
“Learning is not attained by chance, it must be sought for with ardor and attended to with diligence.”
– Abigail Adams
Now, what if I told you that machines could learn in ways that mimic how we, as humans, understand and make sense of the world—by comparing and contrasting information?
Welcome to the fascinating world of contrastive learning, a cutting-edge technique making waves in NLP! Over the past few years, the rise of self-supervised learning has been fueled by the increasing need for models to process massive amounts of unlabelled data. And at the heart of this movement is contrastive learning.
You’ve probably heard of major models like BERT, GPT, or CLIP, which have dominated natural language processing (NLP). But here’s the exciting part: many of these models are incorporating contrastive learning to better understand the intricacies of human language, such as semantic meaning, fine-tuning embeddings, and achieving state-of-the-art performance in language tasks.
What You Will Learn:
In this blog, I’ll take you on a journey from understanding the core concepts of contrastive learning to its real-world applications in NLP. You’ll discover how it works under the hood, the mathematical principles that guide it, and how it compares to traditional methods. By the end, you’ll have a solid grasp of why contrastive learning is a game changer for NLP, and you’ll be equipped to explore it further in your own projects.
Brief History & Evolution:
Let’s take a step back in time to appreciate why contrastive learning is such a significant leap. Early NLP models primarily relied on supervised learning, where labeled datasets were the bread and butter. Think of it like teaching a child by giving them every single label and expecting them to memorize it. This was powerful but not scalable. Enter unsupervised learning, where models started to learn from unstructured, unlabeled data, but lacked the same performance as their supervised counterparts.
Contrastive learning represents a bridge between these two worlds. It leverages massive amounts of unlabeled data (so you don’t have to painstakingly label everything), but still manages to produce rich, meaningful representations. It’s like teaching a child to understand differences and similarities between things, without giving them explicit instructions. And as we dive deeper, you’ll see exactly why this matters in NLP.
What is Contrastive Learning?
Core Concept:
So, what exactly is contrastive learning? Let me break it down for you in simple terms. Imagine you’re trying to teach a model how to differentiate between two concepts, say, “cat” and “dog.” Instead of just showing it pictures labeled as “cat” or “dog,” you show it pairs of images. Some pairs will be of the same category (e.g., two cats), while others will be from different categories (e.g., a cat and a dog). The model’s job? Learn that similar pairs belong together, and dissimilar pairs don’t. This is the essence of contrastive learning.
In contrastive learning, the model learns by contrasting positive examples (similar pairs) and negative examples (dissimilar pairs). It’s like teaching someone by pointing out not only what things are but also what they are not.
Mathematical Overview:
For those of you who are technically inclined, contrastive learning is often optimized through a loss function known as InfoNCE (Noise Contrastive Estimation) Loss. Don’t worry, I won’t drown you in math, but here’s a simple idea: the model maximizes the similarity between positive pairs (say, two sentences with the same meaning) and minimizes the similarity between negative pairs (sentences that have different meanings). It’s this balance of pulling similar things together and pushing different things apart that makes the model learn effectively.
In mathematical terms, the loss function looks something like this:
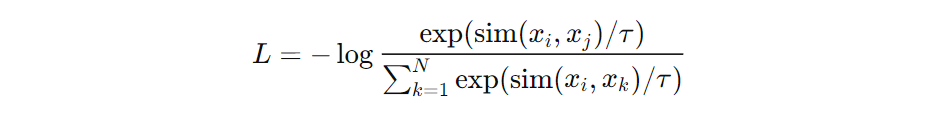
Here, sim() measures the similarity between two items (like sentences), τ is a temperature parameter that controls how much separation there is between pairs, and N is the number of negative examples. Don’t worry too much about the math right now—what matters is that this formula helps the model understand both what is similar and what isn’t.
Contrastive Learning vs. Traditional Methods:
Now, you might be wondering, why not stick with traditional methods like supervised learning? Here’s the deal: labeling data is expensive, time-consuming, and not always feasible when you’re dealing with massive datasets. In contrastive learning, you don’t need explicit labels—just pairings of similar and dissimilar examples. This means you can learn a lot from the natural structure of data without needing to manually curate every piece of information.
