
What are RBMs?
Let’s start with a simple idea: imagine a neural network that learns to represent the complex patterns in your data—without needing explicit supervision. That’s essentially what a Restricted Boltzmann Machine (RBM) does. Now, here’s the kicker: RBMs are stochastic neural networks, which means they rely on probabilistic principles to model data. In practical terms, this makes them incredibly useful for tasks like dimensionality reduction, collaborative filtering, and feature learning.
But what makes an RBM “restricted,” you ask? It’s all about how the units are connected. RBMs consist of two layers of units:
- Visible units (which represent the data you observe)
- Hidden units (which capture the underlying features of your data)
Here’s where things get interesting: unlike a traditional neural network, where units can be fully connected, in an RBM, connections only exist between visible and hidden layers—never within a layer itself. This restriction is why they’re called “Restricted” Boltzmann Machines.
Now, how does this work in practice? Think of the RBM as trying to model the joint probability distribution between the visible and hidden units. Essentially, it’s learning to “reconstruct” your data from hidden features, which is where its power comes into play for things like recommender systems and dimensionality reduction.
Why Training RBMs is Challenging
Here’s where things get tricky. You might think, “Great, I have this clever probabilistic model. Now, I just train it like any other neural network, right?”
Well, not quite. Training an RBM is challenging because you’re dealing with hidden variables that complicate things. The hidden units introduce dependencies in the model that make calculating exact gradients difficult. Why? You don’t directly observe these hidden features, but they still influence how the model learns. This creates a problem: traditional gradient-based methods can’t directly handle these latent variables in a tractable way.
Think of it this way: You’re trying to optimize a function, but there’s a part of it that’s always hidden behind a curtain. You can’t directly “see” what’s going on, but you need that hidden information to optimize the system.
That’s where Gibbs Sampling enters the stage as a savior. It allows you to approximate the required gradients through sampling techniques. But before we get into that, let’s talk about how RBMs are typically trained using maximum likelihood estimation (MLE) and why it’s not as easy as it sounds.
Why Gibbs Sampling is Necessary for Training RBMs
Overview of Maximum Likelihood Training in RBMs
Let’s break it down simply: Maximum Likelihood Estimation (MLE) is a common method for training many types of models, and it’s no different for RBMs. In MLE, you’re trying to adjust your model’s parameters (weights and biases) so that the probability of your data is maximized. In the case of RBMs, that means finding the parameters that make your model most likely to reconstruct the input data from the hidden units.
But here’s the deal: the math behind calculating the gradients for MLE in RBMs is complicated by the presence of hidden units. To calculate the exact gradient, you’d need to marginalize over all possible configurations of the hidden units, which is computationally infeasible in practice, especially for high-dimensional data. In other words, the number of possible hidden states grows exponentially with the number of hidden units—making exact inference a nightmare.
Contrast with Other Training Methods (Optional)
You might be wondering, “If exact inference is so tough, how do people even train RBMs?”
Enter Contrastive Divergence (CD)—a faster, but less precise, alternative to Gibbs Sampling that’s widely used in practice. Here’s how it works: rather than running a full Markov Chain Monte Carlo (MCMC) process until convergence, CD takes a shortcut by truncating the Gibbs Sampling process after a few steps (usually just one or two). The result? You get an approximate gradient that’s good enough to work in practice, but it may not capture the full complexity of the data.
However, this approximation comes at a cost. While CD is quick and efficient, it can lead to biased parameter estimates, especially if the number of Gibbs steps is too low. This is why Gibbs Sampling provides a more accurate, albeit slower, solution for training RBMs when precision is more important than speed.
In short, when you’re aiming for accuracy and you can afford the computational overhead, Gibbs Sampling is the go-to technique. It’s the gold standard for capturing the true joint distribution between visible and hidden units in an RBM.
Understanding Gibbs Sampling: The Basics
What is Gibbs Sampling?
Alright, let’s start with a question that might be on your mind: What exactly is Gibbs Sampling, and why is it so useful?
