
You know, there’s a quote I like that goes: “The details are not the details. They make the design.” It’s a fitting metaphor for neural networks too. In deep learning, activation functions are those subtle yet powerful “details” that can make or break your model’s performance. Without them, your neural network would be like an orchestra without instruments—structured, but silent and ineffective.
Why Are Activation Functions So Critical?
So, why should you care about activation functions in deep learning? Here’s the deal: they’re the key to how a neural network learns. Without them, no matter how sophisticated your model architecture is, it wouldn’t be able to handle complex tasks like recognizing objects in an image or understanding natural language.
Think of activation functions like filters in a photo editor. Just as a filter transforms an image, an activation function transforms the raw data that flows through your network. It helps your model capture intricate patterns and relationships in data—turning simple inputs into meaningful outputs. The choice of activation function can impact whether your model converges fast or slow, whether it learns efficiently or struggles. You can’t afford to overlook this.
Purpose of the Article
In this blog, I’m going to walk you through everything you need to know about activation functions, breaking down the strengths, weaknesses, and use cases of the most popular ones. Whether you’re working on a basic binary classification task or crafting an intricate deep learning model, you’ll have a clear idea of which activation function to use, and most importantly, why.
What You’ll Learn
By the time we’re done, you’ll understand:
- The different types of activation functions out there, from the classic Sigmoid and ReLU to modern advancements like Swish.
- When to use each one (because, let’s face it, blindly using ReLU everywhere might not always be your best bet).
- The common pitfalls to avoid and how the right choice of activation function can optimize your model’s performance for specific tasks.
Let’s get started. Trust me, after reading this, your deep learning models will thank you.
What is an Activation Function?
Definition
Here’s a simple analogy to start with: Imagine your neural network as a decision-making tree. You feed in data at the roots, and as it flows through the branches, it needs to make choices at each node. Now, without an activation function, these decisions would be linear, kind of like following a straight road with no twists or turns. Doesn’t sound too effective for complex tasks, right?
An activation function is the mechanism that allows your neural network to take the scenic route—it introduces the twists and turns, making the decisions more nuanced and intelligent. Simply put, it determines whether a neuron in the network should be activated (or “fired”) based on the input it receives. If we left everything as linear transformations, your neural network wouldn’t be much smarter than a basic linear model, no matter how many layers it had. The magic happens when we introduce non-linearity—that’s where activation functions shine.
Role in Neural Networks
You might be wondering: Why is non-linearity such a big deal?
Here’s the deal: real-world data is rarely linear. Whether you’re classifying images, predicting stock prices, or generating text, the relationships between your input data points are often incredibly complex. Without non-linearity, your model simply won’t be able to capture these relationships effectively.
For example, if you’re trying to classify images of cats and dogs, a linear model could only draw straight-line boundaries between the two categories, which is obviously not enough. But when you introduce an activation function, your model can draw those complex, curvy boundaries that better separate your data.
In short, activation functions let your neural network learn and adapt to complex patterns in the data. Without them, you’d be stuck with a model that just can’t handle the real world.
Mathematical Insight
Now, let’s get a little technical, but don’t worry—I’ll keep it simple.
At its core, an activation function takes the weighted sum of inputs to a neuron and transforms it into an output. Mathematically, if the input to a neuron is zzz (which is just the weighted sum of inputs plus a bias), the activation function f(z)f(z)f(z) transforms that value.
For example, in the simplest case, the sigmoid activation function transforms zzz using the following formula:

What this means is that no matter how large or small the input zzz, the sigmoid function will squash it into a value between 0 and 1. This allows the neuron to make a binary decision, firing (closer to 1) or staying inactive (closer to 0). Other functions, like ReLU (Rectified Linear Unit), use a different approach by simply outputting zzz if it’s positive, and 0 otherwise:f(z)=max(0,z)f(z) = \max(0, z)f(z)=max(0,z)
This might surprise you, but such a simple function has revolutionized deep learning because it’s computationally efficient and avoids some common pitfalls, like the vanishing gradient problem (we’ll dive into that later).
Types of Activation Functions
1. Linear Activation Function
Definition & Formula
Let’s kick off with the simplest: the linear activation function. You might recognize it from basic math as f(x)=ax+bf(x) = ax + bf(x)=ax+b. In deep learning terms, the output of the neuron is just a weighted sum of the inputs—no fancy transformation here.
Use Case
This might surprise you, but linear activation functions are rarely used in hidden layers of neural networks. Why? Because they don’t introduce any complexity. However, you might see them in the output layer for tasks like regression, where the goal is to predict continuous values.
Drawbacks
Here’s the deal: linear functions don’t add any non-linearity, and without non-linearity, no matter how deep your network is, it behaves like a single-layer model. It can only learn linear relationships, which isn’t what you want when dealing with complex data like images or language.
2. Non-Linear Activation Functions
Now, let’s dive into where things get exciting—non-linear activation functions. These are the backbone of modern deep learning because they introduce that much-needed complexity, allowing your model to capture intricate patterns in the data.
