
One of the most common hurdles you’ll face in your data science journey is how to handle categorical data. Think about it for a second: your machine learning model is like a number-crunching engine—it thrives on numbers. But what happens when your data consists of non-numerical categories like “red,” “blue,” “yes,” or “no”? Well, that’s where One Hot Encoding (OHE) comes into play, and trust me, this simple yet powerful technique will quickly become one of your best friends when you’re dealing with machine learning models.
What Exactly is One Hot Encoding? One Hot Encoding is a method of converting categorical variables (like “red” or “blue”) into a numerical form that can be understood by machine learning algorithms. Here’s the deal: it works by creating new binary columns for each unique category in your data. So, if you have a “Color” variable with categories like “Red,” “Blue,” and “Green,” OHE will generate three new columns—each representing one of those categories. In each row, only one of these columns will have a value of 1 (indicating the presence of that category), and the others will be 0. This simple transformation ensures that your model gets numerical inputs without assuming any ordinal relationships between categories (because, let’s face it, “Red” isn’t inherently greater than “Blue”).
Why Does Handling Categorical Data Matter? You might be wondering: Why is transforming categorical data so important? Algorithms like Logistic Regression, Decision Trees, Support Vector Machines (SVMs), and Neural Networks need numerical input to function. Without encoding, your model simply won’t know what to do with non-numerical values like “yes” or “no.” In fact, most machine learning libraries will throw errors if you try to feed them raw categorical data.
Real-World Example Let’s make this real. Suppose you’re building a predictive model to classify whether customers will churn from a service. One of your columns is “Customer Status,” with categories like “New,” “Active,” and “Churned.” Since your model can’t interpret these as-is, you’ll apply One Hot Encoding, which converts “Customer Status” into three binary columns—one for each category. Now, your model can treat these categories as separate, independent features, without assuming any sort of ranking or order between them.
Types of Categorical Variables
Before we dive deeper into One Hot Encoding, let’s talk about the kinds of categorical variables you’ll encounter in your datasets, because not all categories are created equal.
Nominal vs Ordinal Categorical Variables Categorical variables can be split into two major types: Nominal and Ordinal.
- Nominal Variables are categories without any intrinsic order or ranking. Think about colors—red isn’t “greater” than blue, and green isn’t “less than” yellow. These are categories that just represent different groups or labels. And this is exactly where One Hot Encoding shines because it transforms these categories into separate binary columns without introducing any relationship between them.
- Ordinal Variables, on the other hand, do have a clear ordering. Imagine a dataset that ranks products as “Low,” “Medium,” or “High” quality. Here, “High” is clearly better than “Medium,” and “Medium” is better than “Low.” For ordinal variables, One Hot Encoding might not be the best fit since it doesn’t capture that inherent order. In this case, you’ll probably want to use Label Encoding, which assigns a numerical value based on the rank (e.g., 0 for “Low,” 1 for “Medium,” and 2 for “High”).
Other Encoding Techniques for Ordinal Data When dealing with Ordinal Variables, you might choose Label Encoding or even techniques like Target Encoding if you’re dealing with high cardinality. Label Encoding is straightforward—it just assigns integers to each category based on its rank. However, if you use this for nominal data, it can mislead your model into thinking there’s some inherent order when there isn’t—this is why One Hot Encoding is preferred for nominal variables.
Why Use One Hot Encoding?
When you’re working with machine learning models, there’s one crucial thing to keep in mind: not all data is created equal, especially when it comes to categorical variables. Here’s the deal—algorithms love numbers, but they can be easily misled by them if we don’t handle our data carefully. This brings us to One Hot Encoding (OHE), a method that prevents your model from falling into a common trap.
Avoiding Ordinal Relationships Imagine you’re working with a dataset that contains a “Country” column with values like “USA,” “France,” and “Germany.” Now, if you just label these categories with numbers (say, 1 for “USA,” 2 for “France,” and 3 for “Germany”), you might unintentionally trick your algorithm into thinking there’s a ranking among these countries—that “Germany” is somehow “greater” than “USA.” This might sound absurd, but trust me, your algorithm will interpret it that way. That’s exactly the kind of problem One Hot Encoding solves. By transforming each category into its own binary (1 or 0) column, OHE prevents the algorithm from assuming any ordinal relationship between categories.