Here’s the deal: Gibbs Sampling is a Markov Chain Monte Carlo (MCMC) method. If that sounds like a lot, don’t worry—I’ll break it down. The idea behind MCMC methods is to generate samples from a complex, high-dimensional probability distribution that you can’t easily compute directly. Instead of calculating the full joint distribution, you break it down into smaller, easier pieces.
Gibbs Sampling, in particular, focuses on drawing samples from the conditional distributions of individual variables, one at a time, while keeping the others fixed. Essentially, you sample each variable based on the most recent values of the others. Over time, this method allows you to approximate the joint probability distribution.
Think of it like this: Imagine you’re trying to learn a new skill, like juggling. At first, you practice with just one ball, while the others stay in place. Once you get better with that one, you move on to juggling two, then three. Gibbs Sampling works similarly—it focuses on one variable at a time, and as you sample more and more, the system converges to a true representation of the data’s underlying probability distribution.
Step-by-Step Process
Let’s break down the step-by-step process of Gibbs Sampling. We’ll start with a simple example, not related to RBMs just yet, so you can grasp the concept clearly.
Step-by-Step Process
Let’s break down the step-by-step process of Gibbs Sampling. We’ll start with a simple example, not related to RBMs just yet, so you can grasp the concept clearly.
Suppose you’re dealing with two random variables, X andY, that are jointly distributed according to some unknown probability distribution p(X,Y). You want to sample from this joint distribution. Here’s how Gibbs Sampling would work:
- Initialize both variables: You start with some initial values for X and Y. It doesn’t matter too much what these are at the beginning, but it’s important to have a starting point.
- Sample X given Y: Using the current value of Y, you sample a new value for X from the conditional distribution p(X∣Y). This is your first step in breaking down the joint distribution into something more manageable.
- Sample Y given X: Now, using the new value of X, you sample a new value for Y from the conditional distribution p(Y∣X). This second step is crucial—it refines your understanding of how Y depends on X.
- Repeat: You keep alternating between sampling X given Y and Y given X over many iterations. With enough steps, the samples will approximate the true joint distribution p(X,Y).
Here’s a simple analogy: imagine you’re trying to map out a maze, but you can only see a small portion of it at a time. Each time you move, you learn a little more about the layout. After enough moves, you’ll have explored the entire maze and can recreate the full structure. Gibbs Sampling works like this, “exploring” the conditional probabilities of individual variables until it understands the joint distribution.
Mathematical Foundation
Now that you have a basic understanding, let’s dive into the mathematical foundation of Gibbs Sampling. I’ll walk you through the math without getting too technical—just enough to explain the beauty of this method.
Let’s say we have a set of variables X1,X2,…,Xn that we want to sample from a joint probability distribution p(X1,X2,…,Xn)p. Directly sampling from this joint distribution is hard, especially as the number of variables increases. So instead, we use Gibbs Sampling.
The key idea here is that you break the joint distribution into conditional distributions. Specifically, at each step ttt, you sample one variable Xi from its conditional distribution, given the current values of all other variables:
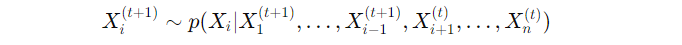
In plain English, this means that to update XiX_iXi, you look at the most recent values of all other variables, sample Xi based on that, and then move on to the next variable.
Here’s a practical example: Suppose you’re working with two variables, X and Y, whose joint distribution p(X,Y) is too complex to calculate directly. The conditional distributions p(X∣Y) and p(Y∣X), however, are simple. You start by initializing both X and Y with random values. Then, you alternately sample X given the current value of Y and Y given the current value of X.
Over time, these samples will “converge” to the true joint distribution. This process is mathematically guaranteed to work because of properties of Markov Chains—specifically, that Gibbs Sampling constructs a Markov Chain that eventually converges to the target distribution.
The beauty of Gibbs Sampling lies in its simplicity. Even though directly sampling from the joint distribution might be impossible, the conditional distributions are often much easier to handle.
