
Introduction
Think of data as the building blocks of every insight, model, and decision we make. But, here’s the thing: not all data is created equal. Sometimes, it’s dense and abundant, like a tightly packed suitcase full of essential items. Other times, it’s sparse, with gaps and missing pieces—more like a suitcase where half the items are just empty wrappers.
So, why does this matter to you? The distinction between sparse and dense data isn’t just theoretical; it has real-world consequences in machine learning, data storage, and how efficiently your algorithms run. Whether you’re trying to predict customer behavior, recognize objects in images, or build recommendation engines, understanding these differences can give you the competitive edge.
In this blog, I’ll walk you through what makes sparse and dense data tick, how to spot them, and most importantly, how to handle them effectively. By the time you’re done reading, you’ll have a clear picture of when and why one type is better suited for your specific data science challenges.
2. What is Sparse Data?
Let’s get technical for a moment: sparse data refers to datasets that are predominantly made up of zeroes or near-zero values. In other words, it’s data that’s mostly empty, or not filled with meaningful information. You might think of it as a desert of data, with just a few key oases of valuable data points scattered throughout.
You’ve definitely encountered this, even if you didn’t know the name for it. Imagine you’re building a recommendation system for a streaming service. You might have a massive matrix where each row is a user and each column is a movie. Here’s the catch: most users haven’t watched most movies. So, the matrix is full of zeroes (or null values), representing all the movies people haven’t seen. That’s sparse data in action.
Mathematical Representation: Let me break it down. Picture a 4×4 matrix:
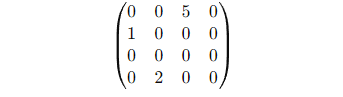
Notice how only a handful of non-zero values exist? That’s a classic sparse matrix. Now, rather than storing all the zeroes, sparse data structures only keep track of the positions and values of the non-zero elements. This makes a world of difference when it comes to memory and computational efficiency.
Common Use Cases: You might be wondering: where do I encounter sparse data? Here are a few places:
- Natural Language Processing (NLP): If you’ve ever worked with text data, sparse data is everywhere. Think about TF-IDF or one-hot encoding, where most of the words in a document aren’t present in every sentence or paragraph.
- Recommender Systems: As mentioned, systems like Netflix or Amazon rely heavily on sparse matrices to track what users engage with versus what they don’t.
- Genomic Data: In biology, many genes may remain unexpressed under certain conditions, leading to sparse representations in experimental datasets.
Storage and Computational Benefits: Here’s the deal: sparse data can be your best friend when it comes to resource management. Storing all those zeroes is inefficient, to say the least. By only keeping track of the non-zero values, you’re saving memory—sometimes by orders of magnitude.
But the benefits don’t stop at storage. Computation on sparse data can be significantly faster too. Algorithms that are designed to work with sparse matrices only operate on the non-zero entries, meaning they’re not wasting time processing irrelevant data.
So, sparse data may look like a barren landscape at first glance, but it’s packed with hidden potential.
4. Key Differences Between Sparse and Dense Data
“Not all data is created equal, and when it comes to memory and computation, sparse and dense data play by very different rules.”
You might be wondering: Why should you care whether your data is sparse or dense? Well, the way data is structured can have a massive impact on how efficiently you can store and process it. So, let’s break it down.
Memory Efficiency: Here’s the deal: sparse data is like traveling light. Imagine you’re packing for a weekend trip. You don’t need to carry every piece of clothing you own; just the essentials. Sparse data operates the same way. By using specialized formats like Compressed Sparse Row (CSR) and Compressed Sparse Column (CSC), you store only the important bits—the non-zero values. These formats map out where the data is located, saving tons of space.
For example, a sparse matrix like:

Instead of storing all the zeroes, CSR and CSC formats allow you to only store the non-zero entries and their positions. This drastically reduces memory usage, especially when you’re dealing with massive datasets.
On the other hand, dense data doesn’t have this luxury. It’s like carrying your entire wardrobe for a weekend trip—you have to store every value, even if a lot of them aren’t needed. Dense data consumes more memory, no matter how many zeroes are involved.
Computational Efficiency: Now, let’s talk speed. You might think sparse data is always faster because it’s smaller, but here’s the catch: it depends on the algorithm. Operations like matrix multiplication can be a lot quicker with sparse data, especially when algorithms are optimized to skip over zeroes. Think of it as driving on an empty highway versus one filled with roadblocks.
But, sometimes sparse data can slow things down. Why? Because the algorithm has to keep track of the positions of non-zero elements, which can add some overhead. Conversely, dense data, despite being heavier, can allow some operations to run faster because the data is contiguous in memory and easier to access without needing to map positions.