Contrastive learning sits between supervised and unsupervised methods. It doesn’t need as much supervision as traditional models but still manages to learn complex relationships and representations effectively. And that’s why it’s a powerhouse for NLP tasks like sentence embeddings, text classification, and even generating human-like text.
Contrastive Learning in NLP
Adaptation for NLP:
You might be wondering, how exactly does contrastive learning fit into NLP? After all, NLP is not just about images or sound—it’s about understanding the structure and meaning of language. Here’s the deal: contrastive learning has proven to be extremely versatile, and it’s now transforming NLP by helping models better grasp the relationships between words, sentences, and even entire documents.
Let’s break this down:
- Word Embeddings: Remember the days when Word2Vec and GloVe were all the rage for learning word embeddings? They helped capture the meaning of words based on context. But, like a vinyl record, these methods are now considered somewhat “classic.” With contrastive learning, we’ve stepped into a new era. Now, word embeddings can be even richer because the model learns by contrasting words in their context—pulling together words that appear in similar environments and pushing apart those that don’t. This significantly enhances the representation quality, especially in downstream NLP tasks.
- Sentence Embeddings: If you’re looking to capture the meaning of entire sentences (not just words), you’ll want to pay attention to models like SimCSE (Simple Contrastive Sentence Embeddings). In SimCSE, the model uses contrastive learning to map similar sentences closer together in the embedding space, while pushing dissimilar sentences further apart. For example, the sentences “The cat sat on the mat” and “A feline rested on the carpet” would be considered “positive pairs” because they express the same idea, while “The cat sat on the mat” and “It is raining outside” would be a negative pair. The result? Sentence embeddings that better understand semantic nuances and relationships. This allows for superior performance in tasks like sentence similarity, paraphrase detection, and text classification.
Self-Supervised Learning in NLP:
You might be thinking, where does contrastive learning fit in with heavyweights like BERT and GPT? Great question. Both BERT and GPT are giants in NLP, leveraging self-supervised learning to build state-of-the-art language models. However, contrastive learning has found its niche here as well.
BERT and GPT excel at predicting masked words or generating text based on context. But when combined with contrastive methods, these models can learn even better representations by explicitly distinguishing between similar and dissimilar text. Think of contrastive learning as the secret ingredient that adds more depth and detail to models like BERT, helping them “focus” on the differences and similarities between pieces of text.
Key Techniques in Contrastive Learning for NLP
Pretext Tasks:
In NLP, contrastive learning doesn’t happen in a vacuum—it’s driven by pretext tasks. These tasks serve as the “training ground” where models learn to differentiate between positive and negative examples. Let’s talk about a few common ones:
- Sentence Prediction: This is a favorite in models like SimCLR or SimCSE. The model takes an anchor sentence and generates multiple views of it by applying augmentations (e.g., dropping words, reordering, etc.). The goal is to match augmented views of the same sentence (positive pairs) and distinguish them from other sentences (negative pairs).
- Masked Language Modeling: This might sound familiar if you’ve worked with BERT. The idea is simple—mask some words in a sentence and have the model predict them. However, when you combine this with contrastive learning, you can apply the mask to different parts of the same sentence and force the model to learn from both the masked and unmasked views. This gives the model a stronger grasp on contextual relationships.
- Sentence Pairing and Augmentations: Here’s another clever trick. By using simple augmentations like swapping words, changing their order, or even replacing them with synonyms, you can create positive pairs that the model needs to learn to associate. Meanwhile, unrelated or randomly selected sentences act as negative pairs.
Positive and Negative Pair Construction:
This is where things get interesting. To train a model using contrastive learning, you need to carefully design your positive and negative pairs.
- Positive Pairs: In NLP, you can create positive pairs by applying augmentations to a single sentence (e.g., word dropout or shuffling). For example, “The cat sat on the mat” becomes “The cat on the mat.” Even though the structure changes slightly, they still convey the same meaning—making them a positive pair.
