
You know how life isn’t always linear, right? The same goes for relationships between variables in your data. Enter Spearman’s Rank Correlation Coefficient—a non-parametric statistic that doesn’t expect your data to follow the strict rules of linearity. It’s a little more flexible, and here’s why: instead of measuring how one variable changes with the exact value of another (like Pearson’s correlation does), Spearman looks at ranks. That’s why it’s often the go-to tool when dealing with ordinal data or relationships that just don’t seem to follow a straight line.
Use Cases: Where Does Spearman Shine?
So, when should you think of Spearman? Imagine you’ve got data that’s more about ranking than exact values—say, survey responses (1st, 2nd, 3rd) or customer satisfaction ratings. Or maybe your data relationships just aren’t linear, like when an increase in X leads to an increase in Y up to a point, after which Y starts to level off. In cases like these, the assumptions required for other methods like Pearson’s correlation are violated, and that’s when you call in Spearman.
Here’s the deal: Spearman correlation works best when the relationship between variables is monotonic—meaning, when one variable increases, the other either always increases or always decreases. It doesn’t care about the shape of the relationship, just the direction.
Comparison with Pearson Correlation:
At this point, you might be wondering, “But what about Pearson’s correlation?” Good question. Pearson focuses on linear relationships—perfect for data that fits neatly into a straight line. But if your data doesn’t fit that mold, Pearson will miss the mark.
Here’s the key difference: Pearson measures how well a linear equation describes the relationship between two variables, whereas Spearman is all about the ranks, making it more robust in the face of outliers and non-linear patterns. If your data behaves in a way that’s less “straight-line” and more “curvy-road,” Spearman’s the better choice.
Mathematical Explanation of Spearman Correlation
Now, let’s get into the nuts and bolts. Spearman’s correlation coefficient, often denoted by ρ (rho), measures the strength and direction of a monotonic relationship between two variables. It’s calculated based on rank differences.
Here’s the formula, but don’t let it scare you:
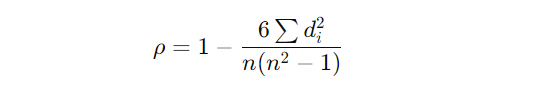
What does all that mean? Let’s break it down.
- n is the number of paired ranks (think of it as the number of data points you’re comparing).
- dᵢ is the difference between the ranks of the two variables for each observation.
In simpler terms, Spearman’s correlation is calculating how much the ranks of two variables agree with each other. If the ranks are very different (high values of d), the correlation will be closer to -1 or 1, depending on the direction of the relationship.
Interpreting Values: What Does ρ Really Tell You?
The beauty of Spearman’s rho is its simplicity in interpretation:
- ρ = 1: Your variables have a perfect positive monotonic relationship. As one increases, so does the other.
- ρ = -1: Perfect negative monotonic relationship. As one goes up, the other goes down.
- ρ = 0: There’s no monotonic relationship at all.
You might be thinking, “Wait, how is that different from linear correlation?” Well, while Pearson’s correlation focuses on linearity, Spearman only cares about the direction—whether the ranks are increasing or decreasing consistently. So, even if the relationship is curved or nonlinear, Spearman can still detect a pattern as long as it’s monotonic.
Assumptions: The Fine Print
Unlike Pearson’s correlation, which assumes normality and homoscedasticity (fancy words for “normally distributed and evenly spread data”), Spearman’s correlation has more lenient assumptions. It only needs the data to follow a monotonic trend, and that’s it. No linearity, no normality—just direction.
Let me give you an example. Say you have a dataset of students’ rankings in two different exams. Even if their scores don’t follow a straight-line relationship (maybe one exam is a bit harder than the other), Spearman can still tell you whether students who did well in one exam tend to do well in the other.
Step-by-Step Implementation in R
Okay, enough theory for now—let’s roll up our sleeves and dive into some code! Whether you’re a seasoned R user or just getting started, you’ll find the implementation of Spearman correlation in R pretty straightforward. But before we jump in, let’s gather the tools you’ll need.
Required Libraries: The R Toolbox You’ll Use
The beauty of R is that it has everything you need to compute a Spearman correlation right out of the box. The base R function cor() will get the job done. But if you want to go a little further—visualize your correlations, work with advanced datasets, or calculate complex correlation matrices—you might want to add a couple of useful packages.
Here’s what I recommend:
cor()from base R: This is your go-to function for computing Spearman correlation.ggplot2: You’ve probably heard of this one. It’s a powerful library for data visualization, perfect for creating scatter plots and heatmaps.Hmisc: If you want to calculate a correlation matrix with p-values, this package makes life easier.