Sigmoid Function
Explanation & Formula
The sigmoid function is one of the classics, transforming inputs into a value between 0 and 1 using this formula:
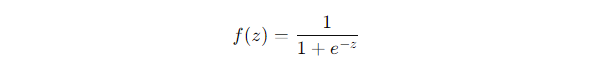
It’s like turning the volume dial on a stereo, where the input values are squeezed into a soft range, making it perfect for binary classification tasks.
Advantages
Sigmoid is ideal when you need probabilistic outputs, like predicting whether an email is spam or not. It squashes any input into a value between 0 and 1, which you can then interpret as a probability.
Drawbacks
You might be wondering, if it’s so great, why not use it everywhere? Well, sigmoid has its dark side. It suffers from something called the vanishing gradient problem—when inputs are too large or too small, the function flattens out, causing gradients to approach zero during backpropagation. This slows down learning, especially in deeper networks.
Use Cases
Despite its issues, sigmoid is still widely used in the output layer for binary classification tasks. Think logistic regression—it’s the go-to for two-class problems where you need to output probabilities.
Tanh (Hyperbolic Tangent)
Explanation & Formula
Next up is tanh, a close cousin of sigmoid, but it outputs values between -1 and 1: f(z)=tanh(z)
If sigmoid is like a volume dial, tanh is more like a balance scale, pushing positive and negative inputs to stronger extremes.
Advantages
Here’s where tanh has an edge: its output is zero-centered, meaning the negative values are more pronounced, which helps gradients flow more smoothly during training, especially in deeper networks.
Drawbacks
However, like its cousin, tanh isn’t immune to the vanishing gradient problem. As the inputs become too large, the function saturates, making learning slow.
Use Cases
Because tanh is zero-centered, it’s often used in hidden layers, particularly in networks where you want a more balanced output. It’s a solid choice when you’re looking for something more robust than sigmoid but still simple.
ReLU (Rectified Linear Unit)
Explanation & Formula
Now let’s talk about the activation function that took the deep learning world by storm: ReLU. The formula couldn’t be simpler:f(z)=max(0,z)
In other words, if the input is positive, it passes through unchanged; if it’s negative, it’s set to zero. No squashing, no fancy curves—just raw, computational efficiency.
Advantages
ReLU’s main claim to fame is that it solves the vanishing gradient problem. Because ReLU doesn’t squash large values, gradients don’t get stuck, allowing for faster learning. Plus, ReLU introduces sparsity—meaning many neurons in the network are inactive, which can improve computational efficiency.
Drawbacks
But ReLU isn’t without flaws. You might have heard of the dying ReLU problem, where neurons can get stuck in an inactive state if their input is always negative. Once a neuron “dies,” it never activates again, which can hurt your model’s performance.
Use Cases
Despite its drawbacks, ReLU is the default activation function for most modern deep learning architectures, from CNNs (convolutional neural networks) to MLPs (multi-layer perceptrons). If you’re building any deep learning model, chances are you’ll be using ReLU in your hidden layers.
Leaky ReLU / Parametric ReLU
Explanation & Formula
To address the dying ReLU problem, we have Leaky ReLU, which modifies the original by allowing a small, non-zero slope for negative inputs:f(z)=z if z>0, otherwise f(z)=αzf(z) = z , otherwise f(z)=αz
Here, α\alphaα is a small constant (like 0.01), allowing some negative values to pass through instead of zeroing them out. Parametric ReLU takes this a step further by making α\alphaα a learnable parameter.
Advantages
Leaky ReLU prevents neurons from “dying,” ensuring that all neurons can potentially contribute during training, especially in deeper layers.
Drawbacks
The main drawback is the extra hyperparameter (or learnable parameter in the case of parametric ReLU), which adds complexity to your model. This might not always be necessary depending on your dataset and task.
Use Cases
You’ll often find Leaky ReLU or Parametric ReLU in deep networks where the dying ReLU issue is more prominent. It’s a handy fix for networks that go beyond a few layers.
Softmax Function
Explanation & Formula
Next, we have Softmax, which is a bit different from the others because it’s typically used in the output layer for multi-class classification tasks. Softmax converts raw class scores (logits) into a probability distribution:

In simple terms, it takes the raw output of a model and normalizes it into a range of [0, 1], where all the probabilities sum to 1.
Advantages
Softmax is perfect for tasks like classifying images into categories (cat, dog, car, etc.) because it gives you a clear probabilistic output for each class.
Drawbacks
The downside? Softmax can be computationally expensive, especially when you have a large number of classes, because it requires normalizing the outputs.
Use Cases
You’ll see Softmax in the output layer of most multi-class classification models, from simple image classifiers to more complex natural language processing tasks.
Swish Function
Explanation & Formula
Last but certainly not least, we have Swish—a modern activation function developed by Google. It’s a bit more sophisticated, combining elements of sigmoid and identity:
f(z)=z⋅σ(z)
Where σ(z)\sigma(z)σ(z) is the sigmoid function. Swish is unique in that it’s self-gating, meaning it adapts based on the input.