How Gibbs Sampling Works in RBMs
Gibbs Sampling for Visible and Hidden Units
Let’s start with the heart of the matter: how does Gibbs Sampling work when training an RBM? The idea is simple—yet surprisingly powerful. Gibbs Sampling alternates between sampling the hidden and visible units, using each one’s conditional distribution given the other. Essentially, you’re teaching the model how to reconstruct the data by gradually “sampling” both the hidden and visible layers.
Imagine you’re teaching someone to recreate a painting from memory. You give them a partial picture and ask them to fill in the gaps. Once they’ve done that, you take their completed version and refine it, slowly working towards a full recreation. This back-and-forth refinement is what Gibbs Sampling does in RBMs.
Here’s how it works step-by-step:
- Start with the visible units (the observed data): This is the raw input data you’re feeding into the model. You fix this initially.
- Sample the hidden units based on the current visible units using their conditional probability. Think of this as predicting the hidden features that explain the input data.
- Sample the visible units again, but this time based on the sampled hidden units. In other words, you’re refining your reconstruction of the input data.
- Repeat the process by alternately sampling from the hidden and visible units.
With each iteration, Gibbs Sampling allows the model to better understand how the visible and hidden units interact to explain the data. This might sound straightforward, but let’s look at the math to see how it works under the hood.
Mathematical Formulation for RBMs
When you’re working with an RBM, you’re essentially juggling two equations—one for the hidden units and one for the visible units. The good news is that both are simple, relying on a logistic sigmoid function σ(x) to calculate probabilities.
Let’s start with the hidden units. The probability of a hidden unit being active (i.e., having a value of 1) is given by:

In this equation:
- wij is again the weight between the visible unit vi and the hidden unit hj.
- aia_iai is the bias term for the visible unit.
- And, as before, σ(x) gives us the activation probability.
So, in a nutshell:
- You use the first equation to sample the hidden units based on the visible units.
- Then, you use the second equation to sample the visible units based on the hidden units.
By alternating between these two steps—sampling hidden and visible units—you’re running the Gibbs Sampling process. With each iteration, your RBM gets closer to modeling the underlying distribution of the data.
Visualizing the Sampling Process
You might be wondering, “How can I visualize this process to make it easier to understand?” Imagine a pendulum swinging back and forth. Each time it swings one way, you’re sampling the hidden units. When it swings back, you’re sampling the visible units. Over time, this back-and-forth process lets you explore the space of possible configurations for both the visible and hidden units.
You could represent this visually with a flowchart:
- Start with visible units → Sample hidden units → Sample visible units → Repeat. This loop continues until the model stabilizes, meaning the distributions of the visible and hidden units converge.
Challenges with Gibbs Sampling in RBMs
While Gibbs Sampling is a powerful tool for training RBMs, it’s not without its challenges. Let’s break down a few key hurdles and how to overcome them.
Burn-in Period
This might surprise you, but the first few samples you generate in Gibbs Sampling are usually not great. Why? When you initialize your visible units, the hidden units haven’t had enough time to adapt to the underlying structure of the data. This means your initial samples are likely far from the true distribution.
That’s where the burn-in period comes in. The idea here is simple: you discard the initial samples from Gibbs Sampling to allow the Markov Chain to “warm up” and converge towards the true distribution. Think of it like brewing coffee—if you pour out the very first drops, they might be too weak. But if you wait a bit, you’ll get a richer, fuller brew. The same principle applies here.
Convergence Issues
Now, you might be wondering, “How do I know when Gibbs Sampling has converged?” This is where things get tricky. In theory, you want to run the process until your Markov chain reaches a stationary distribution, meaning the samples you generate are representative of the true data distribution. However, in practice, it’s hard to know exactly when this happens.
You typically have to run multiple iterations to ensure that you’re getting good samples. But beware: if you don’t run enough iterations, your model might never fully capture the underlying patterns in the data. On the flip side, running too many iterations can be computationally expensive.