Binary Representation of Categories Now, you might be wondering, how does this binary magic work? Well, it’s actually pretty simple. For each unique category in a column, OHE creates a separate binary column (or “dummy variable”). Let’s say you have a “Fruit” column with values like “Apple,” “Banana,” and “Orange.” After applying OHE, you’d end up with three new binary columns: one for “Apple,” one for “Banana,” and one for “Orange.” In each row, only one of these columns will have a value of 1 (representing the presence of that category), and the others will be 0. This transformation turns your categorical variable into a numerical form, without any implied order or ranking.
Sparse Data Representation This might surprise you: after applying One Hot Encoding, you’ll often end up with a lot of zeroes. This is especially true when you have variables with many unique categories. For example, if you’re working with a column like “City” and you have 100 unique cities, OHE will generate 100 binary columns, and in each row, 99 of those columns will contain a 0. This creates what we call a sparse dataset, where most of the values are zeroes. While this can lead to increased memory usage and potential computational challenges, many machine learning frameworks are optimized to handle sparse matrices efficiently. Still, it’s something to keep in mind when you’re working with high-cardinality categorical variables.
The One Hot Encoding Process
Now that you understand why One Hot Encoding is important, let’s roll up our sleeves and walk through the step-by-step process of applying OHE to your dataset. Trust me, once you’ve done this a few times, it’ll become second nature!
Step-by-Step Process
- Identify Categorical Variables The first step is recognizing which variables in your dataset are categorical and need to be encoded. This might sound simple, but it’s crucial to be precise here. Use your data exploration tools (
pandasorR) to identify columns that contain non-numerical data. Typically, columns with text labels (e.g., “Gender,” “Country,” “Product Type”) are the ones you’ll be encoding.Pro tip: Some categorical variables might appear as numerical values (e.g., 0 and 1 for gender). Double-check your dataset to ensure you’re not overlooking any categories that need encoding. - Create Dummy Variables Once you’ve identified the categorical columns, the next step is creating the dummy variables—the heart of One Hot Encoding. For each unique category in a column, OHE generates a binary column. Here’s a simple Python code snippet to demonstrate this using
pandas:
import pandas as pd
# Sample DataFrame
data = {'Fruit': ['Apple', 'Banana', 'Orange', 'Apple', 'Banana']}
df = pd.DataFrame(data)
# Apply One Hot Encoding
one_hot_encoded_df = pd.get_dummies(df, columns=['Fruit'])
print(one_hot_encoded_df)
After applying pd.get_dummies(), your DataFrame will look something like this:
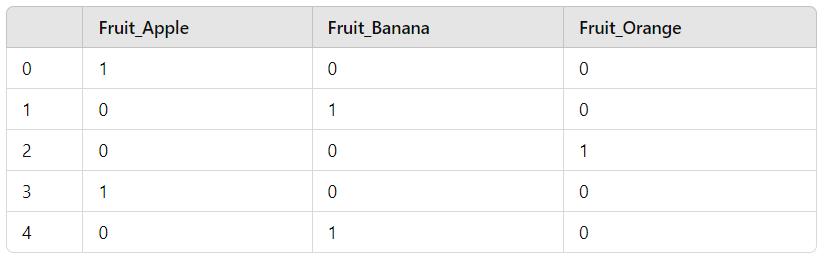
3. Handle Multiple Categories Now, what if you have variables with many unique categories, like “City” or “Product ID”? The process remains the same, but be mindful of the impact on memory and performance. You’ll want to assess whether One Hot Encoding is still the best option for variables with high cardinality. In such cases, alternative encoding methods like Target Encoding or Feature Hashing might be more appropriate (but we’ll dive into those later in the blog).
4. Code Example with sklearn You can also apply One Hot Encoding using sklearn, which provides more control over the process, especially when you’re integrating it into a machine learning pipeline.
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
# Sample DataFrame
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Initialize the encoder
encoder = OneHotEncoder(sparse=False)
# Fit and transform the data
encoded_data = encoder.fit_transform(df[['Color']])
# Convert to DataFrame for readability
encoded_df = pd.DataFrame(encoded_data, columns=encoder.get_feature_names_out(['Color']))
print(encoded_df)
This method will output a similar DataFrame but with more flexibility to control things like whether to output a sparse matrix (suitable for large datasets).