Suitability for Algorithms: You might be wondering: which algorithms perform best on sparse data versus dense data? Here’s a good rule of thumb. Algorithms that rely on distances or dot products often prefer dense data. Think deep learning models like Convolutional Neural Networks (CNNs), which thrive on dense image data where every pixel holds information.
On the flip side, algorithms like Naive Bayes are naturally suited to sparse data. Imagine you’re classifying text: not every word appears in every document, but Naive Bayes can still work with sparse data, calculating probabilities based on the few words that do appear.
In fact, decision trees and models like Random Forests don’t care too much whether your data is sparse or dense; they’ll handle it either way. However, for algorithms like linear regression with L1 regularization (Lasso), sparse data is the preferred choice. L1 regularization tends to zero out coefficients, reinforcing the sparse nature of the data.
Real-World Examples: Let’s make this practical. Take a look at two contrasting scenarios:
- Sparse Data Example: Think of a user-item matrix in a recommender system. If you’re building a recommendation engine for a music streaming platform, most users haven’t listened to most songs. So, the matrix will be sparse, with a lot of zeroes indicating songs not played by users.
- Dense Data Example: Now, let’s say you’re working with image classification. Each image is represented by a grid of pixels, and every pixel holds a value (either color intensity or brightness). There are very few zeroes here, which makes the data dense. Models like CNNs process this kind of data efficiently.
As you can see, understanding these differences helps you choose the right tools for the job.
5. Handling Sparse Data in Machine Learning
“You don’t always get to choose your data, but you can definitely choose how to handle it.”
When faced with sparse data, you need to take a few extra steps to make sure it doesn’t trip you up. Here’s how.
Data Preprocessing: The first thing you’ll want to do is assess whether all those zeroes are meaningful. For example, in some cases, missing data can be imputed or filled in using the mean, median, or even by building models to predict missing values. But more often than not, those zeroes in sparse data are real zeroes—they’re not missing; they simply represent no activity, no response, or no presence of a feature.
In such cases, techniques like thresholding can help. You might remove features or rows that have too many zero values. For example, if a column has 99% zeroes, you might consider dropping it altogether to reduce noise.
Algorithms: Some algorithms handle sparse data like a pro. If you’re dealing with text data, for instance, models like Naive Bayes are naturally built to work well with sparse representations. Other models that shine with sparse data include Logistic Regression with L1 regularization, which promotes sparsity by zeroing out unimportant features.
And you’re in luck: Scikit-learn has built-in support for sparse matrices. Many of its algorithms are optimized to handle sparse data, meaning you don’t have to convert your data to dense matrices (and suffer the memory hit) to use them. Whether it’s SVM, Random Forest, or Logistic Regression, scikit-learn has you covered.
Feature Engineering: Now, let’s talk about squeezing more value out of sparse data. Sometimes, the raw data is too sparse to be useful as-is. This is where dimensionality reduction techniques come in. You can use methods like Principal Component Analysis (PCA) or Singular Value Decomposition (SVD) to reduce the number of dimensions in your data while still keeping the essential information.
Think of it this way: if you’ve got a matrix that’s mostly zeroes, reducing the dimensionality won’t just make it smaller; it’ll often make your models run faster and more accurately by focusing only on the most important parts of your data.
6. Dense Data in Machine Learning
“Imagine you’re navigating a densely packed forest—every tree, every leaf has significance. That’s dense data for you, rich with details, and demanding attention at every turn.”
Unlike sparse data, dense data is like a crowded room—every feature, every value holds information. Think of image classification, where every pixel in a high-resolution image contains crucial data. This makes dense data valuable but also brings some unique challenges when it comes to machine learning.
Data Preprocessing: Here’s the deal: dense data might be packed with information, but that doesn’t mean it’s ready for machine learning out of the box. One of the first things you’ll want to do is preprocess it through scaling, normalization, or centering. Why? Many machine learning algorithms assume that all the features are on a similar scale. If one feature varies between 1 and 1000, and another between 0 and 1, the algorithm might overemphasize the larger values, leading to biased results.
For example, algorithms like Gradient Descent or K-Nearest Neighbors (KNN) are sensitive to the scale of your data. By normalizing or scaling the data, you level the playing field and ensure that no single feature dominates the learning process. In fact, this is particularly important in deep learning, where improper scaling can lead to longer training times or even model failure.
Algorithms: Now, here’s where dense data really shines. Deep learning algorithms, especially Convolutional Neural Networks (CNNs), are built to thrive on dense data. In tasks like image classification, speech recognition, or even financial predictions, dense data provides the rich, nuanced information these models need to identify patterns and make accurate predictions.
Let’s take image data, for example. A CNN will analyze an image pixel by pixel, learning complex hierarchies of features (edges, textures, shapes) that allow it to recognize objects or scenes. Without this dense representation, the model wouldn’t have enough information to do its job.
