
Why word embeddings are critical in modern NLP tasks
Imagine you’re trying to teach a computer to understand language—seems impossible, right? That’s because computers are excellent at crunching numbers but terrible at grasping the meaning behind words. This is where word embeddings come in. They help bridge the gap between human language and machine learning by converting words into numbers that computers can understand while still preserving their meaning.
In today’s NLP landscape, word embeddings are essential because they encode the semantics of words. For instance, embeddings know that “king” and “queen” are related but different, while “king” and “man” share some gender-neutral aspects. This capability to capture meaning and context in vector form is a game-changer in NLP tasks like translation, sentiment analysis, and even text generation.
Context: Overview of NLP and the need for converting text into numerical form
You see, Natural Language Processing (NLP) is the field that deals with interactions between computers and human (natural) languages. But here’s the problem: computers don’t understand language as we do—they need numbers to perform calculations. This means that if you want to teach a machine to understand or generate text, you first have to translate those words into numbers. That’s where word embeddings come into play: they convert words into numerical vectors that a machine can process, while preserving relationships between words.
So, the key question is: how can we use Keras to implement this transformation seamlessly and efficiently?
Purpose of the Post: The role of word embeddings in deep learning and why Keras is a great library to implement them
If you’re here, you probably already know the power of deep learning and how it’s revolutionizing industries. But when it comes to working with text, word embeddings are the backbone of any good NLP model. In this post, I’ll walk you through how word embeddings work, why they are crucial for NLP, and, more importantly, how you can use Keras to implement them in your own deep learning models. Trust me, by the end of this post, you’ll feel confident enough to start incorporating embeddings into your projects.
What Are Word Embeddings?
Definition: What are word embeddings, and why are they used in machine learning?
Let’s break it down: word embeddings are vector representations of words where words with similar meanings have similar representations. Think of each word as a point in a multi-dimensional space. In this space, words that are related (like “apple” and “orange”) are close to each other, while unrelated words (like “apple” and “car”) are far apart. In simple terms, embeddings make the connections between words that you intuitively know, but in a mathematical format.
Why do we need them? Because raw text data is inherently unstructured, and machine learning models crave structure. You can’t just feed sentences directly into a model—it wouldn’t know what to do with them. Embeddings take care of this by converting words into numbers (vectors) that machines can easily interpret and use to make predictions.
Importance in NLP: The power of embeddings in capturing semantic meaning
Here’s the deal: one of the most incredible things about word embeddings is their ability to capture relationships between words. For instance, with embeddings, you can calculate that:
king – man + woman = queen
That’s right—embeddings can actually perform meaningful arithmetic on words, and this helps in various NLP tasks. You might be wondering how this is even possible. Well, word embeddings encode the “meaning” of words in such a way that similar words have similar numeric representations. This allows deep learning models to understand context, synonyms, and even analogies.
Without word embeddings, tasks like machine translation, text summarization, or sentiment analysis would be far more difficult, because there wouldn’t be a way to handle the inherent relationships between words.
Real-World Examples: Word embeddings in action
Let’s get practical. You’ve likely experienced word embeddings in your everyday life without realizing it. Think about the recommendations you get on Netflix or YouTube—embeddings are often used to understand the context of what you watch and suggest similar content. In sentiment analysis, embeddings help the model understand whether a review is positive or negative, based on the relationships between words like “amazing” and “horrible.”
Take recommendation systems for instance: when Netflix suggests a movie, it’s not just matching genres, it’s using embeddings to understand the deeper relationships between movies you’ve already watched and new ones. The same concept applies when you get suggestions on Spotify—embedding layers are working behind the scenes to find patterns in your preferences.
Introduction to Keras Embedding Layer
Overview of Keras Embedding Layer: The role of the Embedding layer
Now that you understand what word embeddings are, let’s talk about the tool that makes working with them super easy: the Keras Embedding layer. In deep learning, this layer is your go-to method for transforming input words into their corresponding embeddings.
When you’re dealing with text data, the Embedding layer takes words (which you’ve previously converted into integer indices) and turns them into dense vectors. Essentially, it’s doing the hard work of embedding the words for you.
How It Works: Converting words into dense vectors
Here’s how it works in a nutshell: the input to the Embedding layer is a list of integers, where each integer represents a specific word in your vocabulary. The output is a set of dense, fixed-size vectors for each word. You can think of these vectors as a kind of “lookup table,” where each word is associated with a unique, trainable vector.
What’s really cool is that the Embedding layer trains these vectors alongside your deep learning model. That means the embeddings get updated as the model learns, improving their ability to capture word relationships that are relevant to your specific task.
Parameters Breakdown: Input dimension, output dimension, input length, mask_zero, etc.
When you define the Embedding layer in Keras, you’ll need to specify a few key parameters:
- Input Dimension: The size of your vocabulary, i.e., how many unique words you have.