Avoiding the Dummy Variable Trap
Alright, here’s the thing: when you apply One Hot Encoding, you might unintentionally step into what’s called the Dummy Variable Trap—and trust me, it’s one trap you don’t want to fall into.
Definition and Explanation So, what exactly is the Dummy Variable Trap? It’s a form of multicollinearity, where one feature (or column) in your dataset can be perfectly predicted by the other features. Sounds harmless, right? But here’s the catch: machine learning models like Linear Regression and Logistic Regression can get totally confused when multicollinearity sneaks in. They rely on independence between the features to make accurate predictions, so when one column is simply a linear combination of others (which can happen after One Hot Encoding), it causes serious problems. Your model becomes unstable, coefficients can get wildly inflated, and overall, the interpretability of your model goes out the window.
Let’s make this real. Imagine you’ve got a “Color” variable with three categories: “Red,” “Blue,” and “Green.” After One Hot Encoding, you get three columns—one for each color. Here’s the deal: if you know the values in two of these columns (say “Red” and “Blue”), you can always predict the third (“Green”). That’s multicollinearity in action, and it throws a wrench into your model.
Solutions So, how do you avoid this trap? The solution is simple: drop one of the encoded columns. This might sound counterintuitive at first—why drop information? But don’t worry, the model will still understand everything it needs to. By dropping one category, you remove the redundancy, and your model can still infer the “dropped” category based on the remaining columns.
For instance, if you have three categories—Red, Blue, and Green—you can safely drop one (say “Green”). If both “Red” and “Blue” are 0, the model will know that “Green” is 1. Problem solved!
In Python, it’s as easy as this:
# Apply One Hot Encoding and drop the first column to avoid the Dummy Variable Trap
one_hot_encoded_df = pd.get_dummies(df, columns=['Color'], drop_first=True)
print(one_hot_encoded_df)
This one-liner helps you sidestep the trap and keeps your model running smoothly!
Handling High Cardinality
Now, you might be wondering, What happens when my categorical variables have a ton of unique categories? That’s what we call high cardinality, and it can be a real challenge when using One Hot Encoding.
Definition of High Cardinality High cardinality refers to categorical variables that have a large number of unique categories. For instance, think about a column like “City” in a dataset. If your data spans thousands of cities, applying One Hot Encoding would create thousands of new binary columns. This blows up the dimensionality of your dataset, which is a problem because machine learning models don’t exactly love working with ultra-wide datasets. It can slow down your training, increase memory usage, and sometimes even hurt model performance.
Challenges of High Cardinality in OHE Here’s the deal: when you have high cardinality, One Hot Encoding leads to a sparse matrix—most of the values will be 0. While sparse matrices are generally manageable, you’ll start to see diminishing returns with very high-cardinality variables. It bloats the dataset, making training slow and resource-intensive. Not to mention, models like tree-based algorithms (e.g., Decision Trees, Random Forests) may struggle to find meaningful splits when there are so many binary features to sift through.
Solutions to High Cardinality Thankfully, there are several techniques that can help you manage high-cardinality variables without sacrificing performance:
- Feature Hashing: This might surprise you—Feature Hashing is a clever trick to reduce the dimensionality caused by high cardinality. Instead of creating thousands of binary columns, Feature Hashing compresses these categories into a fixed number of columns by applying a hash function. It’s not perfect (you might have hash collisions where two categories map to the same column), but it’s a practical alternative that saves both memory and computation time.Here’s how you might apply Feature Hashing using the
sklearnlibrary:
from sklearn.feature_extraction import FeatureHasher
# Initialize Feature Hasher with a fixed number of output features
hasher = FeatureHasher(n_features=10, input_type='string')
# Apply hashing to the high-cardinality column (e.g., 'City')
hashed_features = hasher.transform(df['City'])
In this case, you’re compressing a potentially huge number of categories into just 10 columns. You sacrifice some interpretability, but it’s a trade-off many data scientists are willing to make when working with massive datasets.
2. Target Encoding: You might be wondering, Is there a way to encode high-cardinality variables without blowing up my feature space? Enter Target Encoding. Instead of creating dummy variables, Target Encoding replaces each category with the mean target value for that category. For example, if you’re working on a classification problem, each category will be replaced with the average probability of belonging to the positive class. This works particularly well for high-cardinality variables because it doesn’t increase the number of features.
