
“Optimization is the silent engine behind machine learning—without it, even the most sophisticated models would remain lifeless equations.”
When you’re working with machine learning, optimization algorithms are your behind-the-scenes power tools. They drive the process of turning raw data into models that can make predictions, classify images, or even generate human-like text. Think of it this way: optimization algorithms are like navigators in a vast landscape of possibilities, guiding your model to the peak of its performance.
But why are they so essential? Here’s the deal: every machine learning model has a singular goal—to minimize its error or maximize its accuracy. That’s where optimization algorithms come into play. They help your model learn by continuously adjusting its parameters until it gets as close as possible to this goal. Without optimization, machine learning wouldn’t, well… learn.
Let me break it down a bit more clearly: Optimization algorithms are processes or methods used to tweak the internal parameters of your machine learning models so that they perform better over time. Whether you’re building a simple linear regression model or training a complex neural network, optimization algorithms are key to ensuring your model improves and learns efficiently.
In this blog, we’ll take a deep dive into several types of optimization algorithms:
- Gradient-based methods like Gradient Descent and its variations.
- Non-gradient methods such as Genetic Algorithms and Simulated Annealing.
- Concepts like convex and non-convex optimization and why these differences matter in your ML journey.
By the time you finish reading, you’ll not only understand what optimization algorithms do, but why mastering them is critical for anyone serious about machine learning—whether you’re a data scientist, researcher, or ML engineer.
What are Optimization Algorithms in Machine Learning?
You might be wondering, “What exactly is optimization in the context of machine learning?” It all starts with a problem your model needs to solve. In its simplest form, optimization is about minimizing or maximizing something—whether it’s reducing the error rate of a model or increasing its accuracy.
In machine learning, optimization algorithms work by tweaking the parameters (like weights in a neural network) to minimize an objective function. What’s an objective function, you ask? It’s the heart of the optimization process—usually, this function measures how well or poorly your model is doing. Think of it as a scorecard that tells your algorithm how close it is to the correct answer.
Now, there are two main types of optimization problems:
- Convex vs. Non-Convex: Convex problems are the golden ticket in optimization. Why? Because in convex problems, there’s only one global minimum. No matter where you start, you’ll eventually reach that best possible solution. Non-convex problems, on the other hand, are trickier. You could get stuck in local minima, meaning your model might find a “pretty good” solution but miss out on the best one. Neural networks, for example, are notorious for being non-convex optimization problems.
- Constrained vs. Unconstrained: In a constrained problem, there are limits or conditions that your solution has to meet (think of trying to fit a square peg into a round hole, but with rules). In unconstrained optimization, you have no such limits—you can explore solutions freely. Machine learning models often deal with constrained optimization when trying to balance multiple objectives, like accuracy vs. computational cost.
Objective Functions: Every optimization algorithm is chasing one thing—an objective function. This is also called the loss function or cost function, and it’s a mathematical expression of how well your model is performing. For example, in linear regression, the goal is to minimize the difference between the predicted and actual values (Mean Squared Error is a common loss function here).
Let me give you a real-world analogy: Imagine you’re a rock climber (your model), trying to reach the highest peak (minimizing your loss function). Optimization algorithms are like different climbing strategies. Some take you on a direct path (like Gradient Descent), while others explore the terrain more broadly, searching for alternative routes (like Genetic Algorithms). The objective function is the altitude you want to reach, and your goal is to find the highest (or lowest) point—your global optimum.
Takeaway: Understanding optimization algorithms is non-negotiable if you want to make sure your machine learning models perform well. Whether you’re reducing error rates or boosting accuracy, the algorithms and techniques you choose are critical to success.
With that said, let’s dive deeper into specific algorithms and see how they work in practice!
Gradient-Based Optimization Algorithms
Alright, let’s talk about Gradient Descent, the bedrock of machine learning optimization. Imagine you’re standing at the top of a hill in the fog, trying to make your way down to the lowest point. The fog is thick, so you can’t see far. You feel your way down by taking small steps in the direction that feels like the steepest decline. This is what Gradient Descent does—it finds the optimal solution (or the “lowest point”) for your model by following the steepest slope of the cost function.
Gradient Descent: The Basics
Gradient Descent is all about taking steps in the right direction—downhill. In mathematical terms, we adjust the parameters (like weights in your model) by calculating the gradient of the loss function. The gradient tells us the slope at a particular point, and by moving in the opposite direction of the gradient, we minimize the loss.
Here’s the math:
- We update parameters θ\thetaθ as:
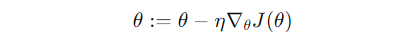
- Where η is the learning rate (the step size), and ∇θJ(θ)\ is the gradient of the cost function with respect to θ.