However, even though dense data is crucial for deep learning, not all algorithms benefit from it. In fact, some simpler models, like decision trees, can become overwhelmed or overfit when faced with too much data. So, while deep learning loves dense data, always consider your algorithm’s needs before assuming more data equals better performance.
Challenges: But dense data isn’t all sunshine and roses. Memory overhead and computational costs are two of the biggest challenges you’ll face when working with large dense datasets. Dense data requires a lot of storage and can slow down even the most powerful systems, especially when you’re dealing with high-dimensional data like HD images or 3D point clouds.
Take, for instance, a dataset of 1 million images. Each image might have millions of pixels, and storing all those values can quickly add up to terabytes of data. Training models on this dense data can take days or even weeks, depending on your hardware and computational resources. This is where techniques like downsampling or dimensionality reduction come into play, helping you manage the burden while retaining the essential information.
7. Transitioning Between Sparse and Dense Data
“Sometimes, your data starts as sparse, but over time it fills up and becomes dense. It’s like watching a puzzle come together: at first, there are gaps, but piece by piece, the picture gets clearer.”
This might surprise you, but data isn’t always stuck being either sparse or dense. There are cases where you’ll need to convert between the two formats based on the algorithms or processing needs. Let’s talk about when and why you’d want to make that transition.
When to Convert Sparse Data to Dense: You might be wondering: why would anyone convert sparse data, which is efficient and compact, into dense data, which takes up more space? Well, some algorithms just don’t play well with sparse formats. Think of algorithms like neural networks or certain types of clustering algorithms—they expect data to be dense, because they rely on the continuity and structure that dense data offers.
For example, if you’re working with a sparse user-item matrix in a recommender system but want to use a deep learning model to predict preferences, you’ll need to convert that sparse matrix to a dense format so the model can process it. However, converting sparse data to dense comes at a cost—both in terms of memory and speed. Suddenly, all those zeroes you avoided storing now have to be tracked, and depending on the dataset size, this can make a huge impact on your system’s resources.
So, before converting, always ask yourself: “Does this algorithm really need dense data?” If the answer is yes, be prepared to manage the additional computational and memory overhead.
Converting Dense Data to Sparse: On the flip side, there are scenarios where dense data should be treated as sparse. You might not realize it at first, but some dense datasets have hidden sparsity. For instance, financial transaction data can seem dense, but when you zoom in, you’ll notice that most users don’t interact with every financial instrument, creating large gaps (zeroes) in the matrix.
In these cases, converting dense data into a sparse format can save you both memory and time. A great example is when you’re working with text data, where one-hot encoded vectors may look dense but have lots of zeros (i.e., words that don’t appear in the text). By switching to a sparse format, you make storage and computation far more efficient without losing any meaningful information.
Impact on Memory and Speed: Let’s get specific. Imagine you’ve got a dense matrix with 10,000 rows and 10,000 columns—100 million elements in total. If only 0.1% of those elements are non-zero, storing all 100 million values in memory is a waste of space. Instead, by switching to a sparse format, you only need to store the 100,000 non-zero values and their positions, drastically cutting down memory usage.
However, the transition isn’t always straightforward. Some operations on sparse matrices are slower due to the added complexity of keeping track of where the non-zero values are. So, when you make this transition, always balance memory savings with computational speed, based on the needs of your task.
8. Practical Examples with Code (Python Implementation)
“Theory is great, but at the end of the day, it’s the code that runs the show.”
Now that we’ve talked about sparse and dense data from a conceptual standpoint, let’s see them in action. You’re about to see how to work with both data types in Python using libraries like scipy.sparse and sklearn, and compare their memory usage and speed.
Sparse Data Handling: Handling sparse data in Python is straightforward, thanks to the scipy.sparse module. This module allows you to create, manipulate, and perform operations on sparse matrices efficiently.
Here’s a quick example. Let’s say you have a matrix where most of the values are zero, and you want to store it in a memory-efficient way.
import numpy as np
from scipy.sparse import csr_matrix
# Create a dense matrix with lots of zeros
dense_matrix = np.array([[0, 0, 3], [4, 0, 0], [0, 5, 0]])
# Convert the dense matrix to a sparse matrix (Compressed Sparse Row format)
sparse_matrix = csr_matrix(dense_matrix)
# Now, let’s see the sparse representation
print("Sparse matrix:\n", sparse_matrix)
# If you want to see only the non-zero values:
print("Non-zero values:", sparse_matrix.data)
Here’s the deal: when you print this sparse matrix, you’ll see it only stores the non-zero values and their positions. This means you’ve slashed memory usage, making it perfect for large datasets.