You can install these packages with:
install.packages("ggplot2")
install.packages("Hmisc")Of course, don’t forget to load them:
library(ggplot2)
library(Hmisc)
Example Dataset: Let’s Use Some Real Data
Now, you might be thinking, “Where do I get the data?” Well, no need to worry. R has several built-in datasets you can play with. For this tutorial, let’s use the classic mtcars dataset. It contains data about different car models, including their miles per gallon (mpg), horsepower (hp), and other variables—perfect for our purpose.
Go ahead and load the data:
data(mtcars)
Now that you’ve got your dataset, you’re ready to compute Spearman’s correlation between two variables—let’s say mpg (miles per gallon) and hp (horsepower).
Rank Calculation: How R Handles Ranking
Before we jump into calculating the correlation, let me walk you through how R deals with ranking. Spearman correlation works on the principle of ranks rather than raw data values. What does this mean? It simply means that instead of directly comparing the values of mpg and hp, R will first convert these values into ranks and then compute the correlation based on those ranks.
This might surprise you: R does all of this ranking for you behind the scenes. You don’t have to manually rank the data unless you really want to.
But if you want to see how the ranking works (for your own curiosity), you can do something like this:
rank(mtcars$mpg)
rank(mtcars$hp)This will give you the ranks of each car model in terms of their mpg and hp.
Computing Spearman Correlation: The Fun Part
Now that you’ve seen how the ranking works, let’s move to the actual computation. The function cor() will calculate the Spearman correlation for you in one line:
cor(mtcars$mpg, mtcars$hp, method = "spearman")
Here’s the deal: The method = "spearman" argument tells R to compute Spearman correlation instead of the default Pearson correlation.
This might be a good moment for an “aha!” because you’ve just performed a full Spearman correlation analysis with a single line of code!
You might be wondering: “What about more than two variables?” Great question! If you want to compute the correlation between multiple variables, you can pass in the entire dataset:
cor(mtcars, method = "spearman")This will give you a correlation matrix for all variables in mtcars. Pair it with a visualization (which we’ll get to in another section), and you’ve got a nice overview of relationships in your dataset.
Handling Ties: What Happens When Ranks Are Equal?
Okay, so what happens if two values are the same? This is where ties come in. When R calculates ranks, it assigns tied values the average rank. For instance, if two cars had the same mpg, R would give both the average of the ranks they would have held.
Why does this matter? Well, in real datasets, tied ranks are pretty common, and Spearman’s formula handles them gracefully. In fact, this is part of why Spearman correlation is considered robust—it doesn’t get tripped up by ties in the data.
Want to see it in action? Let’s create a simple example:
data <- data.frame(var1 = c(1, 2, 2, 4, 5),
var2 = c(5, 6, 6, 8, 9))
# Compute Spearman correlation
cor(data$var1, data$var2, method = "spearman")Even with tied ranks, R handles it and returns the correct correlation value.
That’s it for this section—you’ve now got all the tools to compute and understand Spearman correlation in R. Up next, we’ll dive into visualizing these correlations to bring your insights to life!
Visualizing Correlation in R
You know the saying, “A picture is worth a thousand words”? Well, when it comes to data, a visualization is worth even more. Visualizing correlations isn’t just about pretty graphs—it’s about giving your eyes a way to see the relationships between variables. Let’s look at a few ways you can do this in R, starting with the basics and then kicking it up a notch with some advanced techniques.
Scatter Plots: The Go-To for Visualizing Monotonic Relationships
Let’s start with the classic scatter plot. If you’ve got two continuous variables and you want to see if there’s a monotonic relationship, a scatter plot is your best friend. And with ggplot2, creating one is a breeze.
Here’s the deal: We’ll plot miles per gallon (mpg) against horsepower (hp) from the mtcars dataset and add a smoothing line to help you see any underlying pattern.
library(ggplot2)
ggplot(mtcars, aes(x = hp, y = mpg)) +
geom_point() +
geom_smooth(method = "loess", se = FALSE) +
labs(title = "Scatter Plot of Horsepower vs MPG",
x = "Horsepower",
y = "Miles per Gallon")
In this plot, each point represents a car, and the smoothing line helps you visualize the overall trend. With Spearman correlation, you’re less concerned about linearity and more about whether this relationship increases or decreases consistently, which this plot can help you identify.
Heatmaps: Visualizing Multiple Correlations with corrplot
Now, if you’re working with multiple variables and want a quick visual summary of all their relationships, a correlation matrix heatmap is what you’re after. Think of it as a grid where each square represents the correlation between two variables.