- Negative Pairs: On the flip side, negative pairs are often created using sentences that are completely unrelated. For instance, pairing “The cat sat on the mat” with “It is raining outside” helps the model learn that these two sentences should not be associated.
Now, here’s where hard negative mining comes in. You may be tempted to simply throw any random sentence as a negative example, but hard negative mining helps the model learn more effectively. Instead of selecting entirely unrelated sentences, hard negatives are examples that are almost similar but not quite. For example, “The cat sat on the mat” and “The cat lay on the rug” would be hard negatives—they’re close, but not the same. This makes the model work harder to learn fine-grained differences.
Contrastive Loss Functions:
This might surprise you, but one of the secret sauces in contrastive learning is the choice of loss function. A common one is the InfoNCE (Noise Contrastive Estimation) loss. I mentioned it earlier, but to recap: the goal of this loss is to maximize the similarity between positive pairs and minimize it for negative pairs.
Another popular loss function is NT-Xent (Normalized Temperature-scaled Cross Entropy Loss), used in models like SimCLR. NT-Xent scales the similarity score by a temperature parameter to make it easier for the model to focus on the most relevant differences between pairs.
In simple terms: these loss functions help the model figure out how “tight” or “loose” the relationship between two sentences should be, allowing it to more effectively group similar things together while pushing apart dissimilar ones.
Applications of Contrastive Learning in NLP
Text Classification:
You might be wondering, how can contrastive learning improve something as established as text classification? The key lies in creating better embeddings. In text classification, having accurate representations of words or sentences is critical. Traditionally, we relied on models like Word2Vec or even BERT embeddings to achieve this. But with contrastive learning, we take it up a notch by refining these embeddings.
Here’s how: Contrastive learning ensures that sentences with similar meanings are pulled together in the embedding space, and those with different meanings are pushed apart. This improves the classifier’s ability to differentiate between categories, leading to higher accuracy and generalization. Whether it’s spam detection, sentiment analysis, or topic classification, the embeddings produced through contrastive learning give your model a stronger foundation to make sense of the text.
Sentence Similarity and Paraphrase Detection:
Now, let’s talk about one of the most intuitive uses of contrastive learning: sentence similarity and paraphrase detection. Imagine you have two sentences:
- “He is a doctor.”
- “He works as a physician.”
Both mean essentially the same thing, right? Contrastive learning is designed to handle exactly these kinds of tasks by bringing these semantically similar sentences closer in the embedding space. Models like SimCSE are specifically tailored for this, and they excel at semantic similarity tasks by leveraging contrastive learning to create high-quality sentence embeddings.
In paraphrase detection, the model identifies whether two sentences convey the same meaning. Contrastive learning ensures that even if the wording is different, the meaning is captured by associating sentences that express similar ideas. This has huge implications for natural language understanding tasks like duplicate question detection (think Quora) or paraphrase generation for chatbots and virtual assistants.
Text Generation and Summarization:
Here’s the deal: fluency and coherence in text generation are among the biggest challenges for NLP. Traditional models like GPT can generate impressive text, but sometimes it lacks coherence over long passages. Contrastive learning can be used to fine-tune text generation models to improve this.
For example, when generating summaries or coherent multi-sentence text, contrastive learning helps the model understand which sentences belong together and which do not. By contrasting positive and negative sentence pairs, the model learns to avoid producing contradictory or disjointed information, resulting in more fluent and contextually appropriate outputs.
In summarization, contrastive learning helps the model identify which parts of the text are most important and related, enabling the generation of more accurate and concise summaries.
Fine-Tuning Pre-trained Models:
You’ve probably worked with models like BERT and RoBERTa, right? These models are incredibly powerful, but they still benefit from fine-tuning—and this is where contrastive learning really shines. Think of fine-tuning as taking a well-trained athlete and coaching them to specialize in a particular sport.
Contrastive learning helps fine-tune these massive models by focusing on specific relationships between text pairs. Instead of just “relearning” everything, it allows the model to sharpen its understanding of similarities and differences within new data. This is particularly effective in niche domains (like medical text or legal documents), where fine-tuning with contrastive learning can lead to significant improvements in performance. You get richer, more focused embeddings that are tailored to your specific NLP task.