What does this mean? At each step, we adjust the model parameters in the direction that decreases the error. Over time, these small updates push the model toward the optimal solution.
But here’s where things get interesting: Gradient Descent comes in a few flavors, and the one you choose can drastically impact how quickly (and successfully) you reach that optimal solution.
Variants of Gradient Descent
- Batch Gradient Descent Batch Gradient Descent computes the gradient of the cost function for the entire dataset before updating the model parameters. It’s like gathering all the information before making a single decision.Advantages:
- It’s stable and follows a direct path toward the minimum.
- Works well for smaller datasets.
- It’s computationally expensive when working with large datasets since it processes the entire dataset at each step.
- Stochastic Gradient Descent (SGD) Now, if batch gradient descent feels too slow, here’s the deal: Stochastic Gradient Descent takes a more nimble approach by updating parameters after each training example, rather than the entire dataset. You can think of it as a quick, agile runner—taking fast, sometimes erratic, steps toward the goal.Advantages:
- Faster updates since it processes one sample at a time.
- It’s great for large datasets because it doesn’t require loading everything into memory at once.
- It can be noisy and fluctuate, sometimes taking steps in the wrong direction due to its randomness.
- Less stable, often bouncing around the minimum.
- Mini-Batch Gradient Descent Want the best of both worlds? That’s where Mini-Batch Gradient Descent comes in. It splits the dataset into smaller “mini-batches” and updates parameters based on each mini-batch. This balances the stability of batch gradient descent with the speed of stochastic.Advantages:
- Faster than batch gradient descent but more stable than pure SGD.
- Efficient on hardware with parallelization.
- Requires tuning the mini-batch size, which can be tricky.
Advanced Gradient-Based Methods
Here’s where things get even more interesting. Gradient Descent is a solid start, but as you might’ve noticed, it has limitations—convergence can be slow, and it may get stuck in local minima. This is where advanced techniques like Momentum, Adam, and others come into play.
- Momentum Think of Momentum as adding inertia to your steps. Instead of simply moving based on the current gradient, momentum considers the previous steps, building speed in the right direction.Mathematics Behind It:
- Update rule:
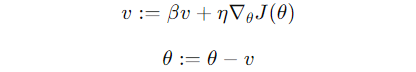
- Here, vvv is the velocity, and β\betaβ is the momentum factor (usually around 0.9).
- It smoothens out fluctuations, leading to faster convergence, especially in ravine-like regions of the loss function.
- Nesterov Accelerated Gradient (NAG) Nesterov takes the idea of momentum and adds foresight—rather than using just the past velocity, it looks ahead at where the current velocity would take it.Advantages:
- Often leads to faster convergence than momentum.
- Prevents overshooting by incorporating this “look-ahead” mechanism.
- AdaGrad If you’ve got sparse data (like text data), AdaGrad can be your best friend. It adapts the learning rate for each parameter individually, giving more attention to frequently updated parameters and less to those that aren’t changing much.Advantages:
- Automatically adjusts learning rates, making it useful for problems with sparse features.
- The learning rate can decay too much, leading to slow convergence over time.
- RMSProp To tackle the issue of AdaGrad’s decaying learning rate, RMSProp introduces a moving average of the squared gradients, allowing the algorithm to keep making updates even after many iterations.Advantages:
- Works well for non-convex problems.
- Stabilizes learning rates, making it particularly useful in deep learning.
- Adam (Adaptive Moment Estimation) Finally, we have Adam, which combines the best of both RMSProp and Momentum. Adam keeps track of an exponentially decaying average of past gradients and squared gradients, making it both adaptive and fast.Advantages:
- Converges faster and is widely used in deep learning.
- Automatic adjustment of learning rates and momentum.
Comparative Analysis
Let’s wrap this section up with a quick comparison:
- Batch Gradient Descent: Stable but slow; good for small datasets.
- SGD: Fast but noisy; great for large datasets.
- Mini-Batch Gradient Descent: Best balance between speed and stability.
- Momentum & NAG: Speed up convergence, particularly in challenging optimization landscapes.
- AdaGrad & RMSProp: Adaptive learning rates, with RMSProp better suited for non-convex problems.
- Adam: Fast, adaptive, and a top choice for most deep learning models.
Second-Order Optimization Algorithms
You might be wondering, “What about algorithms that consider curvature?” This is where second-order methods come into play. They don’t just look at the gradient (first derivative); they also factor in the curvature of the cost function (second derivative). While more accurate, they come with higher computational costs.