Advantages
Swish is smooth and non-monotonic, which means it can outperform ReLU in certain deep networks. It’s been shown to improve performance in state-of-the-art models like EfficientNet.
Drawbacks
The only real drawback is that it’s slightly more computationally expensive than ReLU. But if you’re pushing for top-tier performance, this trade-off might be worth it.
Use Cases
Swish is used in cutting-edge architectures, especially when maximum performance is key. If you’re looking to experiment with more modern techniques, Swish is a solid option to explore.
Comparing Activation Functions: How to Choose the Right One
Choosing the right activation function isn’t a one-size-fits-all situation. It’s kind of like choosing the right tool for the job—each function has its strengths and weaknesses, and understanding the trade-offs will help you make the right call. Let’s break it down.
Understanding the Trade-offs
Simplicity vs. Complexity
You might be thinking: Why not just use ReLU everywhere?
Here’s the thing—ReLU is a simple and computationally efficient function. Its mathematical simplicity makes it the go-to choice for most deep learning models. Since ReLU doesn’t involve expensive operations like exponentials or divisions (unlike sigmoid or tanh), it speeds up training time. If you’re working with large datasets or deep networks, this speed boost can make a big difference.
But simplicity comes at a cost. ReLU can sometimes fail in specific scenarios—particularly when dealing with the dying ReLU problem. If a large portion of your network’s neurons end up stuck with negative inputs (outputting zero), they stop learning, and you lose valuable information. In these cases, more complex variants like Leaky ReLU or Swish might save the day by allowing a small gradient flow even for negative values.
Speed vs. Accuracy
Now, let’s talk about speed vs. accuracy—two factors that are constantly at odds in deep learning.
For instance, while ReLU is faster, it might not always give you the highest accuracy, especially in complex architectures. Enter Swish, which is known for its smooth, non-monotonic nature. Swish can provide better accuracy at the expense of slightly slower training because it involves more complex calculations (remember the self-gating mechanism: f(z)=z⋅σ(z)f(z) = z \cdot \sigma(z)f(z)=z⋅σ(z)).
Think of it this way: If ReLU is like driving on a highway at full speed, Swish is like taking a scenic route—it takes longer, but you might end up with a better overall experience (i.e., higher accuracy in your model). So, the trade-off depends on whether your priority is speed or squeezing every bit of performance out of your model.
Use Case-Based Selection
Task Specificity
The activation function you choose should depend heavily on the task you’re tackling. Let me give you a few examples:
- Binary Classification: If you’re working on a binary classification task (like predicting whether an email is spam), you’ll likely want to use sigmoid in the output layer. Why? Because sigmoid maps the output between 0 and 1, which makes it perfect for probabilistic interpretation—just what you need for binary decisions.
- Multi-Class Classification: In multi-class problems, where you’re choosing between several categories (like classifying an image as a cat, dog, or car), the softmax function in the output layer is your best friend. It converts raw scores (logits) into probabilities for each class.
- Regression: For continuous value prediction tasks like regression, you’ll likely need a linear activation function in the output layer. But in the hidden layers, functions like ReLU can still be useful for capturing non-linearity in your data.
Architecture Specificity
Now, let’s talk about architectures. Different activation functions play better in different types of neural networks:
- CNNs (Convolutional Neural Networks): These networks, commonly used for image processing, typically favor ReLU or Leaky ReLU. CNNs benefit from ReLU’s ability to introduce sparsity (many neurons output zero), which helps filter out unnecessary features.
- RNNs (Recurrent Neural Networks): When it comes to sequential data like text or time-series data, tanh and sigmoid are often preferred. Why? Because they can handle temporal dependencies better by keeping the range of the output within -1 to 1 (tanh) or 0 to 1 (sigmoid), which prevents exploding values in long sequences.
- Transformers: In modern architectures like Transformers, ReLU or gelu (Gaussian Error Linear Unit) are often used in the feedforward layers. These architectures rely on attention mechanisms, and ReLU’s efficiency keeps things moving smoothly through the layers.
Depth of the Network
Deeper networks generally need activation functions that handle vanishing gradients better. For networks with many layers, ReLU and its variants (like Leaky ReLU or Parametric ReLU) are commonly used because they help prevent gradients from shrinking to zero during backpropagation.
On the other hand, in shallow networks, where vanishing gradients aren’t as much of a concern, you might find simpler activation functions like sigmoid or tanh doing just fine. In fact, tanh can sometimes outperform ReLU in shallower architectures because it gives a more balanced output.
Empirical Testing
You might be wondering: Which activation function should I pick for my model?
Here’s my advice: experiment. There’s no magic bullet when it comes to activation functions. The “best” function often depends on your specific dataset and architecture. I’ve seen cases where ReLU outperformed Swish on one dataset, but Swish dominated on another.
Start with a default like ReLU, but don’t be afraid to try others like Swish, Leaky ReLU, or even new experimental ones. Deep learning is part science, part art—you have to experiment with different functions to see what works best for your task.
And that’s how you approach selecting an activation function—balancing simplicity, speed, task specificity, and architecture demands. Ready to test different functions in your next model? Trust me, the right choice can significantly impact your results.