
1. What is a Classification Model?
“You can’t improve what you can’t measure.”
That’s not just some old saying — it’s a fundamental truth in machine learning, especially when we talk about classification models. At their core, classification models are the machine learning algorithms that categorize data into predefined labels. Think of it as a digital decision-maker that decides whether an email is spam or not, whether an image contains a cat or a dog, or whether a patient has a disease based on medical data.
But here’s the deal: Building a classification model is only half the battle. The real challenge lies in measuring how well it performs. This is where evaluation metrics come into play. They help you understand if your model is reliable or if it’s leading you down the wrong path. After all, you wouldn’t trust a medical test if it only worked half the time, right? Similarly, your model needs to be evaluated to ensure it can be trusted in the real world.
Importance of Evaluation Metrics in Classification
So, why do evaluation metrics matter so much?
Imagine you’re working on a project to detect credit card fraud. If your model predicts that most transactions are “not fraud” just because fraud cases are rare, it might have a high accuracy rate. But it could still be missing the actual fraud cases, costing businesses millions. This is why choosing the right metric is critical. Accuracy isn’t always enough — in fact, it can be misleading in many real-world situations.
Evaluation metrics help you see beyond just correct or incorrect predictions. They allow you to measure what really matters based on your specific application. In medical diagnosis, for example, you’d want a model that rarely misses a case of disease (high recall), even if it sometimes wrongly flags a healthy person as sick. In spam detection, however, precision might be more important — nobody wants their important emails to end up in the spam folder.
Choosing the right metric can literally be the difference between success and failure, not just for your model, but for the entire project you’re working on.
2. Why Choosing the Right Metric Matters
Model Context and Use Case
Here’s something that might surprise you: The same evaluation metric doesn’t work for every classification problem.
When you’re working with models, context is everything. For example, in a binary classification problem (like predicting whether a customer will buy a product or not), you might default to accuracy. But if you’re dealing with an imbalanced dataset (where one class is much larger than the other), accuracy could deceive you. Imagine a situation where only 1% of customers are making purchases. Your model could predict that no one will buy anything, and still have 99% accuracy! Is that model actually useful? Not really.
Let’s take another example: multi-class classification. Suppose you’re building a model to identify different types of animals in photos. Accuracy alone won’t tell you whether the model is correctly identifying each class equally. Maybe it’s great at identifying dogs, but not so good with birds. For cases like these, you need more nuanced metrics — like precision, recall, or F1-score — to evaluate each class properly.
Every model is built to serve a purpose, and that purpose should determine how you measure its performance. Are you trying to minimize false positives (like in fraud detection) or false negatives (like in medical screening)? The metric you choose should directly reflect the goals of your project.
Business and Practical Implications
Now, let’s talk business — because this is where choosing the wrong metric can cost you more than just a bad model; it could cost you revenue, customers, or even lives.
Take fraud detection, for example. If your metric of choice is accuracy, your model could flag very few transactions as fraud because fraudulent transactions are rare. It might look like the model is working perfectly, but in reality, it could be letting actual fraud slip through. In this case, a false negative (missing a fraudulent transaction) can be way more expensive than a false positive (mistakenly flagging a legitimate transaction as fraud).
On the flip side, in email spam detection, if your model has a high recall but low precision, it might block too many important emails, frustrating your users. Here, precision is more valuable, because flagging legitimate emails as spam causes more harm than letting a few spam emails through.
The key takeaway? Your model’s performance isn’t just a technical concern — it has real-world implications. Choose the wrong metric, and you risk damaging your business, losing customers, or making costly errors. In the worst cases, poor metrics can lead to catastrophic failures, like a medical AI system missing early signs of cancer because it wasn’t evaluated properly.
3. Key Evaluation Metrics for Binary Classification
Binary classification metrics are like a compass guiding you toward understanding whether your model is moving in the right direction. The key to unlocking this understanding? Choosing the right metric for your specific problem. Let’s break them down one by one.