- Newton’s Method Newton’s method goes a step further by using the second derivative (the Hessian) to find a more precise path toward the minimum.Advantages:
- Faster convergence when the Hessian is easy to compute.
- It’s computationally expensive because calculating the Hessian matrix is no joke—especially in high-dimensional spaces like deep learning models.
- Quasi-Newton Methods (BFGS, L-BFGS) Quasi-Newton methods, like BFGS and L-BFGS, approximate the Hessian matrix rather than calculating it exactly, making them a bit more practical for large-scale problems.When to use it? These methods are particularly useful when you’re dealing with optimization problems in lower-dimensional spaces and want faster convergence than first-order methods can offer.
Challenges of Second-Order Methods
The downside of second-order methods is their computational complexity. Calculating or approximating second derivatives can be prohibitive in models with millions of parameters, which is why first-order methods (like Adam) are more popular for large-scale machine learning tasks.
Global Optimization Algorithms (Non-Gradient-Based Methods)
When it comes to optimization in machine learning, you often hear a lot about gradient-based methods like Gradient Descent. But what happens when the terrain is too complex for gradients to lead the way? This is where global optimization algorithms step in—algorithms that don’t rely on gradients to find the best solution, making them extremely useful in non-convex and multi-modal landscapes.
These algorithms are like explorers that aren’t just looking for the nearest valley—they’re searching for the deepest one, even if it’s hidden behind a mountain or across a plateau. Let’s walk through a few popular global optimization algorithms and how they can be applied in machine learning.
Simulated Annealing
Imagine you’re forging a sword. In the process of heating and cooling the metal, there’s a point where the metal reaches its most malleable state. This is the idea behind Simulated Annealing. The algorithm mimics this physical process of heating and slowly cooling a material to achieve a more optimal structure.
How does it work in optimization? You start by exploring your solution space at random, allowing for “bad moves” at first (like when the metal is hot and flexible). Gradually, as the algorithm “cools down,” it becomes less likely to accept these suboptimal moves and focuses more on honing in on the best solution.
Here’s why this is useful: Simulated Annealing doesn’t get stuck in local minima because, early on, it’s allowed to explore more freely. As it cools, it hones in on the most promising areas, avoiding the trap of suboptimal solutions.
Real-world applications:
- Hyperparameter tuning in machine learning models where the search space is complex.
- Combinatorial optimization problems, like the famous Traveling Salesman Problem.
When to use it: If you’re dealing with a non-differentiable or highly non-convex problem where gradient-based methods fail, simulated annealing might just be the right tool.
Genetic Algorithms
Here’s something interesting: Nature has already solved some of the hardest optimization problems. Evolution, with its process of natural selection, has been “optimizing” life for billions of years. Genetic Algorithms (GA) borrow from this idea.
Here’s the deal: In genetic algorithms, potential solutions are like “organisms.” These solutions evolve over time, combining good traits (crossover) and introducing randomness (mutation) to explore new possibilities. The algorithm selects the best solutions (the fittest), and these solutions “mate” to create the next generation.
How does it work in practice?
- Population initialization: You start with a random set of possible solutions (the population).
- Fitness evaluation: Each solution is evaluated based on a fitness function (how well it solves the problem).
- Crossover and Mutation: The fittest solutions combine to create new “offspring,” with some random mutations added to explore new possibilities.
- Selection: The best solutions survive to the next generation, and the cycle repeats.
Real-world applications:
- Feature selection: In machine learning, you can use GAs to choose the most relevant features for a model.
- Neural architecture search: Finding the best neural network structure without manually tuning every parameter.
When to use it: Genetic Algorithms are especially useful for problems where the search space is vast and irregular, and where traditional optimization methods struggle.
Particle Swarm Optimization (PSO)
Here’s another optimization algorithm that draws inspiration from nature—Particle Swarm Optimization (PSO). PSO is based on the collective behavior of animals, like birds flocking or fish schooling. Each “particle” (or potential solution) in the swarm moves through the solution space, influenced both by its own experience and the successes of its neighbors.
How it works:
- Each particle adjusts its position based on two factors: its best-known position (personal experience) and the best-known positions of its neighbors (social influence).
- The swarm collectively converges towards an optimal solution as particles communicate and adjust their velocities based on these factors.
Real-world applications:
- Optimization of neural networks: PSO can be used to optimize the weights of a neural network or for hyperparameter tuning.
- Control systems: It’s been used in areas like robotics and aircraft control to optimize system parameters.
When to use it: If you’re looking for an optimization method that can explore and exploit a solution space without relying on gradient information, PSO is a solid choice.