Working with Sparse Matrices in Machine Learning: Let’s say you’re building a simple classifier using sklearn. You can directly feed sparse matrices into algorithms like Logistic Regression or Naive Bayes.
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load a dataset and convert it to sparse format
X, y = load_iris(return_X_y=True)
X_sparse = csr_matrix(X)
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X_sparse, y, test_size=0.3, random_state=42)
# Fit a logistic regression model
clf = LogisticRegression()
clf.fit(X_train, y_train)
# Predict and evaluate the model
predictions = clf.predict(X_test)
print("Predictions:", predictions)
The beauty here is that sklearn can seamlessly handle sparse matrices, so you don’t need to convert them to dense form. This is especially useful if you’re working with text data or any other sparse datasets where memory efficiency is key.
Dense Data Handling: Dense data is more commonly used in scenarios like image processing, where every pixel contains important information. Let’s work with a dense dataset and see how preprocessing can make or break your machine learning models.
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.datasets import load_digits
# Load a dense dataset (digits dataset)
digits = load_digits()
X, y = digits.data, digits.target
# Preprocess the data (scaling)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Fit an SVM model
clf = SVC(kernel='linear')
clf.fit(X_scaled, y)
# Evaluate the model
print("Model accuracy:", clf.score(X_scaled, y))
You might be wondering: why do we scale dense data? Here’s the deal—many machine learning algorithms assume your features are on the same scale. Without scaling, algorithms like SVM or KNN can produce suboptimal results because one feature could dominate due to its scale.
In this example, I’ve used the StandardScaler to center and scale the data, which leads to better model performance. Dense data like this is rich, and preprocessing ensures the algorithms can extract patterns efficiently.
Efficiency Demonstration: Let’s put sparse and dense data side by side to see how they perform, both in terms of memory usage and runtime. We’ll use a simple linear regression model to compare.
from sklearn.linear_model import LinearRegression
from time import time
import sys
# Function to measure memory usage
def memory_usage(obj):
return sys.getsizeof(obj)
# Create a large sparse matrix (1000x1000, 99% zeros)
large_sparse_matrix = csr_matrix(np.random.binomial(1, 0.01, (1000, 1000)))
# Create a large dense matrix
large_dense_matrix = np.random.rand(1000, 1000)
# Measure memory usage
print("Memory usage (sparse matrix):", memory_usage(large_sparse_matrix))
print("Memory usage (dense matrix):", memory_usage(large_dense_matrix))
# Measure time to fit a linear regression model
model = LinearRegression()
# For sparse matrix
start = time()
model.fit(large_sparse_matrix.toarray(), np.random.rand(1000))
print("Time to train on sparse matrix:", time() - start, "seconds")
# For dense matrix
start = time()
model.fit(large_dense_matrix, np.random.rand(1000))
print("Time to train on dense matrix:", time() - start, "seconds")What does this tell us?
- Memory Usage: Sparse matrices will consume significantly less memory, especially when they contain mostly zeros. In this case, the sparse matrix is far more efficient.
- Training Time: Interestingly, while sparse matrices save memory, converting them to dense format (
toarray()) might add overhead for certain algorithms, like linear regression. However, with algorithms optimized for sparse data, the benefits of sparse matrices are clear.
In real-world scenarios, the choice between sparse and dense formats depends on both the algorithm and the data size. Sparse data will shine in scenarios with mostly zero values, while dense data is crucial when every feature holds significant value.
Conclusion: Why Both Sparse and Dense Data Matter
“In the end, it’s not about which type of data is better—it’s about choosing the right tool for the job.”
Whether you’re dealing with sparse or dense data, each comes with its own set of strengths, challenges, and best-use scenarios. As we’ve seen, sparse data is your go-to for memory efficiency and computational speed when most of your dataset is zeroes or absent values. It shines in areas like text processing, recommender systems, and any domain where non-activity carries meaning.
On the flip side, dense data holds the spotlight when every value matters. It’s the foundation of deep learning, image processing, and complex, feature-rich datasets where every pixel, every feature, and every number counts.
You might be wondering, “When do I use sparse or dense data?” The key lies in the nature of your data and the algorithms you’re working with. If your data is mostly zeroes and your algorithm supports it, go sparse. But if you’re working with dense matrices full of valuable information, deep learning models and feature-rich algorithms will likely perform better with dense data.
Finally, transitioning between the two formats isn’t just about saving memory or speeding up computation—it’s about knowing when each approach makes the most sense. As you tackle your next data science project, remember: your data’s structure should guide your strategy.
So, whether you’re in a sparse or dense world, now you have the tools and insights to navigate both with confidence. And as with any aspect of data science, flexibility and understanding are your greatest assets.
“As the saying goes: it’s not about the size of your data, but how you use it.”