3.1 Accuracy
Definition
Accuracy is the most straightforward metric — it simply tells you the percentage of correct predictions your model made. Technically, it’s the total number of correct predictions divided by the total number of predictions. Simple, right?
But here’s where things get tricky: accuracy isn’t always what you think it is.
When to Use
Accuracy is best suited for balanced datasets — where the number of instances of each class (positive and negative) is roughly equal. But beware of using accuracy on imbalanced datasets. Imagine you’re building a model to detect rare diseases. If only 1% of the population has the disease, your model could predict that no one has it and still achieve 99% accuracy! That’s a pretty misleading metric, don’t you think?
So, while accuracy might be tempting to lean on, it’s not always the hero you need.
Formula and Example
Here’s the formula for accuracy:

3.2 Precision
Definition
Precision is all about being careful. It answers the question: Of all the positive predictions my model made, how many were actually correct?
When to Use
Precision is crucial when false positives are costly. Let’s take spam detection as an example. If your email spam filter has low precision, it will flag important emails as spam, and you could miss crucial messages. In fraud detection, poor precision might cause unnecessary alarms, flagging innocent transactions as fraudulent — a nightmare for businesses.
Formula and Example
The formula for precision is:
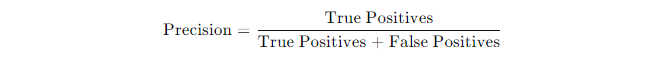
Imagine you’re predicting fraud, and your model flagged 50 transactions as fraudulent. Out of those, only 30 were actually fraud cases. Your precision would be:
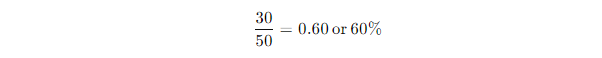
In this case, only 60% of your fraud predictions were correct, meaning you need to work on reducing false positives.
3.3 Recall (Sensitivity)
Definition
Recall (also called sensitivity) is about catching as many true positives as possible. It answers the question: Of all the actual positive cases, how many did my model correctly identify?
When to Use
You’ll want to maximize recall when missing true positives is more dangerous than catching a few false positives. Think about disease detection: you’d rather have a test that flags more people (including some who are healthy) than miss someone with a serious condition, right?
Formula and Example
Here’s the recall formula:
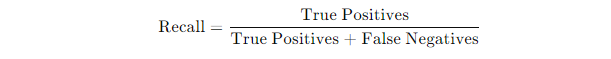
If there were 100 people with a disease and your model correctly identified 80 of them, your recall would be:
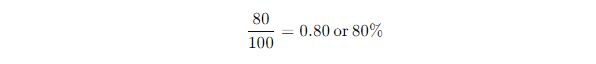
So, your model caught 80% of the actual disease cases but missed 20% — something you’d want to reduce if possible.
3.4 F1-Score
Definition
Think of the F1-Score as the great equalizer between precision and recall. It’s the harmonic mean of these two metrics and gives you a balanced view when both precision and recall are equally important.
When to Use
The F1-Score is your go-to metric for imbalanced datasets, where both precision and recall matter. If you only focus on one, you risk overlooking critical performance aspects. For example, in fraud detection, you might want to balance how often you correctly identify fraud (recall) with how often you flag legitimate transactions incorrectly (precision).
Formula and Example
The formula for F1-Score is:
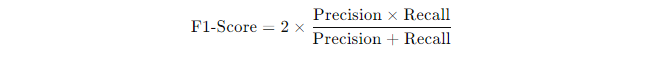
If your model has a precision of 0.75 and a recall of 0.60, the F1-Score would be:
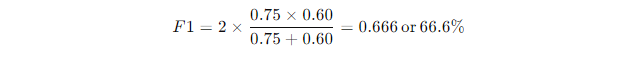
This tells you that your model is decent but might need some tweaking depending on your goals.
3.5 Specificity
Definition
Specificity is the yin to recall’s yang. While recall focuses on catching true positives, specificity asks: Of all the actual negative cases, how many did my model correctly predict?