Here’s how you could implement Target Encoding:
import category_encoders as ce
# Initialize Target Encoder
target_encoder = ce.TargetEncoder(cols=['City'])
# Apply Target Encoding
df['City_encoded'] = target_encoder.fit_transform(df['City'], df['target'])
Target Encoding is especially powerful when used in combination with models that can benefit from aggregated target information, such as Gradient Boosting Machines (GBMs). However, be cautious—overfitting can occur if you don’t handle it properly (like using cross-validation to prevent information leakage).
Practical Example Using Python
Nothing brings a concept to life better than diving into some code. Let’s walk through a practical example of One Hot Encoding using Python. For this, we’ll use the Titanic dataset—it’s a classic choice for exploring categorical data and machine learning concepts. By the end of this section, you’ll be able to see One Hot Encoding in action and know how to handle common pitfalls like missing values and the Dummy Variable Trap.
Step-by-Step Code Implementation
1. Load Dataset
First, let’s load the Titanic dataset. You can easily grab it from seaborn, which is handy if you want a quick start. If you’re working with a different dataset, the process will be very similar.
Here’s the Python code to load the Titanic dataset:
import seaborn as sns
import pandas as pd
# Load Titanic dataset from seaborn
titanic = sns.load_dataset('titanic')
# Display the first few rows of the dataset
print(titanic.head())
Once you run this, you’ll notice a few categorical variables, like “sex,” “embarked,” and “class.” These are the ones we’ll need to encode.
2. Identify Categorical Variables
Before applying One Hot Encoding, you need to identify which columns are categorical. In this case, columns like “sex” (male/female), “class” (first/second/third), and “embarked” (C/Q/S) are non-numeric and require encoding.
Let’s check which columns are categorical:
# Get column data types to identify categorical variables
print(titanic.dtypes)You’ll see that “sex,” “embarked,” and “class” are object types, indicating that they are categorical. These are the columns we’ll focus on for One Hot Encoding.
3. Apply One Hot Encoding using pandas and sklearn
Using pandas Let’s first apply One Hot Encoding using pandas, which is the easiest way to get started:
# Apply One Hot Encoding using pandas
titanic_encoded = pd.get_dummies(titanic, columns=['sex', 'class', 'embarked'], drop_first=True)
print(titanic_encoded.head())
The drop_first=True argument ensures that we avoid the Dummy Variable Trap by dropping one of the encoded categories. You’ll now see binary columns like “sex_male,” “class_Second,” and “embarked_Q.”
Using sklearn If you’re building a machine learning pipeline, you might prefer to use sklearn for more control and flexibility:
from sklearn.preprocessing import OneHotEncoder
# Select categorical columns
categorical_cols = ['sex', 'class', 'embarked']
# Initialize OneHotEncoder
encoder = OneHotEncoder(drop='first', sparse=False)
# Fit and transform the categorical columns
encoded_data = encoder.fit_transform(titanic[categorical_cols])
# Convert the encoded data back into a DataFrame
encoded_df = pd.DataFrame(encoded_data, columns=encoder.get_feature_names_out(categorical_cols))
# Concatenate the encoded columns back to the original DataFrame
titanic_encoded_sklearn = pd.concat([titanic.drop(categorical_cols, axis=1), encoded_df], axis=1)
print(titanic_encoded_sklearn.head())
Here, we used drop='first' to handle the Dummy Variable Trap and avoid multicollinearity. The result is a clean, encoded dataset that’s ready for machine learning!
4. Handle Missing Values
Now, let’s talk about something every data scientist dreads—missing values. If your categorical columns have missing values, One Hot Encoding will break. Before you encode, you’ll need to handle these missing values, either by imputing them or dropping the rows with missing data.
In the Titanic dataset, the “embarked” column has a few missing values. Here’s how you can handle them before applying One Hot Encoding:
# Check for missing values
print(titanic.isnull().sum())
# Fill missing values in 'embarked' with the most frequent value (mode)
titanic['embarked'].fillna(titanic['embarked'].mode()[0], inplace=True)
# Alternatively, you can drop rows with missing values
# titanic.dropna(subset=['embarked'], inplace=True)
# Re-check for missing values
print(titanic.isnull().sum())
After imputing or removing missing values, you can safely apply One Hot Encoding as we did above. By the way, you can apply the same strategy to handle missing values in other categorical columns.