High-Dimensional Data
Finally, let’s talk about high-dimensional data. When you’re dealing with data that has many features (i.e., high dimensionality), the Gibbs Sampling process can become computationally intense. Why? Because every time you sample a hidden unit, it depends on the entire set of visible units, and vice versa. As the number of units grows, the complexity of the sampling process increases exponentially.
So, what can you do? One common trick is to use mini-batches of data instead of processing the entire dataset at once. You can also consider parallelizing the sampling process or using faster approximations like Contrastive Divergence when working with very large datasets.
Understanding Gibbs Sampling: The Basics
What is Gibbs Sampling?
Alright, let’s start with a question that might be on your mind: What exactly is Gibbs Sampling, and why is it so useful?
Here’s the deal: Gibbs Sampling is a Markov Chain Monte Carlo (MCMC) method. If that sounds like a lot, don’t worry—I’ll break it down. The idea behind MCMC methods is to generate samples from a complex, high-dimensional probability distribution that you can’t easily compute directly. Instead of calculating the full joint distribution, you break it down into smaller, easier pieces.
Gibbs Sampling, in particular, focuses on drawing samples from the conditional distributions of individual variables, one at a time, while keeping the others fixed. Essentially, you sample each variable based on the most recent values of the others. Over time, this method allows you to approximate the joint probability distribution.
Think of it like this: Imagine you’re trying to learn a new skill, like juggling. At first, you practice with just one ball, while the others stay in place. Once you get better with that one, you move on to juggling two, then three. Gibbs Sampling works similarly—it focuses on one variable at a time, and as you sample more and more, the system converges to a true representation of the data’s underlying probability distribution.
Step-by-Step Process
Let’s break down the step-by-step process of Gibbs Sampling. We’ll start with a simple example, not related to RBMs just yet, so you can grasp the concept clearly.
Suppose you’re dealing with two random variables, X and Y, that are jointly distributed according to some unknown probability distribution p(X,Y). You want to sample from this joint distribution. Here’s how Gibbs Sampling would work:
- Initialize both variables: You start with some initial values for X and Y. It doesn’t matter too much what these are at the beginning, but it’s important to have a starting point.
- Sample X given Y: Using the current value of Y, you sample a new value for X from the conditional distribution p(X∣Y). This is your first step in breaking down the joint distribution into something more manageable.
- Sample Y given X: Now, using the new value of X, you sample a new value for Y from the conditional distribution p(Y∣X). This second step is crucial—it refines your understanding of how Y depends on X.
- Repeat: You keep alternating between sampling X given Y and Y given X over many iterations. With enough steps, the samples will approximate the true joint distribution p(X,Y).
Here’s a simple analogy: imagine you’re trying to map out a maze, but you can only see a small portion of it at a time. Each time you move, you learn a little more about the layout. After enough moves, you’ll have explored the entire maze and can recreate the full structure. Gibbs Sampling works like this, “exploring” the conditional probabilities of individual variables until it understands the joint distribution.
Mathematical Foundation
Now that you have a basic understanding, let’s dive into the mathematical foundation of Gibbs Sampling. I’ll walk you through the math without getting too technical—just enough to explain the beauty of this method.
Let’s say we have a set of variables X1,X2,…,Xn that we want to sample from a joint probability distribution p(X1,X2,…,Xn). Directly sampling from this joint distribution is hard, especially as the number of variables increases. So instead, we use Gibbs Sampling.
The key idea here is that you break the joint distribution into conditional distributions. Specifically, at each step ttt, you sample one variable Xi from its conditional distribution, given the current values of all other variables:
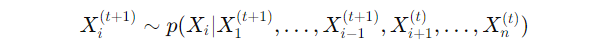
In plain English, this means that to update Xi, you look at the most recent values of all other variables, sample Xi based on that, and then move on to the next variable.