Use Case
You’ll care about specificity in situations where true negatives are as important as true positives. For instance, in medical tests distinguishing between healthy and diseased individuals, high specificity ensures you don’t wrongly diagnose healthy people as sick, which could lead to unnecessary treatments.
3.6 Area Under the Curve (AUC) and ROC Curve
Definition
The AUC-ROC is like a visual cheat sheet for your model’s performance at different thresholds. The AUC (Area Under the Curve) is the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative one.
When to Use
You’ll want to use the AUC when comparing the performance of models across different thresholds. It’s especially useful in cases where you’re unsure which decision threshold is optimal. The closer your AUC is to 1, the better your model is at distinguishing between positive and negative classes.
Explanation of ROC Curve
The ROC Curve plots the True Positive Rate (Recall) against the False Positive Rate at various threshold settings. It helps you visualize the trade-off between catching more true positives (higher recall) and avoiding false positives.
3.7 Logarithmic Loss (Log Loss)
Definition
Unlike the hard “yes/no” predictions we’ve talked about so far, Log Loss measures the performance of your model when it’s predicting probabilities. It penalizes false predictions, especially when your model is confident but wrong.
When to Use
Log Loss is your go-to when you care about probability predictions, not just hard class labels. This is crucial when you’re working in fields like weather forecasting, stock market predictions, or medical diagnoses, where knowing the probability of an event matters.
Formula and Example
Here’s the formula for Log Loss:
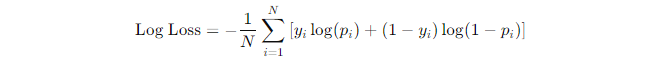
Where:
- yi is the actual label (0 or 1)
- pi is the predicted probability
For example, if your model predicts a 90% chance of fraud and it’s correct, the log loss will be small. But if it predicts a 90% chance of fraud and it’s wrong, the log loss will be high, indicating a poor prediction.
4. Handling Imbalanced Data: Specialized Metrics
When working with imbalanced datasets, relying on standard metrics like accuracy can lead you astray. Think of it like this: imagine you’re looking for a needle in a haystack — if your model only predicts “no needle” every time, it might appear accurate, but it’s completely missing the point. This is where specialized metrics come in to save the day.
4.1 Balanced Accuracy
Definition
Balanced accuracy is essentially a smarter version of accuracy. It adjusts for class imbalance by giving equal weight to the accuracy on both the positive and negative classes. In other words, it’s like fairness training for your model — making sure it’s not biased toward the majority class.
When to Use
Balanced accuracy shines when one class heavily outnumbers the other. Picture a medical scenario where only 1% of patients have a rare disease. If you rely on standard accuracy, your model could predict everyone as healthy and still look 99% accurate. But in reality, it’s missing all the cases that actually matter. This is where balanced accuracy steps in to make sure both the majority and minority classes are treated fairly.
Here’s the deal: If your dataset has a significant imbalance, you should definitely consider using balanced accuracy to ensure you’re not overlooking the minority class.
4.2 Matthews Correlation Coefficient (MCC)
Definition
You might not hear about MCC as much as accuracy or precision, but this metric is a hidden gem for imbalanced datasets. The Matthews Correlation Coefficient (MCC) gives you a single number that reflects the correlation between your observed and predicted classifications. It’s like a statistical handshake between your model’s predictions and reality.
MCC takes into account all four categories of the confusion matrix (true positives, true negatives, false positives, and false negatives), which makes it more informative than accuracy in the case of imbalanced data.
When to Use
MCC is perfect when your dataset is skewed and you need a reliable metric that balances the performance across both classes. This metric is particularly effective because it doesn’t get swayed by class imbalance as much as accuracy or even precision/recall metrics do.
Let’s look at an example: Say you’re building a model to detect credit card fraud. Fraud cases are rare, and a model that simply predicts “no fraud” all the time would achieve a high accuracy. But MCC, which incorporates all aspects of the confusion matrix, will show you that the model is actually performing poorly. In other words, MCC will tell you the truth about your model’s performance, even when accuracy might deceive you.