Differential Evolution
You might be wondering, “How is Differential Evolution (DE) different from Genetic Algorithms?” While both are inspired by evolutionary processes, Differential Evolution focuses on the difference between solutions to drive the search.
Here’s how it works:
- DE generates new candidate solutions by adding the weighted difference between two population vectors to a third vector.
- This new candidate is then compared to a current solution, and the better one survives.
Why is this useful? DE is especially effective in continuous optimization problems where you want a method that’s both simple and robust.
Real-world applications:
- Parameter optimization: DE is often used for optimizing parameters in machine learning algorithms, particularly when the search space is continuous.
- Engineering problems: DE has been successfully applied in areas like antenna design and power systems.
Convex vs. Non-Convex Optimization
Let’s shift gears and talk about a fundamental concept in optimization: the distinction between convex and non-convex optimization problems. This might surprise you, but the shape of the function you’re optimizing can drastically affect how difficult it is to find the best solution.
Convex Optimization: Why Convexity is Desirable
Convex optimization is the holy grail for optimization problems because, in a convex function, there’s only one global minimum. No matter where you start, as long as you keep descending, you’re guaranteed to find the best solution.
Mathematically, a function is convex if a line drawn between any two points on the curve lies above or on the curve. In simpler terms, the function has a smooth, bowl-like shape, and there’s no possibility of getting stuck in a local minimum.
Why is this desirable? Convex problems are predictable and easier to solve. You don’t need to worry about whether your optimization algorithm will get stuck in a suboptimal solution—it’s a direct path to success.
Real-world applications: Convex optimization is used in linear regression, support vector machines, and many other machine learning algorithms where the objective function is convex.
Non-Convex Optimization: The Challenges
Non-convex optimization is a whole different beast. In non-convex problems, there could be multiple local minima (valleys) and even flat regions (saddle points), making it much harder to find the global minimum.
Challenges include:
- Local minima: Your algorithm might get stuck in a suboptimal solution that looks like the best one locally but isn’t globally.
- Saddle points: These are flat areas where the gradient is zero, making it difficult for gradient-based methods to proceed.
Practical strategies:
- Random initialization: Running your algorithm from different starting points to increase the chances of finding the global minimum.
- Restarts: If your model gets stuck, restart the optimization with a different initialization.
- Advanced optimizers: Techniques like momentum and Adam help escape saddle points and local minima.
Examples of Non-Convex Problems:
- Deep learning: Training neural networks is a classic non-convex problem, where gradient-based methods might need help from techniques like early stopping, learning rate schedules, or even non-gradient-based algorithms.
- Reinforcement learning: Another example where the landscape is often non-convex due to the complexity of policy and reward structures.
Regularization in Optimization
Finally, let’s talk about regularization—a key concept in optimization that helps prevent your models from overfitting. When your model is too complex, it may perform well on training data but fail to generalize to unseen data. Regularization is the antidote.
Why Regularization is Important
Regularization works by adding a penalty term to your loss function, discouraging the model from becoming overly complex. Think of it as a way to keep your model on a leash—preventing it from fitting the noise in your data.
Types of Regularization
- L1 Regularization (Lasso): L1 regularization encourages sparsity in your model by adding the absolute value of the coefficients to the loss function. This often leads to models where some coefficients are exactly zero—effectively selecting features automatically.When to use it: L1 is great when you want to reduce the number of features or have a sparse dataset.
- L2 Regularization (Ridge): L2 regularization adds the square of the coefficients to the loss function, which prevents any individual weight from becoming too large. Unlike L1, L2 doesn’t encourage sparsity but smoothens the model.When to use it: L2 is your go-to for reducing overfitting in models with many parameters, without enforcing sparsity.
- Elastic Net: If you want the best of both worlds, Elastic Net combines L1 and L2 regularization. It’s like having a balance between encouraging sparsity (L1) and preventing large weights (L2).When to use it: When you’re unsure whether L1 or L2 will work best, or you’re dealing with high-dimensional data, Elastic Net can strike the right balance.
Hyperparameter Tuning: Optimizing the Optimization
You’ve built your machine learning model, selected your optimization algorithm, and now you’re ready to fine-tune it. But here’s the catch: every model has hyperparameters, those knobs you can twist and turn to get better results. These aren’t learned from the data, and they can make or break your model’s performance.
Hyperparameter tuning is like adjusting the gears on a bike. Sure, you can pedal, but if you don’t have the right gear for the terrain, you’ll either struggle up a hill or spin your wheels too fast. The trick is to find the sweet spot—where your model performs optimally without overfitting or underfitting.
What Are Hyperparameters?