Alternatives to One Hot Encoding
One Hot Encoding is a powerhouse for handling categorical variables, but here’s the deal—it’s not always the best tool for every situation. There are times when you’ll want to reach for alternative methods, especially when dealing with ordinal data or high-cardinality variables. Let’s explore some of these alternatives and when they might be more appropriate than OHE.
Label Encoding When it comes to ordinal data—that is, data where the categories have a clear order—One Hot Encoding might not be your best choice. Why? Because OHE treats every category as independent and doesn’t capture any relationship between them. For example, if you’re working with a “Rating” column that includes “Low,” “Medium,” and “High,” you know these have an inherent order, right? Label Encoding steps in as the hero here.
Label Encoding assigns a unique integer to each category, preserving the ordinal nature of the data. In the “Rating” example, “Low” might be encoded as 0, “Medium” as 1, and “High” as 2. This way, your model understands that there’s a progression in the categories, which can be crucial for certain algorithms, like Decision Trees and Gradient Boosting.
Here’s how you can apply Label Encoding using sklearn:
from sklearn.preprocessing import LabelEncoder
# Initialize the encoder
le = LabelEncoder()
# Apply Label Encoding to the 'Rating' column
df['Rating_encoded'] = le.fit_transform(df['Rating'])However, a word of caution: if you apply Label Encoding to nominal data (categories without order), your model might mistakenly assume a ranking that doesn’t exist, leading to poor predictions.
Frequency/Count Encoding This might surprise you, but sometimes the frequency of a category can hold valuable information. Enter Frequency Encoding (or Count Encoding), which replaces each category with its frequency or count in the dataset.
Why does this work? Well, in many cases, categories that appear more frequently may carry more significance in predictive models. For instance, in a dataset of customer purchases, the frequency of certain products being bought can provide insights into customer behavior.
Here’s how to implement Frequency Encoding:
# Frequency Encoding: replace each category with its count in the dataset
freq_encoding = df['Product_Type'].value_counts().to_dict()
df['Product_Type_encoded'] = df['Product_Type'].map(freq_encoding)This method keeps your dataset compact and doesn’t blow up your feature space, making it a good alternative when you’re working with high-cardinality variables.
Target/Mean Encoding Now, let’s talk about an advanced technique called Target Encoding (also known as Mean Encoding). This method is particularly useful when you’re dealing with high-cardinality categorical variables, like customer IDs or product categories, where One Hot Encoding would create a ridiculous number of new features.
In Target Encoding, each category is replaced by the mean of the target variable for that category. For example, in a binary classification problem, if you have a “City” column, each city would be encoded with the average probability of the target outcome (say, customer churn) for that city.
Here’s an example:
import category_encoders as ce
# Initialize the target encoder
target_encoder = ce.TargetEncoder(cols=['City'])
# Apply target encoding based on the target column 'Churn'
df['City_encoded'] = target_encoder.fit_transform(df['City'], df['Churn'])
This approach works well with high-cardinality data, but be careful—it can lead to overfitting if not handled properly. To avoid this, consider applying cross-validation or smoothing techniques when using Target Encoding.
Conclusion
Summarize Key Takeaways By now, you’ve got a solid grasp on One Hot Encoding—from why it’s critical for handling categorical variables to how to implement it in Python. You’ve also learned about potential pitfalls like the Dummy Variable Trap and how to avoid them. But OHE isn’t a one-size-fits-all solution. We’ve explored some powerful alternatives like Label Encoding, Frequency Encoding, and Target Encoding, each with its own strengths depending on your dataset and use case.
In summary, OHE is a reliable method for nominal data, but when you’re dealing with ordinal variables or high cardinality, other encoding techniques might give you better results. The trick is knowing when to use which method—and that comes with practice and experimentation.
Call to Action Now it’s your turn. Take what you’ve learned here and apply it to your datasets. Experiment with One Hot Encoding and these alternative techniques to see how they impact your models. Each dataset is unique, so try different approaches, run comparisons, and find out what works best for your specific use case. Whether you’re building predictive models, segmenting customers, or doing exploratory data analysis, handling categorical variables the right way can make all the difference.
Remember, the power of data science lies in transforming raw data into something models can understand—and encoding categorical variables is a key part of that transformation.