4.3 Precision-Recall Curve
Definition
The Precision-Recall Curve (PRC) is your go-to visual aid for understanding how well your model handles imbalanced data. It plots precision (the proportion of positive predictions that are correct) against recall (the proportion of actual positives that were correctly identified) for different thresholds.
What’s great about the precision-recall curve is that it gives you a deeper understanding of your model’s performance, especially when one class is rare. You can see how changing the decision threshold affects both precision and recall, and ultimately decide what trade-off you’re willing to make.
When to Use
This curve is incredibly useful when dealing with imbalanced classes where one class is much smaller than the other. You might have a fraud detection model where fraud is only 1% of the total transactions. In this case, the precision-recall curve helps you understand whether your model is correctly identifying those rare fraud cases (high recall) without mistakenly flagging too many non-fraudulent transactions (high precision).
Example
Here’s a typical scenario: Suppose you’re building a spam filter, and only 10% of your emails are spam. You might set a decision threshold to maximize precision — ensuring that most of the flagged emails are indeed spam, even if it means letting a few spam emails through. Alternatively, you could set the threshold to favor recall, catching all spam, but also flagging some legitimate emails in the process.
To illustrate, let’s say your model outputs probabilities for each email being spam. By adjusting the threshold (e.g., flagging emails as spam only if the probability is above 0.7 instead of 0.5), you can see how precision and recall shift. A precision-recall curve would show how these metrics trade off with each other at different thresholds, helping you choose the sweet spot for your model.
Visualization
Here’s a simplified way to think about it: Imagine a graph where recall is on the x-axis and precision is on the y-axis. The curve will tell you how well your model is balancing between catching all positives (recall) and avoiding false positives (precision). The closer the curve is to the top right corner (high precision and high recall), the better your model is performing.
When you’re dealing with imbalanced data, you need to look beyond traditional metrics. Balanced accuracy, MCC, and precision-recall curves help you see the bigger picture, ensuring that your model is performing well for all classes, not just the majority. This gives you more confidence in deploying your model in real-world scenarios where imbalanced datasets are the norm.
5. Evaluation Metrics for Multi-Class Classification
Multi-class classification takes the complexity up a notch. Unlike binary classification, where you’re just deciding between two classes (yes/no, spam/not spam), in multi-class classification, you’re dealing with three or more possible categories. Think of a model that classifies types of fruits: apple, banana, and cherry. Now, how do you evaluate how well your model performs across all these classes?
Let’s break it down.
5.1 Macro-Averaging
Definition
Macro-averaging calculates the metric (such as precision, recall, or F1-score) for each class independently and then takes the average of these values. This method treats every class equally, regardless of how many instances of each class are in your dataset.
When to Use
Use macro-averaging when each class should be given equal importance, even if some classes are underrepresented. For example, let’s say you’re building a model to classify different types of rare diseases. Even though some diseases might have far fewer instances than others, you still want your model to perform equally well on every disease. That’s where macro-averaging comes in handy — it won’t let the larger classes dominate the evaluation.
5.2 Micro-Averaging
Definition
In micro-averaging, you aggregate the contributions of all classes to compute the overall metric. This approach gives more weight to the classes with a higher number of instances because it sums up the true positives, false positives, and false negatives across all classes before calculating precision, recall, or F1-score.
When to Use
Use micro-averaging when some classes are much larger than others, and you want your metric to reflect the overall performance across all classes. This is perfect for scenarios like text classification, where some categories may have thousands of instances while others have only a few. Micro-averaging ensures that the larger classes, which might be more important for the business, get more weight in the evaluation.
5.3 Weighted Averaging
Definition
Weighted averaging is a hybrid approach. It calculates the metric for each class but weights each class’s contribution based on how many instances of that class exist in the dataset. So, the more instances a class has, the more it influences the final average.
When to Use
Weighted averaging is your go-to when you’re dealing with imbalanced datasets but still want to account for both larger and smaller classes. Imagine you’re working with a dataset that contains 70% apples, 20% bananas, and 10% cherries. Weighted averaging would give more importance to apples (the dominant class) but wouldn’t completely ignore the performance on bananas and cherries.