- Output Dimension: The size of the embedding vector for each word. Typically, this can range from 50 to 300, depending on your task.
- Input Length: The length of the input sequence (i.e., how many words per input).
- Mask Zero: A useful parameter if you’re working with variable-length sequences. It tells Keras to ignore the padded zeros.
For example, if you have a vocabulary of 10,000 words and you want each word to be represented by a 100-dimensional vector, you’d set input_dim=10000 and output_dim=100. If your sequences are of varying lengths and you’re padding them, you’d set mask_zero=True.
Benefits: Flexibility and simplicity of Keras
You might be thinking, why use Keras for this? Well, the Keras Embedding layer is one of the simplest ways to introduce embeddings into your model. Not only does it allow you to handle large vocabularies with ease, but it also integrates smoothly into the Keras framework, which is designed for fast prototyping and user-friendly model building.
Pre-trained Word Embeddings vs Trainable Embeddings
Pre-trained Embeddings (e.g., Word2Vec, GloVe, FastText)
Let’s start with pre-trained embeddings. These are word vectors that have been trained on massive corpora of text—think of millions of words from news articles, Wikipedia pages, or even Twitter data. Pre-trained embeddings like Word2Vec, GloVe, and FastText come with a major advantage: they’ve already “learned” the relationships between words. This means you can download them and immediately benefit from their understanding of language, without having to train from scratch.
Why are they useful?
- Faster convergence: Since the embeddings are pre-learned, your model doesn’t need to spend time learning relationships between words from scratch. It can instead focus on fine-tuning them for your specific task.
- Semantic richness: Pre-trained embeddings are excellent at capturing semantic relationships between words. For example, they inherently “know” that “dog” and “puppy” are related or that “king” and “queen” share a royal connection but differ by gender.
- Transfer learning: They allow you to leverage external knowledge from massive datasets, even if your own dataset is relatively small.
When should you use pre-trained embeddings?
- If your dataset is small, and you can’t afford to train embeddings from scratch.
- When you need embeddings that already capture general linguistic patterns.
- If the domain of your task isn’t too specialized (e.g., general news, social media, or Wikipedia articles).
Loading Pre-trained Embeddings in Keras
To use pre-trained embeddings, you typically load them as a matrix and map them to your model’s embedding layer. This lets you harness their power without needing to retrain them.
Trainable Embeddings
Now, on the flip side, you might be wondering: why bother training your own embeddings if you can just use pre-trained ones? Well, in some cases, training embeddings specific to your task or domain might outperform pre-trained vectors. For instance, if you’re working in a very niche area, like medical texts or technical documentation, pre-trained embeddings may not fully grasp the specialized relationships between words.
Why train your own embeddings?
- Task-specific optimization: Your model can learn representations that are tailor-made for the specific task you’re solving.
- Domain-specific language: If your text corpus contains a lot of specialized vocabulary, training your own embeddings can help capture those nuances better than general pre-trained embeddings.
- Flexibility: When you train your embeddings, they evolve with your model. They’re fine-tuned during training, which can lead to better performance on your specific dataset.
Comparison: Pre-trained vs Trainable Embeddings
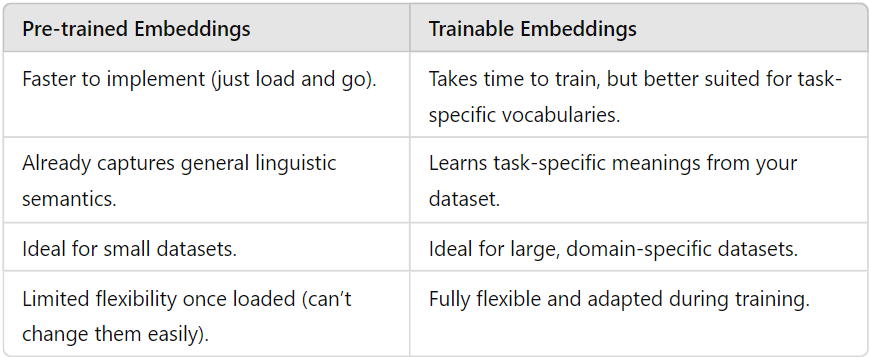
So, when should you opt for one over the other? If you’re working with general text data and need a fast solution, pre-trained embeddings are your friend. But if you’re tackling a domain-specific problem or have plenty of data, training your own embeddings might yield better results.
How to Use Word Embeddings in Keras
Let’s dive into how you can use embeddings—whether pre-trained or trainable—in Keras. I’ll walk you through each step of the process.
Step 1: Preprocessing Text Data
Before you can feed text into a model, you need to preprocess it. Here’s what you’ll typically do:
- Tokenization: You’ll convert text into sequences of integers, where each word is assigned a unique integer.
