven Algorithms
One of the most exciting ways RL taps into intrinsic motivation is through curiosity-driven exploration. Think of it like this: just as you might feel a spark of curiosity when you encounter something new or unpredictable, RL agents can be designed to explore environments where they face uncertainty. This not only makes them more efficient at learning but also turns exploration into its own reward.
- Intrinsic Curiosity Module (ICM): This might surprise you: the ICM is like a built-in curiosity engine for RL agents. In ICM, the agent predicts what will happen next in its environment. When it’s wrong or uncertain, it becomes “curious” and gets rewarded for exploring that uncertainty. Essentially, the agent is motivated to reduce its own prediction errors, which leads to rich exploration, especially in environments where external rewards are sparse. Picture a robot navigating a new room—it will be rewarded for trying to understand how its actions change the environment, even before it finds the goal.
- Random Network Distillation (RND): Here’s where it gets even more interesting. The RND approach rewards an agent for exploring unfamiliar or “novel” states. It works by comparing an agent’s current state to a randomly initialized neural network. If the agent encounters a state that doesn’t match what it “expects” based on previous experiences, it gets rewarded. Essentially, it’s like being excited by novelty—the more unexpected a situation, the more motivated the agent is to explore. Think of it like discovering a hidden room in a video game: the unfamiliarity is its own reward.
Empowerment-Based Approaches
If curiosity is about exploring the unknown, empowerment is about gaining control. You’ve probably experienced this yourself—whether it’s learning to drive or mastering a new tool, the more control you have over a system, the more empowered you feel.
In RL, empowerment-based models reward agents for actions that increase their influence over future states. The idea is simple: agents are motivated to learn behaviors that give them maximum control over the environment. For example, a robotic arm might be rewarded for learning how to manipulate objects effectively, gaining more control over its surroundings. It’s a powerful way to teach agents skills that are useful in many different contexts, even without external goals.
One approach, Variational Empowerment, formalizes this by using information theory to quantify how much an agent’s actions can influence its future state. The more predictable and controllable the agent’s future state is, the higher the reward. This helps agents learn robust behaviors that can generalize across different tasks.
Novelty and Information-Theoretic Models
You might be thinking, “What about those agents who just want to explore for the sake of novelty?” Well, novelty-seeking is another powerful intrinsic motivator. Algorithms like Novelty Search and Surprise-Based RL focus on rewarding agents for discovering new, unvisited states in the environment.
- Novelty Search: This algorithm is all about encouraging the agent to find new, diverse experiences. It rewards agents for reaching states that are as different as possible from states they’ve already encountered. Think of it like traveling to a new city just to experience something unfamiliar—the journey itself becomes the reward.
- Surprise-Based RL: This method rewards agents for seeking out surprising outcomes—situations where the result is different from what the agent expected. By focusing on surprise, agents can develop strategies that adapt to dynamic or unpredictable environments.
Hybrid Models
You might be wondering, “Can we combine intrinsic and extrinsic rewards?” Absolutely! In fact, many advanced RL algorithms do exactly that. By combining both types of rewards, agents can balance between exploring new environments (driven by curiosity or novelty) and achieving specific tasks (driven by external rewards).
For instance, an agent might use curiosity to explore an environment initially but shift towards extrinsic rewards as it gets closer to the goal. These hybrid models allow for more robust and flexible learning strategies, especially in complex tasks where both exploration and goal-directed behavior are needed.
Applications of Intrinsic Motivation in RL
Now that we’ve got a solid understanding of how intrinsic motivation works in RL, let’s look at some real-world scenarios where this approach is already making an impact. From gaming to robotics, intrinsic motivation is enabling RL agents to perform better in tasks where predefined external rewards just won’t cut it.
Gaming and Exploration
You’ve probably played open-world video games where exploring the environment is half the fun, right? Well, in RL, intrinsic motivation is often used to enhance exploration in video games, particularly in situations where external rewards are sparse or difficult to define.
For instance, in games like Minecraft, agents driven by curiosity can explore vast, procedurally generated worlds without needing a specific reward for every move they make. This not only makes exploration more natural but also helps agents discover new strategies that might not have been obvious with purely external rewards.
Robotics
Imagine a robot in your home. Its job is to clean, cook, or maybe even help with daily tasks. How does it learn to navigate your home without explicit instructions for every new environment? This is where intrinsic motivation becomes crucial in robotics.
Robots using intrinsic motivation can explore their environments, learn new skills, and adapt to changes without being micromanaged by external reward signals. For example, a robotic vacuum might use curiosity to map out the entire house, even areas that are harder to reach or rarely used, making it more effective at its task over time.
Autonomous Vehicles
Here’s another real-world example that might surprise you: autonomous vehicles. These systems need to navigate complex, unpredictable environments where traditional RL struggles. Intrinsic motivation, particularly curiosity and empowerment, can help autonomous vehicles explore and learn safe navigation paths, even when external rewards (like reaching a destination) are sparse or delayed.
For instance, a self-driving car might explore different routes to maximize its understanding of road layouts, traffic patterns, and unexpected obstacles. This approach enables the vehicle to adapt quickly and operate safely in environments where predefined external rewards aren’t always available.
Real-World Scenarios
Outside of gaming and robotics, there are countless real-world scenarios where intrinsic motivation shines. From household robots that learn to tidy up more efficiently to automated assistants that become better at answering complex questions, intrinsic motivation allows these systems to explore new behaviors and adapt to unexpected challenges.
For example, an automated assistant might use curiosity to learn how to answer more nuanced questions over time, improving its ability to assist users without needing to be told explicitly how to handle every scenario.
Conclusion
Here’s the takeaway: intrinsic motivation in reinforcement learning is a game-changer. Just like how we humans are driven by curiosity, mastery, and the thrill of discovery, RL agents can be guided by these same internal drivers to explore, learn, and achieve—even when the external rewards are sparse or unclear.
By leveraging algorithms like Intrinsic Curiosity Module (ICM) and Random Network Distillation (RND), RL agents can navigate complex environments more effectively, without needing constant external incentives. Add to that empowerment-based approaches, novelty search, and hybrid models that balance intrinsic and extrinsic rewards, and you’ve got a powerful toolkit for teaching machines to explore and adapt like never before.
From video games to robotics and autonomous vehicles, intrinsic motivation is already proving its worth in real-world applications. It’s making systems more adaptive, more efficient, and, frankly, more human-like in their ability to learn from their environment without needing to be spoon-fed rewards.
As RL continues to evolve, the role of intrinsic motivation will only become more crucial, especially in fields where external rewards can’t easily be predefined. Whether you’re developing the next cutting-edge AI system or just curious about how machines learn, understanding intrinsic motivation will give you a deeper insight into the future of AI and autonomous systems.
And here’s a final thought to leave you with: sometimes the journey itself is the reward. In the world of reinforcement learning, that’s not just a philosophy—it’s the next step in innovation.