Here’s a practical example: Suppose you’re working with two variables, X and Y, whose joint distribution p(X,Y) is too complex to calculate directly. The conditional distributions p(X∣Y), however, are simple. You start by initializing both X and Y with random values. Then, you alternately sample X given the current value of Y and Y given the current value of X.
Over time, these samples will “converge” to the true joint distribution. This process is mathematically guaranteed to work because of properties of Markov Chains—specifically, that Gibbs Sampling constructs a Markov Chain that eventually converges to the target distribution.
The beauty of Gibbs Sampling lies in its simplicity. Even though directly sampling from the joint distribution might be impossible, the conditional distributions are often much easier to handle.
Python Implementation: Gibbs Sampling for RBM Training
Step-by-Step Code
We’re going to implement Gibbs Sampling for training an RBM using NumPy to keep it straightforward, but if you’re comfortable with PyTorch or TensorFlow, you can easily adapt this process. We’ll break the code down into digestible chunks and explain each part.
Let’s start by initializing the RBM parameters and writing the core sampling function.
import numpy as np
# Sigmoid activation function
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# RBM class
class RBM:
def __init__(self, num_visible, num_hidden):
self.num_visible = num_visible
self.num_hidden = num_hidden
# Initialize weights and biases
self.weights = np.random.randn(num_visible, num_hidden) * 0.1
self.visible_bias = np.zeros(num_visible)
self.hidden_bias = np.zeros(num_hidden)
# Sample hidden units given visible units
def sample_hidden(self, visible):
hidden_activation = np.dot(visible, self.weights) + self.hidden_bias
hidden_prob = sigmoid(hidden_activation)
return np.random.binomial(1, hidden_prob) # Sample from Bernoulli distribution
# Sample visible units given hidden units
def sample_visible(self, hidden):
visible_activation = np.dot(hidden, self.weights.T) + self.visible_bias
visible_prob = sigmoid(visible_activation)
return np.random.binomial(1, visible_prob) # Sample from Bernoulli distribution
What’s happening here?
- We define an RBM class with
num_visibleandnum_hiddenunits. - We initialize the weights (a matrix connecting visible and hidden units) and biases for both visible and hidden layers. The weights are initialized with small random values, while the biases are initialized to zero.
- The
sigmoidfunction is the core activation function, which converts the linear weighted sum into a probability. - The
sample_hiddenfunction samples the hidden layer units based on the current visible units, while thesample_visiblefunction does the reverse.
Training Loop with Gibbs Sampling
Now that we have the sampling functions, let’s move on to the training loop. In this loop, we’ll repeatedly sample from the hidden and visible layers using Gibbs Sampling, updating the weights based on the reconstruction error.
# Training the RBM using Gibbs Sampling
def train_rbm(rbm, data, num_epochs=1000, learning_rate=0.01, k=1):
num_samples = data.shape[0]
# Training loop
for epoch in range(num_epochs):
# Loop through each data sample
for i in range(num_samples):
# Step 1: Positive phase - sample hidden units from visible units
visible = data[i]
hidden = rbm.sample_hidden(visible)
# Step 2: Negative phase (Gibbs Sampling) - sample visible from hidden, then hidden again
for _ in range(k):
visible_reconstructed = rbm.sample_visible(hidden)
hidden_reconstructed = rbm.sample_hidden(visible_reconstructed)
# Compute weight updates
positive_grad = np.outer(visible, hidden)
negative_grad = np.outer(visible_reconstructed, hidden_reconstructed)
# Update weights and biases
rbm.weights += learning_rate * (positive_grad - negative_grad)
rbm.visible_bias += learning_rate * (visible - visible_reconstructed)
rbm.hidden_bias += learning_rate * (hidden - hidden_reconstructed)
# Optionally, print reconstruction error at each epoch
if epoch % 100 == 0:
error = np.mean(np.square(data - rbm.sample_visible(rbm.sample_hidden(data))))
print(f"Epoch {epoch}, Reconstruction Error: {error:.4f}")
Breaking it down:
- Positive Phase: For each data sample, we start by sampling the hidden units based on the current visible units. This is your “positive” phase, where the model learns from the actual data.