Cross-lingual NLP:
This might surprise you, but contrastive learning has a big role to play in cross-lingual NLP as well. In multilingual models, we aim to create embeddings that are language-agnostic, meaning a sentence in English should have a similar embedding to the same sentence in Spanish, Chinese, or any other language. Contrastive learning makes this possible by aligning text in different languages into a shared space.
Imagine pairing a sentence in English with its translation in Spanish as a positive pair, and randomly selecting a sentence in French as a negative pair. By doing this across many languages, the model learns to produce cross-lingual embeddings that maintain meaning across linguistic boundaries. This can improve machine translation, multilingual search, and even cross-lingual sentiment analysis.
Contrastive Learning Models in NLP
SimCLR (Simple Contrastive Learning):
Let’s kick things off with SimCLR, which was originally designed for computer vision but has found its way into NLP. SimCLR’s core idea is simple: apply data augmentations to create positive pairs and contrast them with other examples. For NLP, you can think of this as augmenting sentences by dropping or reordering words, or by replacing words with their synonyms. By training the model to predict which sentences belong together, SimCLR helps generate robust embeddings that are great for tasks like sentence classification and similarity.
SimCSE (Simple Contrastive Learning of Sentence Embeddings):
Next up, we have SimCSE, which has quickly become one of the go-to models for generating sentence embeddings. What makes SimCSE unique is its simplicity and effectiveness. There are two versions:
- Unsupervised SimCSE: Here, a sentence is passed through a pre-trained language model like BERT twice with minor noise (like dropout) to generate positive pairs. The idea is to make the model learn to map these noisy representations of the same sentence closer together.
- Supervised SimCSE: In the supervised version, labeled data (like paraphrases) is used to create positive pairs directly. This variant performs even better in tasks requiring fine semantic understanding, such as paraphrase detection or sentence similarity.
Whether supervised or unsupervised, SimCSE is extremely powerful for generating high-quality sentence embeddings, which are essential for many NLP tasks like information retrieval and dialogue systems.
CLIP:
You might know CLIP from its success in vision-language tasks, but its ideas can be extended to text-only tasks as well. CLIP works by learning joint embeddings for images and their corresponding text descriptions. In the NLP world, we can extend this idea by learning embeddings for different modalities of text—for example, by aligning code with comments or aligning text in multiple languages.
While CLIP shines in vision-language, the underlying contrastive principles are highly relevant for tasks like text-to-text retrieval or multi-modal NLP, where text data needs to be aligned across domains.
MoCo (Momentum Contrast):
Now, let’s talk about MoCo. MoCo is primarily used in computer vision but can be adapted to NLP by maintaining a large memory bank of past examples. Instead of directly contrasting your current batch with itself (as in SimCLR), MoCo uses a momentum encoder to generate a rich set of contrasting examples.
This approach allows the model to contrast its current examples with a wider variety of negative pairs, leading to more diverse and robust sentence embeddings. While MoCo’s full potential in NLP is still being explored, it holds promise for applications like document clustering and large-scale retrieval tasks.
BYOL (Bootstrap Your Own Latent):
Finally, we have BYOL (Bootstrap Your Own Latent). What makes BYOL stand out is its ability to work without explicit negative pairs. Instead, it focuses on creating positive pairs through augmentations, without worrying about pushing negative examples apart. While primarily used in self-supervised vision tasks, BYOL’s approach could inspire future NLP models that focus more on fine-tuning existing representations rather than explicitly contrasting examples.
Conclusion:
As you can see, contrastive learning is not just a niche technique—it’s a versatile tool that’s shaping the future of NLP. Whether you’re working on text classification, sentence similarity, or even cross-lingual tasks, contrastive learning offers a way to improve your model’s performance by focusing on relationships between examples. As more research is done and models like SimCSE, MoCo, and BYOL continue to evolve, the possibilities for contrastive learning in NLP are only just beginning.