Here’s how you can create one using the corrplot package:
install.packages("corrplot")
library(corrplot)
# Compute Spearman correlation matrix
spearman_corr_matrix <- cor(mtcars, method = "spearman")
# Visualize with corrplot
corrplot(spearman_corr_matrix, method = "color",
type = "upper",
tl.col = "black", tl.srt = 45)What this does is give you a heatmap where the color intensity represents the strength of the correlation between variables. The darker the color, the stronger the correlation. This visual is incredibly powerful when you need to see multiple relationships at a glance.
Advanced Visualization: Supercharge Your Correlation Plots with GGally
If you want to take your visualization game to the next level, try using GGally, an extension of ggplot2. It allows you to create pairwise plots that not only show scatter plots but also add histograms and correlation coefficients, all in one matrix.
Here’s an example:
install.packages("GGally")
library(GGally)
# Create pairwise plot with Spearman correlation
ggpairs(mtcars,
lower = list(continuous = wrap("smooth", method = "loess")),
upper = list(continuous = wrap("cor", method = "spearman")))
This will generate a matrix of plots for all your variables, showing scatter plots with smoothed lines in the lower triangle, and the Spearman correlation coefficients in the upper triangle. It’s like getting a visual and a numerical summary all at once!
Interpreting Results
Now that you’ve got your correlation plots, you’re probably wondering how to make sense of the numbers. Let’s break it down.
Strength of Correlation: What Does ρ Really Mean?
Once you calculate Spearman’s correlation, you’ll end up with a number, ρ (rho), between -1 and 1. But what does that number actually tell you?
- ρ = 1: A perfect positive monotonic relationship—as one variable increases, so does the other, consistently.
- ρ = -1: A perfect negative monotonic relationship—as one variable increases, the other decreases, consistently.
- ρ close to 0: This indicates that there’s no monotonic relationship.
For example, if you calculate the Spearman correlation between mpg and hp and get a ρ of -0.78, this tells you that there’s a strong negative monotonic relationship—as horsepower increases, miles per gallon tends to decrease.
You might be wondering, “How strong is strong enough?” As a general rule of thumb:
- |ρ| > 0.7 indicates a strong relationship,
- |ρ| between 0.3 and 0.7 is moderate,
- |ρ| < 0.3 is weak.
Significance Testing: Is This Correlation Real or Just by Chance?
Next, let’s tackle significance testing. You might have a strong correlation, but is it statistically significant? In other words, could this correlation just be due to random chance?
You can test this using cor.test() in R, which gives you both the correlation coefficient and the p-value. If the p-value is less than 0.05, you can reject the null hypothesis and conclude that the correlation is statistically significant.
Here’s the code:
cor.test(mtcars$mpg, mtcars$hp, method = "spearman")
This function will not only give you the value of Spearman’s ρ but also whether it’s significant. If you see a p-value < 0.05, you know the correlation is unlikely to be due to chance.
Effect of Outliers: Spearman’s Built-In Resilience
One of the reasons you might reach for Spearman correlation instead of Pearson’s is that Spearman is more resilient to outliers. Since Spearman works on ranks, not raw values, extreme values don’t have as much of an impact as they would in Pearson’s method.
But don’t get too comfortable. While Spearman handles outliers better, it’s not immune to them. If your data has a ton of outliers, even Spearman’s ranks can be affected. In these cases, it’s still a good idea to clean up your data or use robust statistical methods to handle those pesky outliers.
Conclusion
So, where does all of this leave us? If you’ve made it this far, you now have a solid understanding of Spearman Correlation—what it is, how to calculate it, and most importantly, when to use it.
Here’s the key takeaway: Spearman correlation is your go-to tool when you’re dealing with ranked data or non-linear relationships. Whether you’re analyzing survey results, financial data, or anything where the assumption of linearity is shaky at best, Spearman’s got your back.
But it doesn’t stop at just crunching numbers. You now know how to visualize these correlations using powerful tools like scatter plots, heatmaps, and pairwise plots. And you’ve learned how to interpret those results, understanding the strength of relationships and when they’re statistically significant.
Finally, I want to leave you with this thought: correlation is just one piece of the puzzle. While it helps uncover relationships between variables, it doesn’t imply causation. Always keep the bigger picture in mind and use correlation alongside other techniques to truly understand your data.
Now that you’ve got the tools and knowledge, I encourage you to start applying Spearman correlation to your own datasets. Whether you’re investigating relationships between variables or just curious about patterns in your data, you’re ready to dive in and make sense of it all.