- Padding Sequences: Since your text samples might have different lengths, you’ll pad them to ensure they all have the same size.
Step 2: Creating an Embedding Layer
Once the text is preprocessed, you can set up an embedding layer. You can either:
- Use randomly initialized, trainable embeddings.
- Load pre-trained embeddings like GloVe and map them to the Keras embedding layer.
Step 3: Integrating Embeddings into a Model
Next, you’ll build a Keras model and integrate your embedding layer into it.
Step 4: Training the Model
Once your model is defined, you’ll train it on your task (e.g., sentiment analysis, text classification). You’ll need to consider factors like batch size, loss functions, and optimizers for text models.
Here’s a full code example that covers all these steps.
import numpy as np
import pandas as pd
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Dense, LSTM
from keras.optimizers import Adam
# Sample text data
texts = ["I love this product", "This is the worst thing I've ever bought", "Absolutely fantastic!", "Not worth the money"]
# Corresponding labels (0 = negative, 1 = positive)
labels = [1, 0, 1, 0]
# Step 1: Tokenize and Pad Sequences
max_vocab_size = 10000
max_seq_len = 10
tokenizer = Tokenizer(num_words=max_vocab_size)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
padded_sequences = pad_sequences(sequences, maxlen=max_seq_len)
# Step 2: Create Embedding Layer (Trainable from scratch)
embedding_dim = 100
model = Sequential()
model.add(Embedding(input_dim=max_vocab_size, output_dim=embedding_dim, input_length=max_seq_len))
# Step 3: Build the rest of the model (Using LSTM for text classification)
model.add(LSTM(64))
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(optimizer=Adam(), loss='binary_crossentropy', metrics=['accuracy'])
# Step 4: Train the model
model.fit(padded_sequences, np.array(labels), epochs=10, batch_size=2)
# Step 5: Loading Pre-trained GloVe Embeddings
# Load GloVe pre-trained vectors
embedding_index = {}
glove_file = open('glove.6B.100d.txt', encoding="utf8")
for line in glove_file:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embedding_index[word] = coefs
glove_file.close()
# Create an embedding matrix
embedding_matrix = np.zeros((len(word_index) + 1, embedding_dim))
for word, i in word_index.items():
embedding_vector = embedding_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# Replace the random Embedding layer with the pre-trained GloVe embeddings
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1,
output_dim=embedding_dim,
weights=[embedding_matrix],
input_length=max_seq_len,
trainable=False))
# Add the LSTM and Dense layers again
model.add(LSTM(64))
model.add(Dense(1, activation='sigmoid'))
# Compile and train again with pre-trained embeddings
model.compile(optimizer=Adam(), loss='binary_crossentropy', metrics=['accuracy'])
model.fit(padded_sequences, np.array(labels), epochs=10, batch_size=2)
In this example:
- We first tokenize and pad the text data to prepare it for the model.
- Next, we define a basic trainable embedding layer and train a simple LSTM model.
- Then, we load GloVe embeddings and replace the random embedding layer with pre-trained vectors.
- Finally, we compile and train the model again with the pre-trained embeddings.
Performance Considerations Pre-trained embeddings are great for quick wins and general language understanding, but they might not perform as well on highly specialized text. In domains like medical text or scientific papers, trainable embeddings often outperform pre-trained ones since they adapt directly to your data.
In short: when you have a large, domain-specific dataset, go for trainable embeddings. Otherwise, pre-trained embeddings like GloVe offer a fast and effective solution.
Conclusion
As we come to the end of this post, I hope you’re feeling more confident about incorporating word embeddings into your own deep learning projects. Whether you’re using pre-trained embeddings like GloVe or Word2Vec for quick, out-of-the-box solutions, or training your own embeddings for task-specific optimization, you now have a solid understanding of the tools available in Keras to make this process as seamless as possible.
To sum it up, here’s what you’ve learned:
- Word embeddings are a critical component of modern NLP, allowing models to understand the relationships between words in a rich and nuanced way.
- You can choose between pre-trained embeddings for faster implementation and general semantic understanding, or trainable embeddings if you want to fine-tune them for domain-specific tasks.
- Keras makes it incredibly easy to work with embeddings—whether you want to train them from scratch or integrate pre-trained vectors, you now have the tools and knowledge to do both.
Remember, embeddings are foundational in deep learning models dealing with text, but they are just the start. As you continue to experiment, you’ll discover that embeddings can be further enhanced with models like transformers and BERT, which take context understanding to the next level.
Now that you’ve mastered the basics, I encourage you to try out word embeddings in your next project. Whether you’re building a sentiment analysis model or a recommendation system, embeddings will take your model’s performance up a notch.
If you’re interested in diving deeper, explore fine-tuning techniques with embeddings or learn about contextual embeddings from models like BERT, which dynamically adjust based on the word’s context.
Stay curious, keep experimenting, and happy coding!