- Negative Phase (Gibbs Sampling): In the negative phase, we run Gibbs Sampling, which involves sampling the visible units from the hidden units, and then resampling the hidden units from the newly generated visible units. You repeat this process
ktimes, which determines how many steps of Gibbs Sampling you perform. - Weight Updates: Once we’ve completed a positive and negative phase, we calculate the positive gradient (based on the original visible and hidden units) and the negative gradient (based on the reconstructed visible and hidden units). The weights and biases are updated accordingly.
- Reconstruction Error: Every 100 epochs, I’ve added a print statement to show the reconstruction error, which gives you a sense of how well the model is learning.
Explanation of the Code
You might be wondering: why do we have a positive and negative phase?
Here’s the deal: the positive phase captures the correlations between the input data and the hidden features. The negative phase, on the other hand, tries to capture the model’s own “reconstruction” of the data. By comparing the two (through weight updates), the RBM learns to recreate the data more accurately.
You can think of this as a push-pull system: the positive phase pulls the weights in the direction of the data, while the negative phase pushes them in the direction of the model’s current guess. Over time, these two forces converge, and the model learns a balanced representation.
Visualizing the Results
Finally, let’s visualize the training results to see how Gibbs Sampling is influencing the RBM’s learning. We’ll plot the reconstruction error over time.
import matplotlib.pyplot as plt
def plot_reconstruction_error(errors):
plt.plot(errors)
plt.title('Reconstruction Error Over Time')
plt.xlabel('Epochs')
plt.ylabel('Reconstruction Error')
plt.show()
# Example of tracking reconstruction error during training
errors = []
for epoch in range(num_epochs):
error = np.mean(np.square(data - rbm.sample_visible(rbm.sample_hidden(data))))
errors.append(error)
plot_reconstruction_error(errors)
Here’s what’s going on:
- We track the reconstruction error at each epoch (i.e., how well the model is able to recreate the input data).
- Using Matplotlib, we plot this error over time to see how the model improves as it learns.
Key Points to Take Away:
- The reconstruction error tells you how well your model is learning to recreate the input data. A lower error means better learning.
- Gibbs Sampling is at the core of this training process—it alternates between sampling visible and hidden layers to refine the model’s understanding of the data.
- By iteratively running through this process, your RBM gets closer to approximating the true data distribution.
Conclusion
Now that we’ve walked through the theory and the practical implementation of Gibbs Sampling for training Restricted Boltzmann Machines (RBMs), let’s take a moment to tie it all together. You’ve seen how Gibbs Sampling works step by step, from initializing visible and hidden units, to the positive and negative phases of learning, to updating weights and biases to fine-tune the model.
Here’s what you should take away:
- Gibbs Sampling provides a powerful mechanism for approximating complex joint probability distributions by breaking them down into conditional distributions. By iterating between the visible and hidden layers in an RBM, we’re able to train the model in a way that balances data-driven learning with model-driven reconstructions.
- We explored how the positive and negative phases of learning work in tandem to push and pull the model towards an accurate understanding of the underlying patterns in the data. The key here is the iterative process of sampling, which brings us closer to the true data distribution over time.
- In terms of implementation, you’ve got the core tools now: from sampling hidden and visible units to updating the model’s parameters. And let’s not forget, visualizing the reconstruction error offers valuable insights into how well your model is learning.
Training RBMs with Gibbs Sampling might be computationally intensive, especially for high-dimensional data, but the payoff is in the accuracy and flexibility the method offers. Whether you’re using it for dimensionality reduction, feature learning, or building recommendation systems, you now have the knowledge and the code to start experimenting.
As you move forward, feel free to tweak the hyperparameters, adjust the number of Gibbs steps, or explore more advanced techniques like Contrastive Divergence. The beauty of Gibbs Sampling is in its adaptability—now it’s your turn to see what you can build with it!