5.4 Confusion Matrix for Multi-Class Classification
Definition
The confusion matrix is a table that shows the number of correct and incorrect predictions for each class. It breaks down the results so you can see how your model performed for each category. In a multi-class problem, the confusion matrix is expanded to reflect all possible class pairings.
Interpretation
Let’s say you’re building a model to classify images of animals: cats, dogs, and birds. The confusion matrix will show you how often the model predicted “cat” when the actual class was “dog” or “bird” and vice versa. This gives you detailed insight into which classes are being confused with others, which is especially useful when diagnosing where your model might need improvement.
Here’s an example: if the matrix shows that “cat” is often misclassified as “dog,” you might want to focus on improving the model’s ability to distinguish between those two classes.
6. Advanced Metrics for Classification Models
Now let’s level up and explore some advanced metrics that go beyond the basics. These metrics are especially useful when standard metrics like accuracy just don’t cut it.
6.1 Cohen’s Kappa
Definition
Cohen’s Kappa measures the agreement between two raters (in this case, your model and the true labels) who each classify items into mutually exclusive categories. It accounts for the possibility of agreement occurring by chance.
Use Case
Use Cohen’s Kappa when you’re dealing with imbalanced data or when you want to measure the agreement beyond just accuracy. For instance, in medical diagnoses, if two doctors classify patients as having a disease or not, Cohen’s Kappa would tell you how much of their agreement is due to chance versus actual agreement.
In classification models, it gives you a clearer picture of performance than simple accuracy, especially in cases where the dataset is skewed.
6.2 Hamming Loss
Definition
Hamming Loss measures the fraction of labels that are incorrectly predicted. It’s used primarily in multi-label classification problems, where each instance can belong to more than one class at the same time.
When to Use
Hamming Loss is perfect for problems where instances can have multiple labels. Let’s say you’re building a model to tag images, and an image can be labeled as both “dog” and “outdoor.” If the model misses one of those tags or adds an incorrect one, Hamming Loss would reflect that error.
It’s a simple yet effective way to measure the performance of models that need to handle multiple labels for each instance.
6.3 Jaccard Index (Intersection over Union)
Definition
The Jaccard Index (also called Intersection over Union) measures the similarity between two sets by dividing the size of their intersection by the size of their union. In classification, it’s used to evaluate the performance of multi-label models.
Use Case
Jaccard Index is useful in multi-label classification problems, where an instance can belong to multiple classes at the same time. It tells you how many labels were correctly predicted out of all possible labels. This metric is commonly used in tasks like image segmentation, where you need to know how well your predicted regions overlap with the true regions.
Conclusion
In the world of machine learning, your model is only as good as the metrics you use to evaluate it. As you’ve seen, not all metrics are created equal, and blindly relying on accuracy can lead to disastrous results, especially in real-world scenarios where data is often imbalanced or multi-class.
When you’re working on binary classification, accuracy might give you a quick snapshot, but metrics like precision, recall, F1-score, and AUC-ROC paint a more complete picture, especially when your dataset is unbalanced or your use case demands more nuance. For imbalanced datasets, metrics like balanced accuracy, MCC, and the precision-recall curve are your go-to tools. In multi-class classification, knowing when to use macro, micro, and weighted averaging ensures you’re evaluating your model fairly, while advanced metrics like Cohen’s Kappa and the Jaccard Index provide deeper insight into complex models.
Here’s the deal: the right metric can make or break your model. Whether you’re trying to detect fraud, diagnose diseases, or classify images, choosing the right evaluation metric ensures that your model is not just accurate, but also reliable and useful in real-world applications.
So next time you build a classification model, take a moment to think about the context of your problem. Are you dealing with an imbalanced dataset? Are you working with multiple classes? Is it critical to avoid false positives or false negatives? The answers to these questions will guide you toward the right metric for the job. And remember, evaluating a model isn’t just about numbers — it’s about ensuring that your model works where it really matters: out there in the world.
In short, the key to building a great model is not just in how well it predicts, but in how well you measure those predictions.