First things first—what exactly are hyperparameters? In the context of machine learning, hyperparameters are the settings you configure before the learning process begins. Unlike the model parameters (like weights in neural networks), hyperparameters remain fixed throughout training. Examples include:
- Learning rate in gradient-based optimization algorithms.
- Batch size in mini-batch gradient descent.
- Regularization strength in models using L1/L2 penalties.
- Number of layers or neurons in a neural network.
These choices can have a huge impact on your model’s success. Too high of a learning rate, and your model overshoots the optimum. Too low, and it takes forever to converge. Too complex a model, and you risk overfitting, while too simple a model might underfit.
Why Hyperparameter Tuning is Crucial
Here’s the deal: Hyperparameter tuning allows you to squeeze the most performance out of your model. Think of it as taking an already-good car and optimizing it for a race by tuning the engine, adjusting the tires, and optimizing fuel consumption.
But you might be wondering, how do I actually tune these hyperparameters?
Popular Hyperparameter Tuning Methods
- Grid Search Grid Search is the brute-force approach. You define a grid of possible values for each hyperparameter, and the algorithm exhaustively tests every possible combination.Pros:
- Guarantees finding the best combination from the grid.
- Easy to implement and understand.
- Computationally expensive—especially for large grids or complex models.
- Doesn’t scale well to deep learning models with many hyperparameters.
- Random Search Instead of testing every possible combination, Random Search selects random combinations of hyperparameters to test. Surprisingly, random search often outperforms grid search because it explores a wider range of values, rather than testing every point in a grid that might be inefficiently spaced.Pros:
- More efficient than grid search, especially with a large hyperparameter space.
- Covers a wider range of values quickly.
- No guarantee of finding the absolute best combination.
- Requires setting an appropriate number of random samples to test.
- Bayesian Optimization Now, if you want to get fancy, Bayesian Optimization uses a probabilistic model to predict which hyperparameter values are most likely to result in better performance. It balances exploration (trying new, unexplored hyperparameter combinations) and exploitation (refining values near known good settings).Pros:
- More efficient than grid and random search because it uses prior results to inform the next trial.
- Tends to converge faster to optimal solutions.
- More complex to implement and computationally intensive.
- Requires setting up a probabilistic model (often Gaussian processes).
- Hyperband You might be thinking, “What if I don’t have the computational power for Bayesian optimization?” That’s where Hyperband comes in—a method that focuses on speeding up hyperparameter tuning by efficiently allocating resources (like training time) to the most promising hyperparameter combinations.How does it work? Hyperband starts many training runs with different hyperparameter combinations but quickly stops those that don’t seem to be performing well. It focuses its resources on the best-performing candidates.Pros:
- Much faster than traditional grid or random search because it kills poor-performing configurations early.
- Scales well with large datasets and deep learning.
- Some hyperparameters may take longer to show their true performance, so early-stopping might not always work well for certain problems.
Conclusion
So there you have it—optimization algorithms are the unsung heroes behind the scenes of machine learning, silently working to turn raw data into accurate predictions. Whether you’re dealing with gradient-based methods like Gradient Descent or more sophisticated non-gradient approaches like Genetic Algorithms and Simulated Annealing, the right choice of optimization technique can make or break your model’s performance.
Here’s what we’ve covered:
- We started with the basics of Gradient Descent and explored how its variants, like Mini-Batch and Stochastic Gradient Descent, play a role in speeding up or stabilizing training.
- We dove into advanced optimizers like Adam and RMSProp, which balance convergence speed with flexibility—particularly in complex, non-convex problems like training deep neural networks.
- Then we explored Global Optimization Algorithms, like Simulated Annealing, Genetic Algorithms, and Particle Swarm Optimization, which bring a completely different approach to finding optimal solutions in complex landscapes.
- Finally, we touched on key concepts like convex vs. non-convex optimization and the importance of regularization in ensuring that your models generalize well to new data.
Why does this matter? As a data scientist or machine learning engineer, your job is to make models that perform well—not just on paper, but in the real world. Understanding how these optimization algorithms work, when to use them, and how to tune them is crucial for building models that don’t just perform well, but excel.
Now, it’s your turn to take these insights and apply them to your own projects. Experiment with different optimization algorithms, fine-tune your hyperparameters, and keep iterating until you get the best possible performance from your models.
Remember: In machine learning, there’s no one-size-fits-all solution. The best algorithm for your model will depend on your specific problem, data, and constraints. The key is understanding the toolbox of optimization techniques available to you and knowing when to reach for each tool.
So go ahead—keep experimenting, keep learning, and continue optimizing your models to push the boundaries of what machine learning can achieve.